 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSample-Adaptivity Tradeoff in On-Demand Sampling
Nov 19, 2025We study the tradeoff between sample complexity and round complexity in on-demand sampling, where the learning algorithm adaptively samples from $k$ distributions over a limited number of rounds. In the realizable setting of Multi-Distribution Learning (MDL), we show that the optimal sample complexity of an $r$-round algorithm scales approximately as $dk^{Θ(1/r)} / ε$. For the general agnostic case, we present an algorithm that achieves near-optimal sample complexity of $\widetilde O((d + k) / ε^2)$ within $\widetilde O(\sqrt{k})$ rounds. Of independent interest, we introduce a new framework, Optimization via On-Demand Sampling (OODS), which abstracts the sample-adaptivity tradeoff and captures most existing MDL algorithms. We establish nearly tight bounds on the round complexity in the OODS setting. The upper bounds directly yield the $\widetilde O(\sqrt{k})$-round algorithm for agnostic MDL, while the lower bounds imply that achieving sub-polynomial round complexity would require fundamentally new techniques that bypass the inherent hardness of OODS.
CoT Information: Improved Sample Complexity under Chain-of-Thought Supervision
May 21, 2025
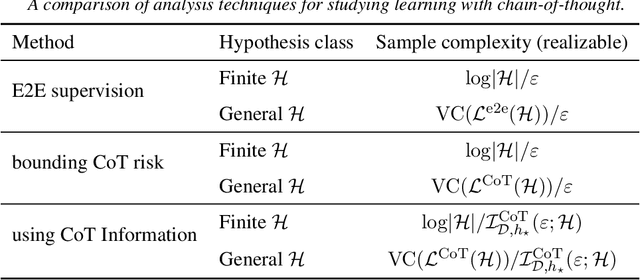
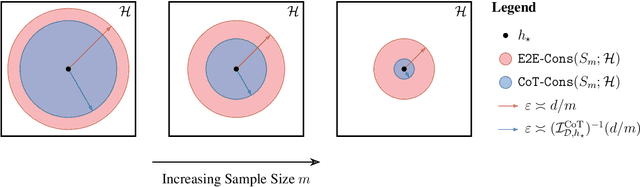

Learning complex functions that involve multi-step reasoning poses a significant challenge for standard supervised learning from input-output examples. Chain-of-thought (CoT) supervision, which provides intermediate reasoning steps together with the final output, has emerged as a powerful empirical technique, underpinning much of the recent progress in the reasoning capabilities of large language models. This paper develops a statistical theory of learning under CoT supervision. A key characteristic of the CoT setting, in contrast to standard supervision, is the mismatch between the training objective (CoT risk) and the test objective (end-to-end risk). A central part of our analysis, distinguished from prior work, is explicitly linking those two types of risk to achieve sharper sample complexity bounds. This is achieved via the *CoT information measure* $\mathcal{I}_{\mathcal{D}, h_\star}^{\mathrm{CoT}}(\epsilon; \calH)$, which quantifies the additional discriminative power gained from observing the reasoning process. The main theoretical results demonstrate how CoT supervision can yield significantly faster learning rates compared to standard E2E supervision. Specifically, it is shown that the sample complexity required to achieve a target E2E error $\epsilon$ scales as $d/\mathcal{I}_{\mathcal{D}, h_\star}^{\mathrm{CoT}}(\epsilon; \calH)$, where $d$ is a measure of hypothesis class complexity, which can be much faster than standard $d/\epsilon$ rates. Information-theoretic lower bounds in terms of the CoT information are also obtained. Together, these results suggest that CoT information is a fundamental measure of statistical complexity for learning under chain-of-thought supervision.
(Im)possibility of Automated Hallucination Detection in Large Language Models
Apr 23, 2025Is automated hallucination detection possible? In this work, we introduce a theoretical framework to analyze the feasibility of automatically detecting hallucinations produced by large language models (LLMs). Inspired by the classical Gold-Angluin framework for language identification and its recent adaptation to language generation by Kleinberg and Mullainathan, we investigate whether an algorithm, trained on examples drawn from an unknown target language $K$ (selected from a countable collection) and given access to an LLM, can reliably determine whether the LLM's outputs are correct or constitute hallucinations. First, we establish an equivalence between hallucination detection and the classical task of language identification. We prove that any hallucination detection method can be converted into a language identification method, and conversely, algorithms solving language identification can be adapted for hallucination detection. Given the inherent difficulty of language identification, this implies that hallucination detection is fundamentally impossible for most language collections if the detector is trained using only correct examples from the target language. Second, we show that the use of expert-labeled feedback, i.e., training the detector with both positive examples (correct statements) and negative examples (explicitly labeled incorrect statements), dramatically changes this conclusion. Under this enriched training regime, automated hallucination detection becomes possible for all countable language collections. These results highlight the essential role of expert-labeled examples in training hallucination detectors and provide theoretical support for feedback-based methods, such as reinforcement learning with human feedback (RLHF), which have proven critical for reliable LLM deployment.
Beyond Worst-Case Online Classification: VC-Based Regret Bounds for Relaxed Benchmarks
Apr 14, 2025We revisit online binary classification by shifting the focus from competing with the best-in-class binary loss to competing against relaxed benchmarks that capture smoothed notions of optimality. Instead of measuring regret relative to the exact minimal binary error -- a standard approach that leads to worst-case bounds tied to the Littlestone dimension -- we consider comparing with predictors that are robust to small input perturbations, perform well under Gaussian smoothing, or maintain a prescribed output margin. Previous examples of this were primarily limited to the hinge loss. Our algorithms achieve regret guarantees that depend only on the VC dimension and the complexity of the instance space (e.g., metric entropy), and notably, they incur only an $O(\log(1/\gamma))$ dependence on the generalized margin $\gamma$. This stands in contrast to most existing regret bounds, which typically exhibit a polynomial dependence on $1/\gamma$. We complement this with matching lower bounds. Our analysis connects recent ideas from adversarial robustness and smoothed online learning.
DDPM Score Matching and Distribution Learning
Apr 07, 2025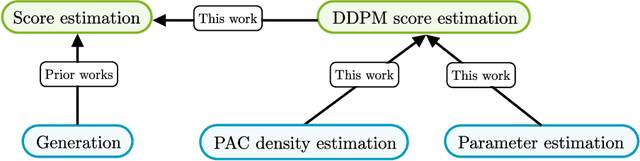
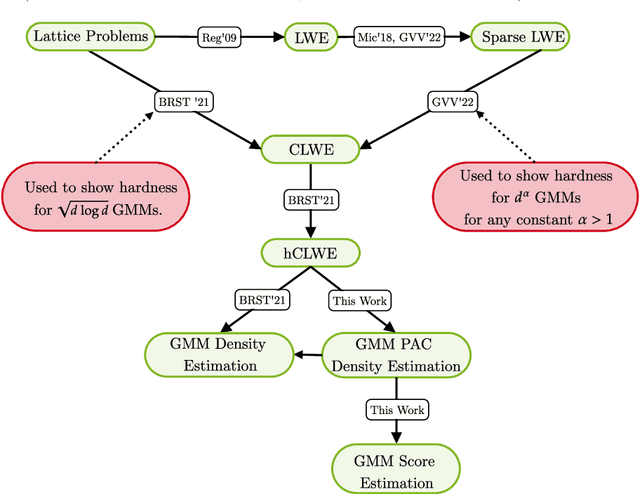
Score estimation is the backbone of score-based generative models (SGMs), especially denoising diffusion probabilistic models (DDPMs). A key result in this area shows that with accurate score estimates, SGMs can efficiently generate samples from any realistic data distribution (Chen et al., ICLR'23; Lee et al., ALT'23). This distribution learning result, where the learned distribution is implicitly that of the sampler's output, does not explain how score estimation relates to classical tasks of parameter and density estimation. This paper introduces a framework that reduces score estimation to these two tasks, with various implications for statistical and computational learning theory: Parameter Estimation: Koehler et al. (ICLR'23) demonstrate that a score-matching variant is statistically inefficient for the parametric estimation of multimodal densities common in practice. In contrast, we show that under mild conditions, denoising score-matching in DDPMs is asymptotically efficient. Density Estimation: By linking generation to score estimation, we lift existing score estimation guarantees to $(\epsilon,\delta)$-PAC density estimation, i.e., a function approximating the target log-density within $\epsilon$ on all but a $\delta$-fraction of the space. We provide (i) minimax rates for density estimation over H\"older classes and (ii) a quasi-polynomial PAC density estimation algorithm for the classical Gaussian location mixture model, building on and addressing an open problem from Gatmiry et al. (arXiv'24). Lower Bounds for Score Estimation: Our framework offers the first principled method to prove computational lower bounds for score estimation across general distributions. As an application, we establish cryptographic lower bounds for score estimation in general Gaussian mixture models, conceptually recovering Song's (NeurIPS'24) result and advancing his key open problem.
Transformation-Invariant Learning and Theoretical Guarantees for OOD Generalization
Oct 30, 2024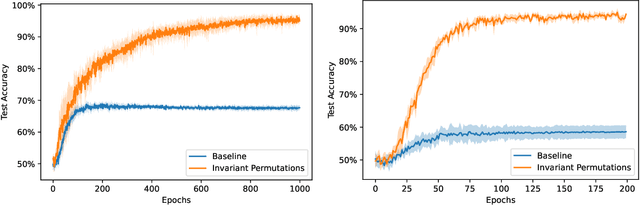
Learning with identical train and test distributions has been extensively investigated both practically and theoretically. Much remains to be understood, however, in statistical learning under distribution shifts. This paper focuses on a distribution shift setting where train and test distributions can be related by classes of (data) transformation maps. We initiate a theoretical study for this framework, investigating learning scenarios where the target class of transformations is either known or unknown. We establish learning rules and algorithmic reductions to Empirical Risk Minimization (ERM), accompanied with learning guarantees. We obtain upper bounds on the sample complexity in terms of the VC dimension of the class composing predictors with transformations, which we show in many cases is not much larger than the VC dimension of the class of predictors. We highlight that the learning rules we derive offer a game-theoretic viewpoint on distribution shift: a learner searching for predictors and an adversary searching for transformation maps to respectively minimize and maximize the worst-case loss.
Derandomizing Multi-Distribution Learning
Sep 26, 2024Multi-distribution or collaborative learning involves learning a single predictor that works well across multiple data distributions, using samples from each during training. Recent research on multi-distribution learning, focusing on binary loss and finite VC dimension classes, has shown near-optimal sample complexity that is achieved with oracle efficient algorithms. That is, these algorithms are computationally efficient given an efficient ERM for the class. Unlike in classical PAC learning, where the optimal sample complexity is achieved with deterministic predictors, current multi-distribution learning algorithms output randomized predictors. This raises the question: can these algorithms be derandomized to produce a deterministic predictor for multiple distributions? Through a reduction to discrepancy minimization, we show that derandomizing multi-distribution learning is computationally hard, even when ERM is computationally efficient. On the positive side, we identify a structural condition enabling an efficient black-box reduction, converting existing randomized multi-distribution predictors into deterministic ones.
Theoretical Foundations of Adversarially Robust Learning
Jun 13, 2023


Despite extraordinary progress, current machine learning systems have been shown to be brittle against adversarial examples: seemingly innocuous but carefully crafted perturbations of test examples that cause machine learning predictors to misclassify. Can we learn predictors robust to adversarial examples? and how? There has been much empirical interest in this contemporary challenge in machine learning, and in this thesis, we address it from a theoretical perspective. In this thesis, we explore what robustness properties can we hope to guarantee against adversarial examples and develop an understanding of how to algorithmically guarantee them. We illustrate the need to go beyond traditional approaches and principles such as empirical risk minimization and uniform convergence, and make contributions that can be categorized as follows: (1) introducing problem formulations capturing aspects of emerging practical challenges in robust learning, (2) designing new learning algorithms with provable robustness guarantees, and (3) characterizing the complexity of robust learning and fundamental limitations on the performance of any algorithm.
Strategic Classification under Unknown Personalized Manipulation
May 25, 2023
We study the fundamental mistake bound and sample complexity in the strategic classification, where agents can strategically manipulate their feature vector up to an extent in order to be predicted as positive. For example, given a classifier determining college admission, student candidates may try to take easier classes to improve their GPA, retake SAT and change schools in an effort to fool the classifier. Ball manipulations are a widely studied class of manipulations in the literature, where agents can modify their feature vector within a bounded radius ball. Unlike most prior work, our work considers manipulations to be personalized, meaning that agents can have different levels of manipulation abilities (e.g., varying radii for ball manipulations), and unknown to the learner. We formalize the learning problem in an interaction model where the learner first deploys a classifier and the agent manipulates the feature vector within their manipulation set to game the deployed classifier. We investigate various scenarios in terms of the information available to the learner during the interaction, such as observing the original feature vector before or after deployment, observing the manipulated feature vector, or not seeing either the original or the manipulated feature vector. We begin by providing online mistake bounds and PAC sample complexity in these scenarios for ball manipulations. We also explore non-ball manipulations and show that, even in the simplest scenario where both the original and the manipulated feature vectors are revealed, the mistake bounds and sample complexity are lower bounded by $\Omega(|\mathcal{H}|)$ when the target function belongs to a known class $\mathcal{H}$.
Certifiable (Multi)Robustness Against Patch Attacks Using ERM
Mar 15, 2023
Consider patch attacks, where at test-time an adversary manipulates a test image with a patch in order to induce a targeted misclassification. We consider a recent defense to patch attacks, Patch-Cleanser (Xiang et al. [2022]). The Patch-Cleanser algorithm requires a prediction model to have a ``two-mask correctness'' property, meaning that the prediction model should correctly classify any image when any two blank masks replace portions of the image. Xiang et al. learn a prediction model to be robust to two-mask operations by augmenting the training set with pairs of masks at random locations of training images and performing empirical risk minimization (ERM) on the augmented dataset. However, in the non-realizable setting when no predictor is perfectly correct on all two-mask operations on all images, we exhibit an example where ERM fails. To overcome this challenge, we propose a different algorithm that provably learns a predictor robust to all two-mask operations using an ERM oracle, based on prior work by Feige et al. [2015]. We also extend this result to a multiple-group setting, where we can learn a predictor that achieves low robust loss on all groups simultaneously.