 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentially Private Language Generation and Identification in the Limit
Apr 09, 2026We initiate the study of language generation in the limit, a model recently introduced by Kleinberg and Mullainathan [KM24], under the constraint of differential privacy. We consider the continual release model, where a generator must eventually output a stream of valid strings while protecting the privacy of the entire input sequence. Our first main result is that for countable collections of languages, privacy comes at no qualitative cost: we provide an $\varepsilon$-differentially-private algorithm that generates in the limit from any countable collection. This stands in contrast to many learning settings where privacy renders learnability impossible. However, privacy does impose a quantitative cost: there are finite collections of size $k$ for which uniform private generation requires $Ω(k/\varepsilon)$ samples, whereas just one sample suffices non-privately. We then turn to the harder problem of language identification in the limit. Here, we show that privacy creates fundamental barriers. We prove that no $\varepsilon$-DP algorithm can identify a collection containing two languages with an infinite intersection and a finite set difference, a condition far stronger than the classical non-private characterization of identification. Next, we turn to the stochastic setting where the sample strings are sampled i.i.d. from a distribution (instead of being generated by an adversary). Here, we show that private identification is possible if and only if the collection is identifiable in the adversarial model. Together, our results establish new dimensions along which generation and identification differ and, for identification, a separation between adversarial and stochastic settings induced by privacy constraints.
Language Generation with Infinite Contamination
Nov 10, 2025We study language generation in the limit, where an algorithm observes an adversarial enumeration of strings from an unknown target language $K$ and must eventually generate new, unseen strings from $K$. Kleinberg and Mullainathan [KM24] proved that generation is achievable in surprisingly general settings. But their generator suffers from ``mode collapse,'' producing from an ever-smaller subset of the target. To address this, Kleinberg and Wei [KW25] require the generator's output to be ``dense'' in the target language. They showed that generation with density, surprisingly, remains achievable at the same generality. Both results assume perfect data: no noisy insertions and no omissions. This raises a central question: how much contamination can generation tolerate? Recent works made partial progress on this question by studying (non-dense) generation with either finite amounts of noise (but no omissions) or omissions (but no noise). We characterize robustness under contaminated enumerations: 1. Generation under Contamination: Language generation in the limit is achievable for all countable collections iff the fraction of contaminated examples converges to zero. When this fails, we characterize which collections are generable. 2. Dense Generation under Contamination: Dense generation is strictly less robust to contamination than generation. As a byproduct, we resolve an open question of Raman and Raman [ICML25] by showing that generation is possible with only membership oracle access under finitely many contaminated examples. Finally, we introduce a beyond-worst-case model inspired by curriculum learning and prove that dense generation is achievable even with infinite contamination provided the fraction of contaminated examples converges to zero. This suggests curriculum learning may be crucial for learning from noisy web data.
(Im)possibility of Automated Hallucination Detection in Large Language Models
Apr 23, 2025Is automated hallucination detection possible? In this work, we introduce a theoretical framework to analyze the feasibility of automatically detecting hallucinations produced by large language models (LLMs). Inspired by the classical Gold-Angluin framework for language identification and its recent adaptation to language generation by Kleinberg and Mullainathan, we investigate whether an algorithm, trained on examples drawn from an unknown target language $K$ (selected from a countable collection) and given access to an LLM, can reliably determine whether the LLM's outputs are correct or constitute hallucinations. First, we establish an equivalence between hallucination detection and the classical task of language identification. We prove that any hallucination detection method can be converted into a language identification method, and conversely, algorithms solving language identification can be adapted for hallucination detection. Given the inherent difficulty of language identification, this implies that hallucination detection is fundamentally impossible for most language collections if the detector is trained using only correct examples from the target language. Second, we show that the use of expert-labeled feedback, i.e., training the detector with both positive examples (correct statements) and negative examples (explicitly labeled incorrect statements), dramatically changes this conclusion. Under this enriched training regime, automated hallucination detection becomes possible for all countable language collections. These results highlight the essential role of expert-labeled examples in training hallucination detectors and provide theoretical support for feedback-based methods, such as reinforcement learning with human feedback (RLHF), which have proven critical for reliable LLM deployment.
On Agnostic PAC Learning in the Small Error Regime
Feb 13, 2025
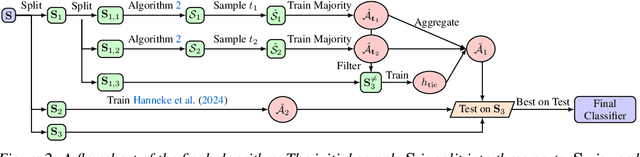
Binary classification in the classic PAC model exhibits a curious phenomenon: Empirical Risk Minimization (ERM) learners are suboptimal in the realizable case yet optimal in the agnostic case. Roughly speaking, this owes itself to the fact that non-realizable distributions $\mathcal{D}$ are simply more difficult to learn than realizable distributions -- even when one discounts a learner's error by $\mathrm{err}(h^*_{\mathcal{D}})$, the error of the best hypothesis in $\mathcal{H}$ for $\mathcal{D}$. Thus, optimal agnostic learners are permitted to incur excess error on (easier-to-learn) distributions $\mathcal{D}$ for which $\tau = \mathrm{err}(h^*_{\mathcal{D}})$ is small. Recent work of Hanneke, Larsen, and Zhivotovskiy (FOCS `24) addresses this shortcoming by including $\tau$ itself as a parameter in the agnostic error term. In this more fine-grained model, they demonstrate tightness of the error lower bound $\tau + \Omega \left(\sqrt{\frac{\tau (d + \log(1 / \delta))}{m}} + \frac{d + \log(1 / \delta)}{m} \right)$ in a regime where $\tau > d/m$, and leave open the question of whether there may be a higher lower bound when $\tau \approx d/m$, with $d$ denoting $\mathrm{VC}(\mathcal{H})$. In this work, we resolve this question by exhibiting a learner which achieves error $c \cdot \tau + O \left(\sqrt{\frac{\tau (d + \log(1 / \delta))}{m}} + \frac{d + \log(1 / \delta)}{m} \right)$ for a constant $c \leq 2.1$, thus matching the lower bound when $\tau \approx d/m$. Further, our learner is computationally efficient and is based upon careful aggregations of ERM classifiers, making progress on two other questions of Hanneke, Larsen, and Zhivotovskiy (FOCS `24). We leave open the interesting question of whether our approach can be refined to lower the constant from 2.1 to 1, which would completely settle the complexity of agnostic learning.
Characterizations of Language Generation With Breadth
Dec 24, 2024
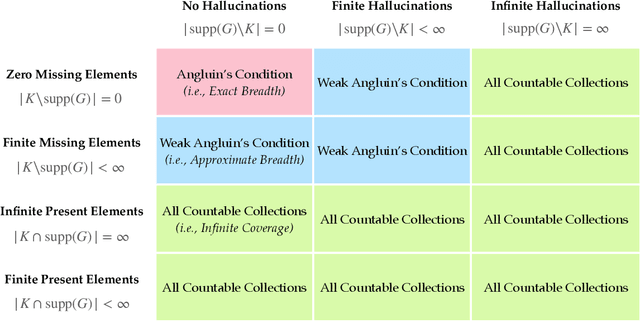
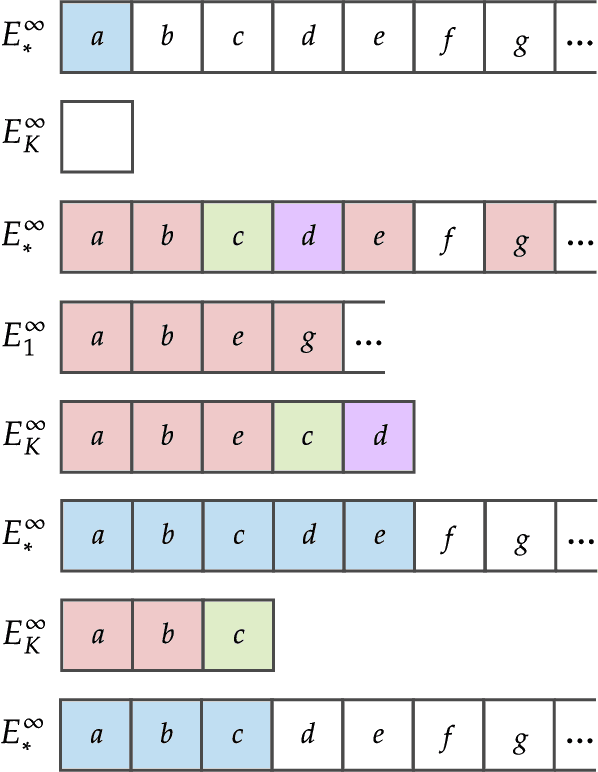
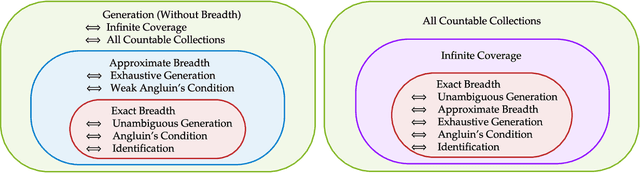
We study language generation in the limit, introduced by Kleinberg and Mullainathan [KM24], building on classical works of Gold [Gol67] and Angluin [Ang79]. [KM24] proposed an algorithm that generates strings from any countable language collection in the limit. While their algorithm eventually outputs strings from the target language $K$, it sacrifices breadth, i.e., the ability to generate all strings in $K$. A key open question in [KM24] is whether this trade-off between consistency and breadth is inherrent. Recent works proposed different notions of consistent generation with breadth. Kalavasis, Mehrotra, and Velegkas [KVM24] introduced three definitions: generation with exact breadth, approximate breadth, and unambiguous generation. Concurrently and independently, Charikar and Pabbaraju [CP24a] proposed exhaustive generation. Both works examined when generation with these notions of breadth is possible. Building on [CP24a, KVM24], we fully characterize language generation for these notions and their natural combinations. For exact breadth, we provide an unconditional lower bound, removing a technical condition from [KVM24] and extending the result of [CP24a] that holds for specific collections of languages. We show that generation with exact breadth is characterized by Angluin's condition for identification. We further introduce a weaker version of Angluin's condition that tightly characterizes both approximate breadth and exhaustive generation, proving their equivalence. Additionally, we show that unambiguous generation is also characterized by Angluin's condition as a special case of a broader result. Finally, we strengthen [KVM24] by giving unconditional lower bounds for stable generators, showing that Angluin's condition characterizes the previous breadth notions for stable generators. This shows a separation between stable and unstable generation with approximate breadth.
Procurement Auctions via Approximately Optimal Submodular Optimization
Nov 20, 2024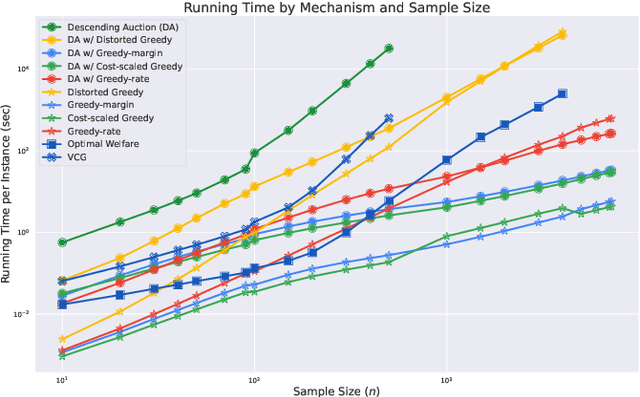
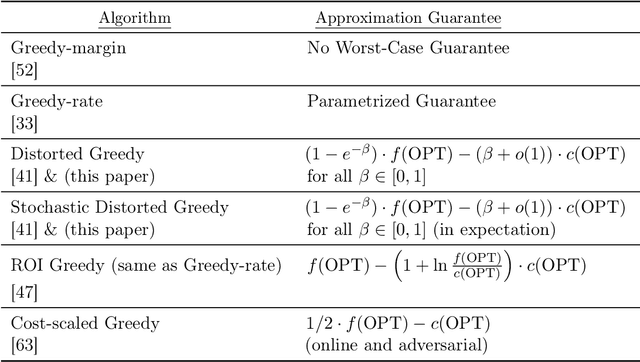
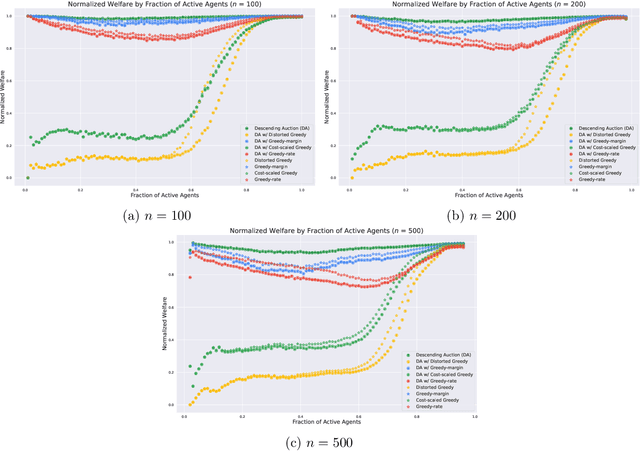
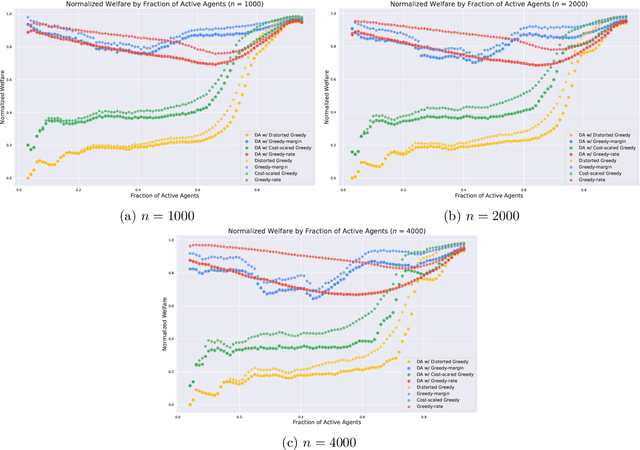
We study procurement auctions, where an auctioneer seeks to acquire services from strategic sellers with private costs. The quality of services is measured by a submodular function known to the auctioneer. Our goal is to design computationally efficient procurement auctions that (approximately) maximize the difference between the quality of the acquired services and the total cost of the sellers, while ensuring incentive compatibility (IC), individual rationality (IR) for sellers, and non-negative surplus (NAS) for the auctioneer. Our contributions are twofold: (i) we provide an improved analysis of existing algorithms for non-positive submodular function maximization, and (ii) we design efficient frameworks that transform submodular optimization algorithms into mechanisms that are IC, IR, NAS, and approximation-preserving. These frameworks apply to both the offline setting, where all sellers' bids and services are available simultaneously, and the online setting, where sellers arrive in an adversarial order, requiring the auctioneer to make irrevocable decisions. We also explore whether state-of-the-art submodular optimization algorithms can be converted into descending auctions in adversarial settings, where the schedule of descending prices is determined by an adversary. We show that a submodular optimization algorithm satisfying bi-criteria $(1/2, 1)$-approximation in welfare can be effectively adapted to a descending auction. Additionally, we establish a connection between descending auctions and online submodular optimization. Finally, we demonstrate the practical applications of our frameworks by instantiating them with state-of-the-art submodular optimization algorithms and empirically comparing their welfare performance on publicly available datasets with thousands of sellers.
Randomized Truthful Auctions with Learning Agents
Nov 14, 2024We study a setting where agents use no-regret learning algorithms to participate in repeated auctions. \citet{kolumbus2022auctions} showed, rather surprisingly, that when bidders participate in second-price auctions using no-regret bidding algorithms, no matter how large the number of interactions $T$ is, the runner-up bidder may not converge to bidding truthfully. Our first result shows that this holds for \emph{general deterministic} truthful auctions. We also show that the ratio of the learning rates of the bidders can \emph{qualitatively} affect the convergence of the bidders. Next, we consider the problem of revenue maximization in this environment. In the setting with fully rational bidders, \citet{myerson1981optimal} showed that revenue can be maximized by using a second-price auction with reserves.We show that, in stark contrast, in our setting with learning bidders, \emph{randomized} auctions can have strictly better revenue guarantees than second-price auctions with reserves, when $T$ is large enough. Finally, we study revenue maximization in the non-asymptotic regime. We define a notion of {\em auctioneer regret} comparing the revenue generated to the revenue of a second price auction with truthful bids. When the auctioneer has to use the same auction throughout the interaction, we show an (almost) tight regret bound of $\smash{\widetilde \Theta(T^{3/4})}.$ If the auctioneer can change auctions during the interaction, but in a way that is oblivious to the bids, we show an (almost) tight bound of $\smash{\widetilde \Theta(\sqrt{T})}.$
On the Limits of Language Generation: Trade-Offs Between Hallucination and Mode Collapse
Nov 14, 2024



Specifying all desirable properties of a language model is challenging, but certain requirements seem essential. Given samples from an unknown language, the trained model should produce valid strings not seen in training and be expressive enough to capture the language's full richness. Otherwise, outputting invalid strings constitutes "hallucination," and failing to capture the full range leads to "mode collapse." We ask if a language model can meet both requirements. We investigate this within a statistical language generation setting building on Gold and Angluin. Here, the model receives random samples from a distribution over an unknown language K, which belongs to a possibly infinite collection of languages. The goal is to generate unseen strings from K. We say the model generates from K with consistency and breadth if, as training size increases, its output converges to all unseen strings in K. Kleinberg and Mullainathan [KM24] asked if consistency and breadth in language generation are possible. We answer this negatively: for a large class of language models, including next-token prediction models, this is impossible for most collections of candidate languages. This contrasts with [KM24]'s result, showing consistent generation without breadth is possible for any countable collection of languages. Our finding highlights that generation with breadth fundamentally differs from generation without breadth. As a byproduct, we establish near-tight bounds on the number of samples needed for generation with or without breadth. Finally, our results offer hope: consistent generation with breadth is achievable for any countable collection of languages when negative examples (strings outside K) are available alongside positive ones. This suggests that post-training feedback, which encodes negative examples, can be crucial in reducing hallucinations while limiting mode collapse.
Understanding Aggregations of Proper Learners in Multiclass Classification
Oct 30, 2024Multiclass learnability is known to exhibit a properness barrier: there are learnable classes which cannot be learned by any proper learner. Binary classification faces no such barrier for learnability, but a similar one for optimal learning, which can in general only be achieved by improper learners. Fortunately, recent advances in binary classification have demonstrated that this requirement can be satisfied using aggregations of proper learners, some of which are strikingly simple. This raises a natural question: to what extent can simple aggregations of proper learners overcome the properness barrier in multiclass classification? We give a positive answer to this question for classes which have finite Graph dimension, $d_G$. Namely, we demonstrate that the optimal binary learners of Hanneke, Larsen, and Aden-Ali et al. (appropriately generalized to the multiclass setting) achieve sample complexity $O\left(\frac{d_G + \ln(1 / \delta)}{\epsilon}\right)$. This forms a strict improvement upon the sample complexity of ERM. We complement this with a lower bound demonstrating that for certain classes of Graph dimension $d_G$, majorities of ERM learners require $\Omega \left( \frac{d_G + \ln(1 / \delta)}{\epsilon}\right)$ samples. Furthermore, we show that a single ERM requires $\Omega \left(\frac{d_G \ln(1 / \epsilon) + \ln(1 / \delta)}{\epsilon}\right)$ samples on such classes, exceeding the lower bound of Daniely et al. (2015) by a factor of $\ln(1 / \epsilon)$. For multiclass learning in full generality -- i.e., for classes of finite DS dimension but possibly infinite Graph dimension -- we give a strong refutation to these learning strategies, by exhibiting a learnable class which cannot be learned to constant error by any aggregation of a finite number of proper learners.
Injecting Undetectable Backdoors in Deep Learning and Language Models
Jun 09, 2024
As ML models become increasingly complex and integral to high-stakes domains such as finance and healthcare, they also become more susceptible to sophisticated adversarial attacks. We investigate the threat posed by undetectable backdoors in models developed by insidious external expert firms. When such backdoors exist, they allow the designer of the model to sell information to the users on how to carefully perturb the least significant bits of their input to change the classification outcome to a favorable one. We develop a general strategy to plant a backdoor to neural networks while ensuring that even if the model's weights and architecture are accessible, the existence of the backdoor is still undetectable. To achieve this, we utilize techniques from cryptography such as cryptographic signatures and indistinguishability obfuscation. We further introduce the notion of undetectable backdoors to language models and extend our neural network backdoor attacks to such models based on the existence of steganographic functions.