 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Mixture Models via Efficient High-dimensional Sparse Fourier Transforms
Jan 08, 2026In this work, we give a ${\rm poly}(d,k)$ time and sample algorithm for efficiently learning the parameters of a mixture of $k$ spherical distributions in $d$ dimensions. Unlike all previous methods, our techniques apply to heavy-tailed distributions and include examples that do not even have finite covariances. Our method succeeds whenever the cluster distributions have a characteristic function with sufficiently heavy tails. Such distributions include the Laplace distribution but crucially exclude Gaussians. All previous methods for learning mixture models relied implicitly or explicitly on the low-degree moments. Even for the case of Laplace distributions, we prove that any such algorithm must use super-polynomially many samples. Our method thus adds to the short list of techniques that bypass the limitations of the method of moments. Somewhat surprisingly, our algorithm does not require any minimum separation between the cluster means. This is in stark contrast to spherical Gaussian mixtures where a minimum $\ell_2$-separation is provably necessary even information-theoretically [Regev and Vijayaraghavan '17]. Our methods compose well with existing techniques and allow obtaining ''best of both worlds" guarantees for mixtures where every component either has a heavy-tailed characteristic function or has a sub-Gaussian tail with a light-tailed characteristic function. Our algorithm is based on a new approach to learning mixture models via efficient high-dimensional sparse Fourier transforms. We believe that this method will find more applications to statistical estimation. As an example, we give an algorithm for consistent robust mean estimation against noise-oblivious adversaries, a model practically motivated by the literature on multiple hypothesis testing. It was formally proposed in a recent Master's thesis by one of the authors, and has already inspired follow-up works.
What Makes Treatment Effects Identifiable? Characterizations and Estimators Beyond Unconfoundedness
Jun 04, 2025Most of the widely used estimators of the average treatment effect (ATE) in causal inference rely on the assumptions of unconfoundedness and overlap. Unconfoundedness requires that the observed covariates account for all correlations between the outcome and treatment. Overlap requires the existence of randomness in treatment decisions for all individuals. Nevertheless, many types of studies frequently violate unconfoundedness or overlap, for instance, observational studies with deterministic treatment decisions -- popularly known as Regression Discontinuity designs -- violate overlap. In this paper, we initiate the study of general conditions that enable the identification of the average treatment effect, extending beyond unconfoundedness and overlap. In particular, following the paradigm of statistical learning theory, we provide an interpretable condition that is sufficient and nearly necessary for the identification of ATE. Moreover, this condition characterizes the identification of the average treatment effect on the treated (ATT) and can be used to characterize other treatment effects as well. To illustrate the utility of our condition, we present several well-studied scenarios where our condition is satisfied and, hence, we prove that ATE can be identified in regimes that prior works could not capture. For example, under mild assumptions on the data distributions, this holds for the models proposed by Tan (2006) and Rosenbaum (2002), and the Regression Discontinuity design model introduced by Thistlethwaite and Campbell (1960). For each of these scenarios, we also show that, under natural additional assumptions, ATE can be estimated from finite samples. We believe these findings open new avenues for bridging learning-theoretic insights and causal inference methodologies, particularly in observational studies with complex treatment mechanisms.
Private Statistical Estimation via Truncation
May 18, 2025We introduce a novel framework for differentially private (DP) statistical estimation via data truncation, addressing a key challenge in DP estimation when the data support is unbounded. Traditional approaches rely on problem-specific sensitivity analysis, limiting their applicability. By leveraging techniques from truncated statistics, we develop computationally efficient DP estimators for exponential family distributions, including Gaussian mean and covariance estimation, achieving near-optimal sample complexity. Previous works on exponential families only consider bounded or one-dimensional families. Our approach mitigates sensitivity through truncation while carefully correcting for the introduced bias using maximum likelihood estimation and DP stochastic gradient descent. Along the way, we establish improved uniform convergence guarantees for the log-likelihood function of exponential families, which may be of independent interest. Our results provide a general blueprint for DP algorithm design via truncated statistics.
Learning with Positive and Imperfect Unlabeled Data
Apr 14, 2025
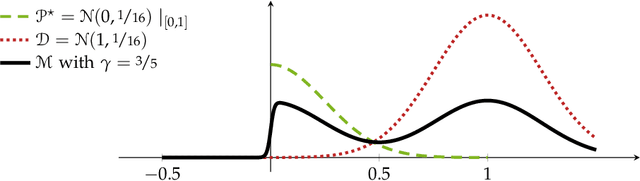
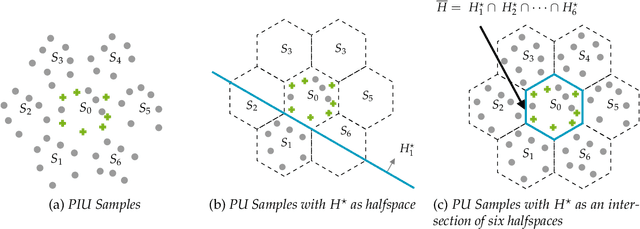
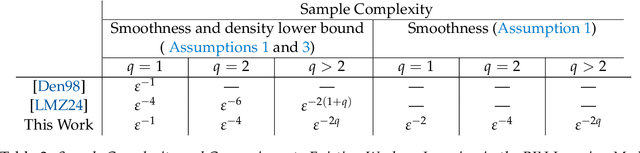
We study the problem of learning binary classifiers from positive and unlabeled data when the unlabeled data distribution is shifted, which we call Positive and Imperfect Unlabeled (PIU) Learning. In the absence of covariate shifts, i.e., with perfect unlabeled data, Denis (1998) reduced this problem to learning under Massart noise; however, that reduction fails under even slight shifts. Our main results on PIU learning are the characterizations of the sample complexity of PIU learning and a computationally and sample-efficient algorithm achieving a misclassification error $\varepsilon$. We further show that our results lead to new algorithms for several related problems. 1. Learning from smooth distributions: We give algorithms that learn interesting concept classes from only positive samples under smooth feature distributions, bypassing known existing impossibility results and contributing to recent advances in smoothened learning (Haghtalab et al, J.ACM'24) (Chandrasekaran et al., COLT'24). 2. Learning with a list of unlabeled distributions: We design new algorithms that apply to a broad class of concept classes under the assumption that we are given a list of unlabeled distributions, one of which--unknown to the learner--is $O(1)$-close to the true feature distribution. 3. Estimation in the presence of unknown truncation: We give the first polynomial sample and time algorithm for estimating the parameters of an exponential family distribution from samples truncated to an unknown set approximable by polynomials in $L_1$-norm. This improves the algorithm by Lee et al. (FOCS'24) that requires approximation in $L_2$-norm. 4. Detecting truncation: We present new algorithms for detecting whether given samples have been truncated (or not) for a broad class of non-product distributions, including non-product distributions, improving the algorithm by De et al. (STOC'24).
Fixed Point Computation: Beating Brute Force with Smoothed Analysis
Jan 18, 2025We propose a new algorithm that finds an $\varepsilon$-approximate fixed point of a smooth function from the $n$-dimensional $\ell_2$ unit ball to itself. We use the general framework of finding approximate solutions to a variational inequality, a problem that subsumes fixed point computation and the computation of a Nash Equilibrium. The algorithm's runtime is bounded by $e^{O(n)}/\varepsilon$, under the smoothed-analysis framework. This is the first known algorithm in such a generality whose runtime is faster than $(1/\varepsilon)^{O(n)}$, which is a time that suffices for an exhaustive search. We complement this result with a lower bound of $e^{\Omega(n)}$ on the query complexity for finding an $O(1)$-approximate fixed point on the unit ball, which holds even in the smoothed-analysis model, yet without the assumption that the function is smooth. Existing lower bounds are only known for the hypercube, and adapting them to the ball does not give non-trivial results even for finding $O(1/\sqrt{n})$-approximate fixed points.
On the Hardness of Learning One Hidden Layer Neural Networks
Oct 04, 2024
In this work, we consider the problem of learning one hidden layer ReLU neural networks with inputs from $\mathbb{R}^d$. We show that this learning problem is hard under standard cryptographic assumptions even when: (1) the size of the neural network is polynomial in $d$, (2) its input distribution is a standard Gaussian, and (3) the noise is Gaussian and polynomially small in $d$. Our hardness result is based on the hardness of the Continuous Learning with Errors (CLWE) problem, and in particular, is based on the largely believed worst-case hardness of approximately solving the shortest vector problem up to a multiplicative polynomial factor.
Smaller Confidence Intervals From IPW Estimators via Data-Dependent Coarsening
Oct 02, 2024Inverse propensity-score weighted (IPW) estimators are prevalent in causal inference for estimating average treatment effects in observational studies. Under unconfoundedness, given accurate propensity scores and $n$ samples, the size of confidence intervals of IPW estimators scales down with $n$, and, several of their variants improve the rate of scaling. However, neither IPW estimators nor their variants are robust to inaccuracies: even if a single covariate has an $\varepsilon>0$ additive error in the propensity score, the size of confidence intervals of these estimators can increase arbitrarily. Moreover, even without errors, the rate with which the confidence intervals of these estimators go to zero with $n$ can be arbitrarily slow in the presence of extreme propensity scores (those close to 0 or 1). We introduce a family of Coarse IPW (CIPW) estimators that captures existing IPW estimators and their variants. Each CIPW estimator is an IPW estimator on a coarsened covariate space, where certain covariates are merged. Under mild assumptions, e.g., Lipschitzness in expected outcomes and sparsity of extreme propensity scores, we give an efficient algorithm to find a robust estimator: given $\varepsilon$-inaccurate propensity scores and $n$ samples, its confidence interval size scales with $\varepsilon+1/\sqrt{n}$. In contrast, under the same assumptions, existing estimators' confidence interval sizes are $\Omega(1)$ irrespective of $\varepsilon$ and $n$. Crucially, our estimator is data-dependent and we show that no data-independent CIPW estimator can be robust to inaccuracies.
Efficient Statistics With Unknown Truncation, Polynomial Time Algorithms, Beyond Gaussians
Oct 02, 2024



We study the estimation of distributional parameters when samples are shown only if they fall in some unknown set $S \subseteq \mathbb{R}^d$. Kontonis, Tzamos, and Zampetakis (FOCS'19) gave a $d^{\mathrm{poly}(1/\varepsilon)}$ time algorithm for finding $\varepsilon$-accurate parameters for the special case of Gaussian distributions with diagonal covariance matrix. Recently, Diakonikolas, Kane, Pittas, and Zarifis (COLT'24) showed that this exponential dependence on $1/\varepsilon$ is necessary even when $S$ belongs to some well-behaved classes. These works leave the following open problems which we address in this work: Can we estimate the parameters of any Gaussian or even extend beyond Gaussians? Can we design $\mathrm{poly}(d/\varepsilon)$ time algorithms when $S$ is a simple set such as a halfspace? We make progress on both of these questions by providing the following results: 1. Toward the first question, we give a $d^{\mathrm{poly}(\ell/\varepsilon)}$ time algorithm for any exponential family that satisfies some structural assumptions and any unknown set $S$ that is $\varepsilon$-approximable by degree-$\ell$ polynomials. This result has two important applications: 1a) The first algorithm for estimating arbitrary Gaussian distributions from samples truncated to an unknown $S$; and 1b) The first algorithm for linear regression with unknown truncation and Gaussian features. 2. To address the second question, we provide an algorithm with runtime $\mathrm{poly}(d/\varepsilon)$ that works for a set of exponential families (containing all Gaussians) when $S$ is a halfspace or an axis-aligned rectangle. Along the way, we develop tools that may be of independent interest, including, a reduction from PAC learning with positive and unlabeled samples to PAC learning with positive and negative samples that is robust to certain covariate shifts.
Imperfect-Recall Games: Equilibrium Concepts and Their Complexity
Jun 23, 2024We investigate optimal decision making under imperfect recall, that is, when an agent forgets information it once held before. An example is the absentminded driver game, as well as team games in which the members have limited communication capabilities. In the framework of extensive-form games with imperfect recall, we analyze the computational complexities of finding equilibria in multiplayer settings across three different solution concepts: Nash, multiselves based on evidential decision theory (EDT), and multiselves based on causal decision theory (CDT). We are interested in both exact and approximate solution computation. As special cases, we consider (1) single-player games, (2) two-player zero-sum games and relationships to maximin values, and (3) games without exogenous stochasticity (chance nodes). We relate these problems to the complexity classes P, PPAD, PLS, $\Sigma_2^P$ , $\exists$R, and $\exists \forall$R.
Injecting Undetectable Backdoors in Deep Learning and Language Models
Jun 09, 2024
As ML models become increasingly complex and integral to high-stakes domains such as finance and healthcare, they also become more susceptible to sophisticated adversarial attacks. We investigate the threat posed by undetectable backdoors in models developed by insidious external expert firms. When such backdoors exist, they allow the designer of the model to sell information to the users on how to carefully perturb the least significant bits of their input to change the classification outcome to a favorable one. We develop a general strategy to plant a backdoor to neural networks while ensuring that even if the model's weights and architecture are accessible, the existence of the backdoor is still undetectable. To achieve this, we utilize techniques from cryptography such as cryptographic signatures and indistinguishability obfuscation. We further introduce the notion of undetectable backdoors to language models and extend our neural network backdoor attacks to such models based on the existence of steganographic functions.