 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEMBER2024 -- A Benchmark Dataset for Holistic Evaluation of Malware Classifiers
Jun 05, 2025



A lack of accessible data has historically restricted malware analysis research, and practitioners have relied heavily on datasets provided by industry sources to advance. Existing public datasets are limited by narrow scope - most include files targeting a single platform, have labels supporting just one type of malware classification task, and make no effort to capture the evasive files that make malware detection difficult in practice. We present EMBER2024, a new dataset that enables holistic evaluation of malware classifiers. Created in collaboration with the authors of EMBER2017 and EMBER2018, the EMBER2024 dataset includes hashes, metadata, feature vectors, and labels for more than 3.2 million files from six file formats. Our dataset supports the training and evaluation of machine learning models on seven malware classification tasks, including malware detection, malware family classification, and malware behavior identification. EMBER2024 is the first to include a collection of malicious files that initially went undetected by a set of antivirus products, creating a "challenge" set to assess classifier performance against evasive malware. This work also introduces EMBER feature version 3, with added support for several new feature types. We are releasing the EMBER2024 dataset to promote reproducibility and empower researchers in the pursuit of new malware research topics.
Llama-3.1-FoundationAI-SecurityLLM-Base-8B Technical Report
Apr 28, 2025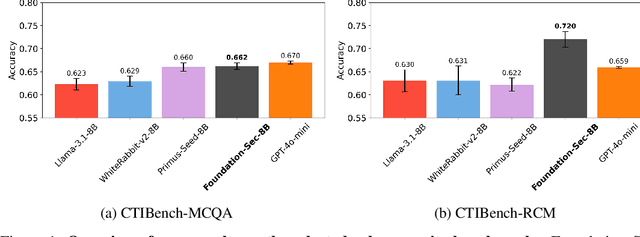
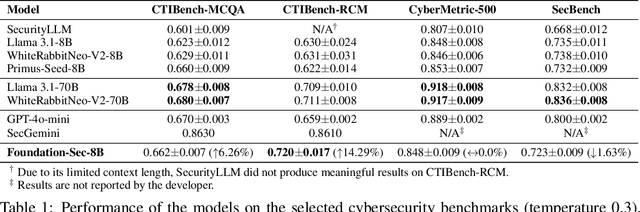
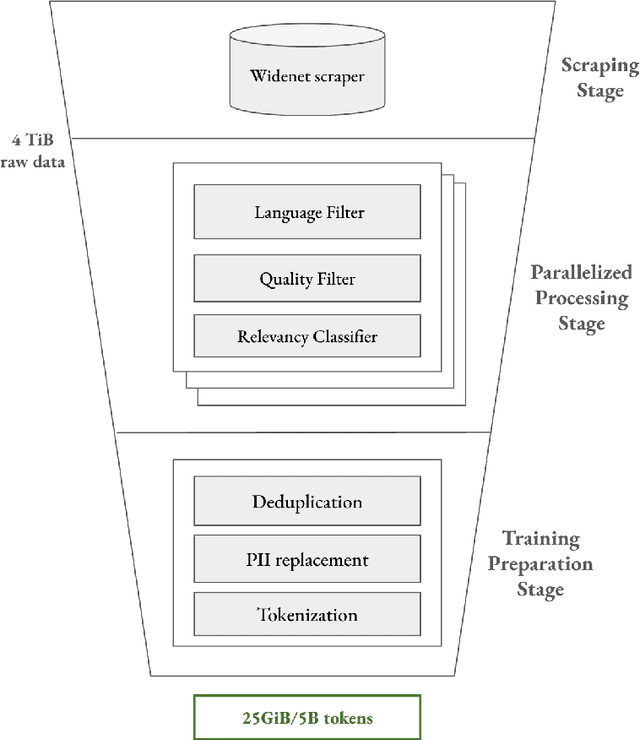

As transformer-based large language models (LLMs) increasingly permeate society, they have revolutionized domains such as software engineering, creative writing, and digital arts. However, their adoption in cybersecurity remains limited due to challenges like scarcity of specialized training data and complexity of representing cybersecurity-specific knowledge. To address these gaps, we present Foundation-Sec-8B, a cybersecurity-focused LLM built on the Llama 3.1 architecture and enhanced through continued pretraining on a carefully curated cybersecurity corpus. We evaluate Foundation-Sec-8B across both established and new cybersecurity benchmarks, showing that it matches Llama 3.1-70B and GPT-4o-mini in certain cybersecurity-specific tasks. By releasing our model to the public, we aim to accelerate progress and adoption of AI-driven tools in both public and private cybersecurity contexts.
Tree of Attacks: Jailbreaking Black-Box LLMs Automatically
Dec 04, 2023While Large Language Models (LLMs) display versatile functionality, they continue to generate harmful, biased, and toxic content, as demonstrated by the prevalence of human-designed jailbreaks. In this work, we present Tree of Attacks with Pruning (TAP), an automated method for generating jailbreaks that only requires black-box access to the target LLM. TAP utilizes an LLM to iteratively refine candidate (attack) prompts using tree-of-thoughts reasoning until one of the generated prompts jailbreaks the target. Crucially, before sending prompts to the target, TAP assesses them and prunes the ones unlikely to result in jailbreaks. Using tree-of-thought reasoning allows TAP to navigate a large search space of prompts and pruning reduces the total number of queries sent to the target. In empirical evaluations, we observe that TAP generates prompts that jailbreak state-of-the-art LLMs (including GPT4 and GPT4-Turbo) for more than 80% of the prompts using only a small number of queries. This significantly improves upon the previous state-of-the-art black-box method for generating jailbreaks.
Poisoning Web-Scale Training Datasets is Practical
Feb 20, 2023Deep learning models are often trained on distributed, webscale datasets crawled from the internet. In this paper, we introduce two new dataset poisoning attacks that intentionally introduce malicious examples to a model's performance. Our attacks are immediately practical and could, today, poison 10 popular datasets. Our first attack, split-view poisoning, exploits the mutable nature of internet content to ensure a dataset annotator's initial view of the dataset differs from the view downloaded by subsequent clients. By exploiting specific invalid trust assumptions, we show how we could have poisoned 0.01% of the LAION-400M or COYO-700M datasets for just $60 USD. Our second attack, frontrunning poisoning, targets web-scale datasets that periodically snapshot crowd-sourced content -- such as Wikipedia -- where an attacker only needs a time-limited window to inject malicious examples. In light of both attacks, we notify the maintainers of each affected dataset and recommended several low-overhead defenses.
KiloGrams: Very Large N-Grams for Malware Classification
Aug 01, 2019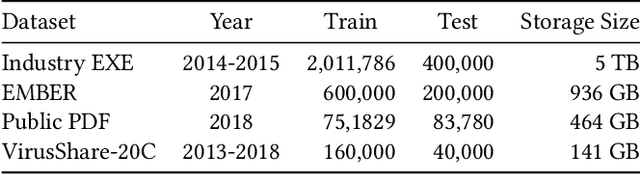
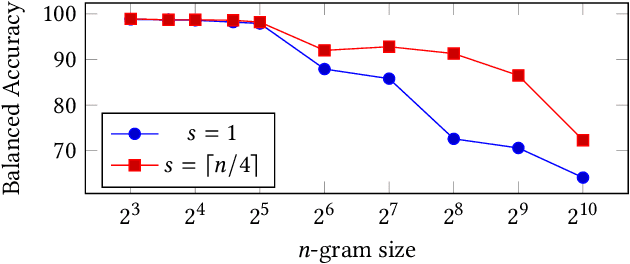
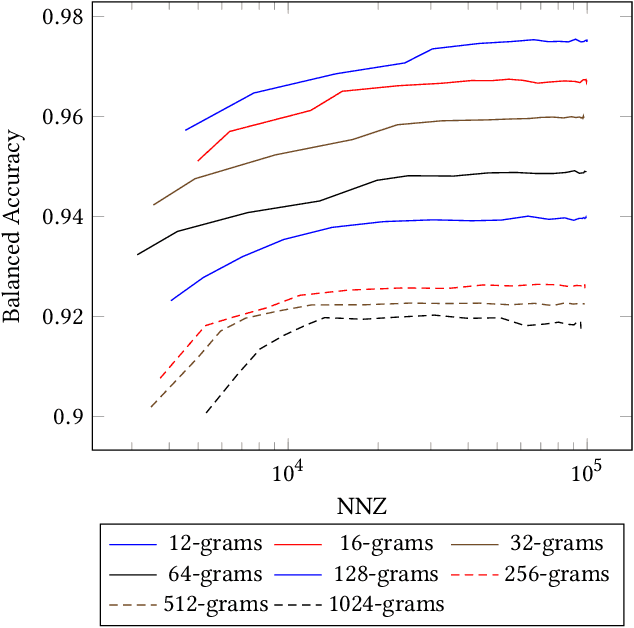
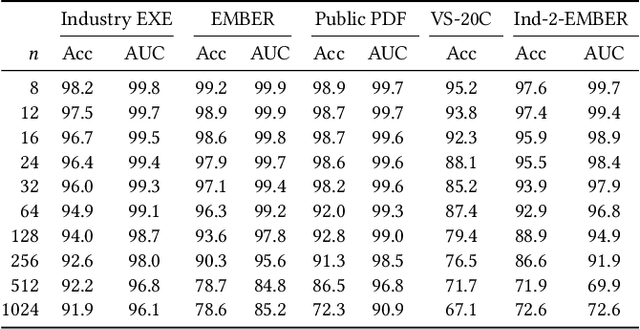
N-grams have been a common tool for information retrieval and machine learning applications for decades. In nearly all previous works, only a few values of $n$ are tested, with $n > 6$ being exceedingly rare. Larger values of $n$ are not tested due to computational burden or the fear of overfitting. In this work, we present a method to find the top-$k$ most frequent $n$-grams that is 60$\times$ faster for small $n$, and can tackle large $n\geq1024$. Despite the unprecedented size of $n$ considered, we show how these features still have predictive ability for malware classification tasks. More important, large $n$-grams provide benefits in producing features that are interpretable by malware analysis, and can be used to create general purpose signatures compatible with industry standard tools like Yara. Furthermore, the counts of common $n$-grams in a file may be added as features to publicly available human-engineered features that rival efficacy of professionally-developed features when used to train gradient-boosted decision tree models on the EMBER dataset.
The Malicious Use of Artificial Intelligence: Forecasting, Prevention, and Mitigation
Feb 20, 2018
This report surveys the landscape of potential security threats from malicious uses of AI, and proposes ways to better forecast, prevent, and mitigate these threats. After analyzing the ways in which AI may influence the threat landscape in the digital, physical, and political domains, we make four high-level recommendations for AI researchers and other stakeholders. We also suggest several promising areas for further research that could expand the portfolio of defenses, or make attacks less effective or harder to execute. Finally, we discuss, but do not conclusively resolve, the long-term equilibrium of attackers and defenders.