 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Generation with Infinite Contamination
Nov 10, 2025We study language generation in the limit, where an algorithm observes an adversarial enumeration of strings from an unknown target language $K$ and must eventually generate new, unseen strings from $K$. Kleinberg and Mullainathan [KM24] proved that generation is achievable in surprisingly general settings. But their generator suffers from ``mode collapse,'' producing from an ever-smaller subset of the target. To address this, Kleinberg and Wei [KW25] require the generator's output to be ``dense'' in the target language. They showed that generation with density, surprisingly, remains achievable at the same generality. Both results assume perfect data: no noisy insertions and no omissions. This raises a central question: how much contamination can generation tolerate? Recent works made partial progress on this question by studying (non-dense) generation with either finite amounts of noise (but no omissions) or omissions (but no noise). We characterize robustness under contaminated enumerations: 1. Generation under Contamination: Language generation in the limit is achievable for all countable collections iff the fraction of contaminated examples converges to zero. When this fails, we characterize which collections are generable. 2. Dense Generation under Contamination: Dense generation is strictly less robust to contamination than generation. As a byproduct, we resolve an open question of Raman and Raman [ICML25] by showing that generation is possible with only membership oracle access under finitely many contaminated examples. Finally, we introduce a beyond-worst-case model inspired by curriculum learning and prove that dense generation is achievable even with infinite contamination provided the fraction of contaminated examples converges to zero. This suggests curriculum learning may be crucial for learning from noisy web data.
What Makes Treatment Effects Identifiable? Characterizations and Estimators Beyond Unconfoundedness
Jun 04, 2025Most of the widely used estimators of the average treatment effect (ATE) in causal inference rely on the assumptions of unconfoundedness and overlap. Unconfoundedness requires that the observed covariates account for all correlations between the outcome and treatment. Overlap requires the existence of randomness in treatment decisions for all individuals. Nevertheless, many types of studies frequently violate unconfoundedness or overlap, for instance, observational studies with deterministic treatment decisions -- popularly known as Regression Discontinuity designs -- violate overlap. In this paper, we initiate the study of general conditions that enable the identification of the average treatment effect, extending beyond unconfoundedness and overlap. In particular, following the paradigm of statistical learning theory, we provide an interpretable condition that is sufficient and nearly necessary for the identification of ATE. Moreover, this condition characterizes the identification of the average treatment effect on the treated (ATT) and can be used to characterize other treatment effects as well. To illustrate the utility of our condition, we present several well-studied scenarios where our condition is satisfied and, hence, we prove that ATE can be identified in regimes that prior works could not capture. For example, under mild assumptions on the data distributions, this holds for the models proposed by Tan (2006) and Rosenbaum (2002), and the Regression Discontinuity design model introduced by Thistlethwaite and Campbell (1960). For each of these scenarios, we also show that, under natural additional assumptions, ATE can be estimated from finite samples. We believe these findings open new avenues for bridging learning-theoretic insights and causal inference methodologies, particularly in observational studies with complex treatment mechanisms.
Learning with Positive and Imperfect Unlabeled Data
Apr 14, 2025
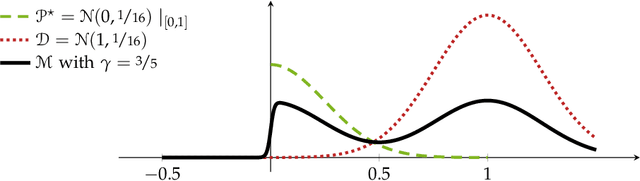
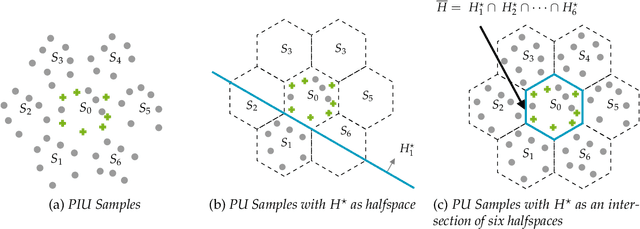
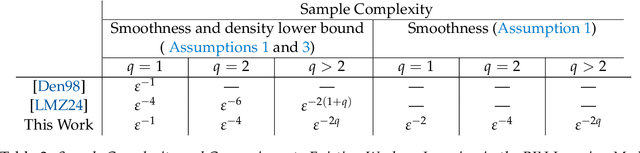
We study the problem of learning binary classifiers from positive and unlabeled data when the unlabeled data distribution is shifted, which we call Positive and Imperfect Unlabeled (PIU) Learning. In the absence of covariate shifts, i.e., with perfect unlabeled data, Denis (1998) reduced this problem to learning under Massart noise; however, that reduction fails under even slight shifts. Our main results on PIU learning are the characterizations of the sample complexity of PIU learning and a computationally and sample-efficient algorithm achieving a misclassification error $\varepsilon$. We further show that our results lead to new algorithms for several related problems. 1. Learning from smooth distributions: We give algorithms that learn interesting concept classes from only positive samples under smooth feature distributions, bypassing known existing impossibility results and contributing to recent advances in smoothened learning (Haghtalab et al, J.ACM'24) (Chandrasekaran et al., COLT'24). 2. Learning with a list of unlabeled distributions: We design new algorithms that apply to a broad class of concept classes under the assumption that we are given a list of unlabeled distributions, one of which--unknown to the learner--is $O(1)$-close to the true feature distribution. 3. Estimation in the presence of unknown truncation: We give the first polynomial sample and time algorithm for estimating the parameters of an exponential family distribution from samples truncated to an unknown set approximable by polynomials in $L_1$-norm. This improves the algorithm by Lee et al. (FOCS'24) that requires approximation in $L_2$-norm. 4. Detecting truncation: We present new algorithms for detecting whether given samples have been truncated (or not) for a broad class of non-product distributions, including non-product distributions, improving the algorithm by De et al. (STOC'24).
DDPM Score Matching and Distribution Learning
Apr 07, 2025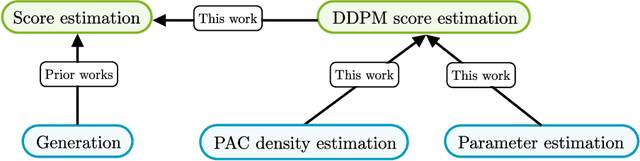
Score estimation is the backbone of score-based generative models (SGMs), especially denoising diffusion probabilistic models (DDPMs). A key result in this area shows that with accurate score estimates, SGMs can efficiently generate samples from any realistic data distribution (Chen et al., ICLR'23; Lee et al., ALT'23). This distribution learning result, where the learned distribution is implicitly that of the sampler's output, does not explain how score estimation relates to classical tasks of parameter and density estimation. This paper introduces a framework that reduces score estimation to these two tasks, with various implications for statistical and computational learning theory: Parameter Estimation: Koehler et al. (ICLR'23) demonstrate that a score-matching variant is statistically inefficient for the parametric estimation of multimodal densities common in practice. In contrast, we show that under mild conditions, denoising score-matching in DDPMs is asymptotically efficient. Density Estimation: By linking generation to score estimation, we lift existing score estimation guarantees to $(\epsilon,\delta)$-PAC density estimation, i.e., a function approximating the target log-density within $\epsilon$ on all but a $\delta$-fraction of the space. We provide (i) minimax rates for density estimation over H\"older classes and (ii) a quasi-polynomial PAC density estimation algorithm for the classical Gaussian location mixture model, building on and addressing an open problem from Gatmiry et al. (arXiv'24). Lower Bounds for Score Estimation: Our framework offers the first principled method to prove computational lower bounds for score estimation across general distributions. As an application, we establish cryptographic lower bounds for score estimation in general Gaussian mixture models, conceptually recovering Song's (NeurIPS'24) result and advancing his key open problem.
Can SGD Select Good Fishermen? Local Convergence under Self-Selection Biases and Beyond
Apr 06, 2025
We revisit the problem of estimating $k$ linear regressors with self-selection bias in $d$ dimensions with the maximum selection criterion, as introduced by Cherapanamjeri, Daskalakis, Ilyas, and Zampetakis [CDIZ23, STOC'23]. Our main result is a $\operatorname{poly}(d,k,1/\varepsilon) + {k}^{O(k)}$ time algorithm for this problem, which yields an improvement in the running time of the algorithms of [CDIZ23] and [GM24, arXiv]. We achieve this by providing the first local convergence algorithm for self-selection, thus resolving the main open question of [CDIZ23]. To obtain this algorithm, we reduce self-selection to a seemingly unrelated statistical problem called coarsening. Coarsening occurs when one does not observe the exact value of the sample but only some set (a subset of the sample space) that contains the exact value. Inference from coarse samples arises in various real-world applications due to rounding by humans and algorithms, limited precision of instruments, and lag in multi-agent systems. Our reduction to coarsening is intuitive and relies on the geometry of the self-selection problem, which enables us to bypass the limitations of previous analytic approaches. To demonstrate its applicability, we provide a local convergence algorithm for linear regression under another self-selection criterion, which is related to second-price auction data. Further, we give the first polynomial time local convergence algorithm for coarse Gaussian mean estimation given samples generated from a convex partition. Previously, only a sample-efficient algorithm was known due to Fotakis, Kalavasis, Kontonis, and Tzamos [FKKT21, COLT'21].
Characterizations of Language Generation With Breadth
Dec 24, 2024
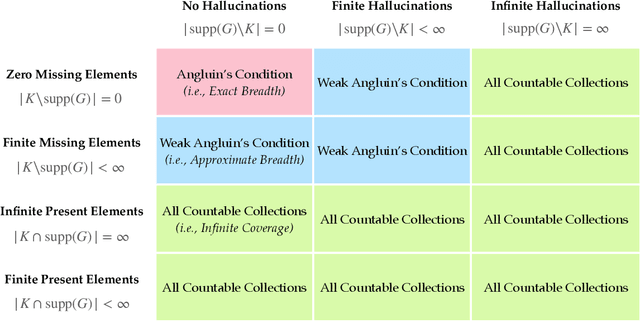
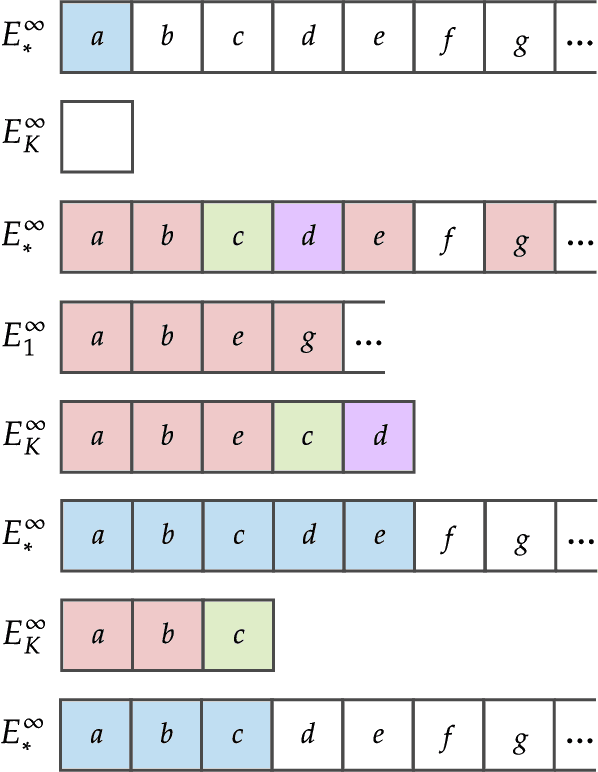
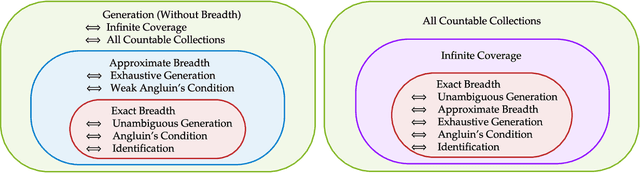
We study language generation in the limit, introduced by Kleinberg and Mullainathan [KM24], building on classical works of Gold [Gol67] and Angluin [Ang79]. [KM24] proposed an algorithm that generates strings from any countable language collection in the limit. While their algorithm eventually outputs strings from the target language $K$, it sacrifices breadth, i.e., the ability to generate all strings in $K$. A key open question in [KM24] is whether this trade-off between consistency and breadth is inherrent. Recent works proposed different notions of consistent generation with breadth. Kalavasis, Mehrotra, and Velegkas [KVM24] introduced three definitions: generation with exact breadth, approximate breadth, and unambiguous generation. Concurrently and independently, Charikar and Pabbaraju [CP24a] proposed exhaustive generation. Both works examined when generation with these notions of breadth is possible. Building on [CP24a, KVM24], we fully characterize language generation for these notions and their natural combinations. For exact breadth, we provide an unconditional lower bound, removing a technical condition from [KVM24] and extending the result of [CP24a] that holds for specific collections of languages. We show that generation with exact breadth is characterized by Angluin's condition for identification. We further introduce a weaker version of Angluin's condition that tightly characterizes both approximate breadth and exhaustive generation, proving their equivalence. Additionally, we show that unambiguous generation is also characterized by Angluin's condition as a special case of a broader result. Finally, we strengthen [KVM24] by giving unconditional lower bounds for stable generators, showing that Angluin's condition characterizes the previous breadth notions for stable generators. This shows a separation between stable and unstable generation with approximate breadth.
On the Limits of Language Generation: Trade-Offs Between Hallucination and Mode Collapse
Nov 14, 2024



Specifying all desirable properties of a language model is challenging, but certain requirements seem essential. Given samples from an unknown language, the trained model should produce valid strings not seen in training and be expressive enough to capture the language's full richness. Otherwise, outputting invalid strings constitutes "hallucination," and failing to capture the full range leads to "mode collapse." We ask if a language model can meet both requirements. We investigate this within a statistical language generation setting building on Gold and Angluin. Here, the model receives random samples from a distribution over an unknown language K, which belongs to a possibly infinite collection of languages. The goal is to generate unseen strings from K. We say the model generates from K with consistency and breadth if, as training size increases, its output converges to all unseen strings in K. Kleinberg and Mullainathan [KM24] asked if consistency and breadth in language generation are possible. We answer this negatively: for a large class of language models, including next-token prediction models, this is impossible for most collections of candidate languages. This contrasts with [KM24]'s result, showing consistent generation without breadth is possible for any countable collection of languages. Our finding highlights that generation with breadth fundamentally differs from generation without breadth. As a byproduct, we establish near-tight bounds on the number of samples needed for generation with or without breadth. Finally, our results offer hope: consistent generation with breadth is achievable for any countable collection of languages when negative examples (strings outside K) are available alongside positive ones. This suggests that post-training feedback, which encodes negative examples, can be crucial in reducing hallucinations while limiting mode collapse.
Smaller Confidence Intervals From IPW Estimators via Data-Dependent Coarsening
Oct 02, 2024Inverse propensity-score weighted (IPW) estimators are prevalent in causal inference for estimating average treatment effects in observational studies. Under unconfoundedness, given accurate propensity scores and $n$ samples, the size of confidence intervals of IPW estimators scales down with $n$, and, several of their variants improve the rate of scaling. However, neither IPW estimators nor their variants are robust to inaccuracies: even if a single covariate has an $\varepsilon>0$ additive error in the propensity score, the size of confidence intervals of these estimators can increase arbitrarily. Moreover, even without errors, the rate with which the confidence intervals of these estimators go to zero with $n$ can be arbitrarily slow in the presence of extreme propensity scores (those close to 0 or 1). We introduce a family of Coarse IPW (CIPW) estimators that captures existing IPW estimators and their variants. Each CIPW estimator is an IPW estimator on a coarsened covariate space, where certain covariates are merged. Under mild assumptions, e.g., Lipschitzness in expected outcomes and sparsity of extreme propensity scores, we give an efficient algorithm to find a robust estimator: given $\varepsilon$-inaccurate propensity scores and $n$ samples, its confidence interval size scales with $\varepsilon+1/\sqrt{n}$. In contrast, under the same assumptions, existing estimators' confidence interval sizes are $\Omega(1)$ irrespective of $\varepsilon$ and $n$. Crucially, our estimator is data-dependent and we show that no data-independent CIPW estimator can be robust to inaccuracies.
Efficient Statistics With Unknown Truncation, Polynomial Time Algorithms, Beyond Gaussians
Oct 02, 2024



We study the estimation of distributional parameters when samples are shown only if they fall in some unknown set $S \subseteq \mathbb{R}^d$. Kontonis, Tzamos, and Zampetakis (FOCS'19) gave a $d^{\mathrm{poly}(1/\varepsilon)}$ time algorithm for finding $\varepsilon$-accurate parameters for the special case of Gaussian distributions with diagonal covariance matrix. Recently, Diakonikolas, Kane, Pittas, and Zarifis (COLT'24) showed that this exponential dependence on $1/\varepsilon$ is necessary even when $S$ belongs to some well-behaved classes. These works leave the following open problems which we address in this work: Can we estimate the parameters of any Gaussian or even extend beyond Gaussians? Can we design $\mathrm{poly}(d/\varepsilon)$ time algorithms when $S$ is a simple set such as a halfspace? We make progress on both of these questions by providing the following results: 1. Toward the first question, we give a $d^{\mathrm{poly}(\ell/\varepsilon)}$ time algorithm for any exponential family that satisfies some structural assumptions and any unknown set $S$ that is $\varepsilon$-approximable by degree-$\ell$ polynomials. This result has two important applications: 1a) The first algorithm for estimating arbitrary Gaussian distributions from samples truncated to an unknown $S$; and 1b) The first algorithm for linear regression with unknown truncation and Gaussian features. 2. To address the second question, we provide an algorithm with runtime $\mathrm{poly}(d/\varepsilon)$ that works for a set of exponential families (containing all Gaussians) when $S$ is a halfspace or an axis-aligned rectangle. Along the way, we develop tools that may be of independent interest, including, a reduction from PAC learning with positive and unlabeled samples to PAC learning with positive and negative samples that is robust to certain covariate shifts.
Fair Classification with Partial Feedback: An Exploration-Based Data-Collection Approach
Feb 17, 2024In many predictive contexts (e.g., credit lending), true outcomes are only observed for samples that were positively classified in the past. These past observations, in turn, form training datasets for classifiers that make future predictions. However, such training datasets lack information about the outcomes of samples that were (incorrectly) negatively classified in the past and can lead to erroneous classifiers. We present an approach that trains a classifier using available data and comes with a family of exploration strategies to collect outcome data about subpopulations that otherwise would have been ignored. For any exploration strategy, the approach comes with guarantees that (1) all sub-populations are explored, (2) the fraction of false positives is bounded, and (3) the trained classifier converges to a "desired" classifier. The right exploration strategy is context-dependent; it can be chosen to improve learning guarantees and encode context-specific group fairness properties. Evaluation on real-world datasets shows that this approach consistently boosts the quality of collected outcome data and improves the fraction of true positives for all groups, with only a small reduction in predictive utility.