 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlgorithmic warm starts for Hamiltonian Monte Carlo
Mar 24, 2026Generating samples from a continuous probability density is a central algorithmic problem across statistics, engineering, and the sciences. For high-dimensional settings, Hamiltonian Monte Carlo (HMC) is the default algorithm across mainstream software packages. However, despite the extensive line of work on HMC and its widespread empirical success, it remains unclear how many iterations of HMC are required as a function of the dimension $d$. On one hand, a variety of results show that Metropolized HMC converges in $O(d^{1/4})$ iterations from a warm start close to stationarity. On the other hand, Metropolized HMC is significantly slower without a warm start, e.g., requiring $Ω(d^{1/2})$ iterations even for simple target distributions such as isotropic Gaussians. Finding a warm start is therefore the computational bottleneck for HMC. We resolve this issue for the well-studied setting of sampling from a probability distribution satisfying strong log-concavity (or isoperimetry) and third-order derivative bounds. We prove that \emph{non-Metropolized} HMC generates a warm start in $\tilde{O}(d^{1/4})$ iterations, after which we can exploit the warm start using Metropolized HMC. Our final complexity of $\tilde{O}(d^{1/4})$ is the fastest algorithm for high-accuracy sampling under these assumptions, improving over the prior best of $\tilde{O}(d^{1/2})$. This closes the long line of work on the dimensional complexity of MHMC for such settings, and also provides a simple warm-start prescription for practical implementations.
Sampling from Constrained Gibbs Measures: with Applications to High-Dimensional Bayesian Inference
Feb 25, 2026This paper considers a non-standard problem of generating samples from a low-temperature Gibbs distribution with \emph{constrained} support, when some of the coordinates of the mode lie on the boundary. These coordinates are referred to as the non-regular part of the model. We show that in a ``pre-asymptotic'' regime in which the limiting Laplace approximation is not yet valid, the low-temperature Gibbs distribution concentrates on a neighborhood of its mode. Within this region, the distribution is a bounded perturbation of a product measure: a strongly log-concave distribution in the regular part and a one-dimensional exponential-type distribution in each coordinate of the non-regular part. Leveraging this structure, we provide a non-asymptotic sampling guarantee by analyzing the spectral gap of Langevin dynamics. Key examples of low-temperature Gibbs distributions include Bayesian posteriors, and we demonstrate our results on three canonical examples: a high-dimensional logistic regression model, a Poisson linear model, and a Gaussian mixture model.
Variational inference via radial transport
Feb 19, 2026In variational inference (VI), the practitioner approximates a high-dimensional distribution $π$ with a simple surrogate one, often a (product) Gaussian distribution. However, in many cases of practical interest, Gaussian distributions might not capture the correct radial profile of $π$, resulting in poor coverage. In this work, we approach the VI problem from the perspective of optimizing over these radial profiles. Our algorithm radVI is a cheap, effective add-on to many existing VI schemes, such as Gaussian (mean-field) VI and Laplace approximation. We provide theoretical convergence guarantees for our algorithm, owing to recent developments in optimization over the Wasserstein space--the space of probability distributions endowed with the Wasserstein distance--and new regularity properties of radial transport maps in the style of Caffarelli (2000).
High-accuracy log-concave sampling with stochastic queries
Feb 15, 2026We show that high-accuracy guarantees for log-concave sampling -- that is, iteration and query complexities which scale as $\mathrm{poly}\log(1/δ)$, where $δ$ is the desired target accuracy -- are achievable using stochastic gradients with subexponential tails. Notably, this exhibits a separation with the problem of convex optimization, where stochasticity (even additive Gaussian noise) in the gradient oracle incurs $\mathrm{poly}(1/δ)$ queries. We also give an information-theoretic argument that light-tailed stochastic gradients are necessary for high accuracy: for example, in the bounded variance case, we show that the minimax-optimal query complexity scales as $Θ(1/δ)$. Our framework also provides similar high accuracy guarantees under stochastic zeroth order (value) queries.
Blind denoising diffusion models and the blessings of dimensionality
Feb 10, 2026We analyze, theoretically and empirically, the performance of generative diffusion models based on \emph{blind denoisers}, in which the denoiser is not given the noise amplitude in either the training or sampling processes. Assuming that the data distribution has low intrinsic dimensionality, we prove that blind denoising diffusion models (BDDMs), despite not having access to the noise amplitude, \emph{automatically} track a particular \emph{implicit} noise schedule along the reverse process. Our analysis shows that BDDMs can accurately sample from the data distribution in polynomially many steps as a function of the intrinsic dimension. Empirical results corroborate these mathematical findings on both synthetic and image data, demonstrating that the noise variance is accurately estimated from the noisy image. Remarkably, we observe that schedule-free BDDMs produce samples of higher quality compared to their non-blind counterparts. We provide evidence that this performance gain arises because BDDMs correct the mismatch between the true residual noise (of the image) and the noise assumed by the schedule used in non-blind diffusion models.
High-accuracy sampling for diffusion models and log-concave distributions
Feb 01, 2026We present algorithms for diffusion model sampling which obtain $δ$-error in $\mathrm{polylog}(1/δ)$ steps, given access to $\widetilde O(δ)$-accurate score estimates in $L^2$. This is an exponential improvement over all previous results. Specifically, under minimal data assumptions, the complexity is $\widetilde O(d\,\mathrm{polylog}(1/δ))$ where $d$ is the dimension of the data; under a non-uniform $L$-Lipschitz condition, the complexity is $\widetilde O(\sqrt{dL}\,\mathrm{polylog}(1/δ))$; and if the data distribution has intrinsic dimension $d_\star$, then the complexity reduces to $\widetilde O(d_\star\,\mathrm{polylog}(1/δ))$. Our approach also yields the first $\mathrm{polylog}(1/δ)$ complexity sampler for general log-concave distributions using only gradient evaluations.
Rod Flow: A Continuous-Time Model for Gradient Descent at the Edge of Stability
Feb 01, 2026How can we understand gradient-based training over non-convex landscapes? The edge of stability phenomenon, introduced in Cohen et al. (2021), indicates that the answer is not so simple: namely, gradient descent (GD) with large step sizes often diverges away from the gradient flow. In this regime, the "Central Flow", recently proposed in Cohen et al. (2025), provides an accurate ODE approximation to the GD dynamics over many architectures. In this work, we propose Rod Flow, an alternative ODE approximation, which carries the following advantages: (1) it rests on a principled derivation stemming from a physical picture of GD iterates as an extended one-dimensional object -- a "rod"; (2) it better captures GD dynamics for simple toy examples and matches the accuracy of Central Flow for representative neural network architectures, and (3) is explicit and cheap to compute. Theoretically, we prove that Rod Flow correctly predicts the critical sharpness threshold and explains self-stabilization in quartic potentials. We validate our theory with a range of numerical experiments.
Theory and computation for structured variational inference
Nov 13, 2025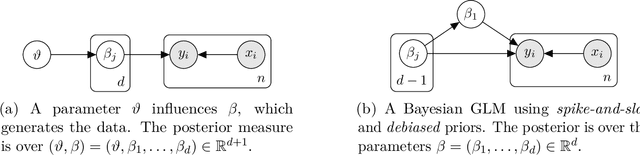
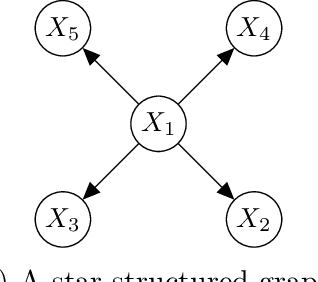
Structured variational inference constitutes a core methodology in modern statistical applications. Unlike mean-field variational inference, the approximate posterior is assumed to have interdependent structure. We consider the natural setting of star-structured variational inference, where a root variable impacts all the other ones. We prove the first results for existence, uniqueness, and self-consistency of the variational approximation. In turn, we derive quantitative approximation error bounds for the variational approximation to the posterior, extending prior work from the mean-field setting to the star-structured setting. We also develop a gradient-based algorithm with provable guarantees for computing the variational approximation using ideas from optimal transport theory. We explore the implications of our results for Gaussian measures and hierarchical Bayesian models, including generalized linear models with location family priors and spike-and-slab priors with one-dimensional debiasing. As a by-product of our analysis, we develop new stability results for star-separable transport maps which might be of independent interest.
Sublinear iterations can suffice even for DDPMs
Nov 06, 2025SDE-based methods such as denoising diffusion probabilistic models (DDPMs) have shown remarkable success in real-world sample generation tasks. Prior analyses of DDPMs have been focused on the exponential Euler discretization, showing guarantees that generally depend at least linearly on the dimension or initial Fisher information. Inspired by works in log-concave sampling (Shen and Lee, 2019), we analyze an integrator -- the denoising diffusion randomized midpoint method (DDRaM) -- that leverages an additional randomized midpoint to better approximate the SDE. Using a recently-developed analytic framework called the "shifted composition rule", we show that this algorithm enjoys favorable discretization properties under appropriate smoothness assumptions, with sublinear $\widetilde{O}(\sqrt{d})$ score evaluations needed to ensure convergence. This is the first sublinear complexity bound for pure DDPM sampling -- prior works which obtained such bounds worked instead with ODE-based sampling and had to make modifications to the sampler which deviate from how they are used in practice. We also provide experimental validation of the advantages of our method, showing that it performs well in practice with pre-trained image synthesis models.
Gaussian mixture layers for neural networks
Aug 06, 2025The mean-field theory for two-layer neural networks considers infinitely wide networks that are linearly parameterized by a probability measure over the parameter space. This nonparametric perspective has significantly advanced both the theoretical and conceptual understanding of neural networks, with substantial efforts made to validate its applicability to networks of moderate width. In this work, we explore the opposite direction, investigating whether dynamics can be directly implemented over probability measures. Specifically, we employ Gaussian mixture models as a flexible and expressive parametric family of distributions together with the theory of Wasserstein gradient flows to derive training dynamics for such measures. Our approach introduces a new type of layer -- the Gaussian mixture (GM) layer -- that can be integrated into neural network architectures. As a proof of concept, we validate our proposal through experiments on simple classification tasks, where a GM layer achieves test performance comparable to that of a two-layer fully connected network. Furthermore, we examine the behavior of these dynamics and demonstrate numerically that GM layers exhibit markedly different behavior compared to classical fully connected layers, even when the latter are large enough to be considered in the mean-field regime.