 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the Robustness of a Production Malware Detection System to Transferable Adversarial Attacks
Oct 02, 2025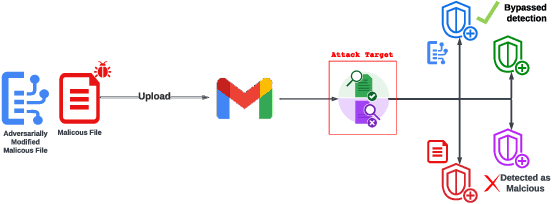
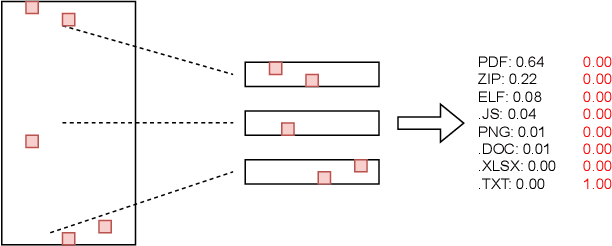
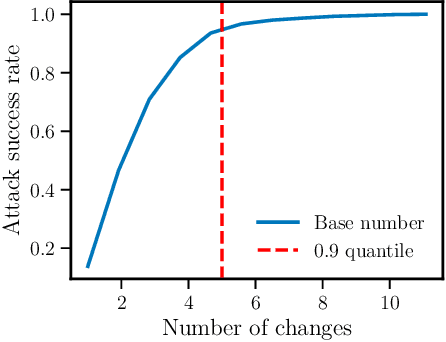
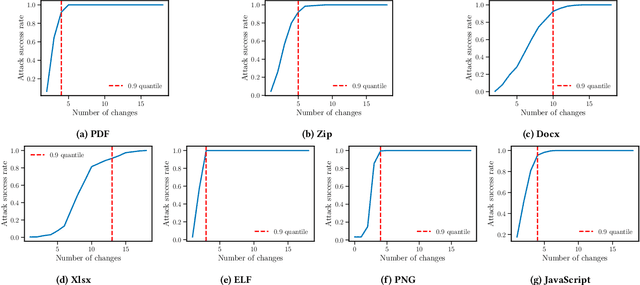
As deep learning models become widely deployed as components within larger production systems, their individual shortcomings can create system-level vulnerabilities with real-world impact. This paper studies how adversarial attacks targeting an ML component can degrade or bypass an entire production-grade malware detection system, performing a case study analysis of Gmail's pipeline where file-type identification relies on a ML model. The malware detection pipeline in use by Gmail contains a machine learning model that routes each potential malware sample to a specialized malware classifier to improve accuracy and performance. This model, called Magika, has been open sourced. By designing adversarial examples that fool Magika, we can cause the production malware service to incorrectly route malware to an unsuitable malware detector thereby increasing our chance of evading detection. Specifically, by changing just 13 bytes of a malware sample, we can successfully evade Magika in 90% of cases and thereby allow us to send malware files over Gmail. We then turn our attention to defenses, and develop an approach to mitigate the severity of these types of attacks. For our defended production model, a highly resourced adversary requires 50 bytes to achieve just a 20% attack success rate. We implement this defense, and, thanks to a collaboration with Google engineers, it has already been deployed in production for the Gmail classifier.
Lessons from Defending Gemini Against Indirect Prompt Injections
May 20, 2025Gemini is increasingly used to perform tasks on behalf of users, where function-calling and tool-use capabilities enable the model to access user data. Some tools, however, require access to untrusted data introducing risk. Adversaries can embed malicious instructions in untrusted data which cause the model to deviate from the user's expectations and mishandle their data or permissions. In this report, we set out Google DeepMind's approach to evaluating the adversarial robustness of Gemini models and describe the main lessons learned from the process. We test how Gemini performs against a sophisticated adversary through an adversarial evaluation framework, which deploys a suite of adaptive attack techniques to run continuously against past, current, and future versions of Gemini. We describe how these ongoing evaluations directly help make Gemini more resilient against manipulation.
Defeating Prompt Injections by Design
Mar 24, 2025Large Language Models (LLMs) are increasingly deployed in agentic systems that interact with an external environment. However, LLM agents are vulnerable to prompt injection attacks when handling untrusted data. In this paper we propose CaMeL, a robust defense that creates a protective system layer around the LLM, securing it even when underlying models may be susceptible to attacks. To operate, CaMeL explicitly extracts the control and data flows from the (trusted) query; therefore, the untrusted data retrieved by the LLM can never impact the program flow. To further improve security, CaMeL relies on a notion of a capability to prevent the exfiltration of private data over unauthorized data flows. We demonstrate effectiveness of CaMeL by solving $67\%$ of tasks with provable security in AgentDojo [NeurIPS 2024], a recent agentic security benchmark.
Machine Unlearning Doesn't Do What You Think: Lessons for Generative AI Policy, Research, and Practice
Dec 09, 2024



We articulate fundamental mismatches between technical methods for machine unlearning in Generative AI, and documented aspirations for broader impact that these methods could have for law and policy. These aspirations are both numerous and varied, motivated by issues that pertain to privacy, copyright, safety, and more. For example, unlearning is often invoked as a solution for removing the effects of targeted information from a generative-AI model's parameters, e.g., a particular individual's personal data or in-copyright expression of Spiderman that was included in the model's training data. Unlearning is also proposed as a way to prevent a model from generating targeted types of information in its outputs, e.g., generations that closely resemble a particular individual's data or reflect the concept of "Spiderman." Both of these goals--the targeted removal of information from a model and the targeted suppression of information from a model's outputs--present various technical and substantive challenges. We provide a framework for thinking rigorously about these challenges, which enables us to be clear about why unlearning is not a general-purpose solution for circumscribing generative-AI model behavior in service of broader positive impact. We aim for conceptual clarity and to encourage more thoughtful communication among machine learning (ML), law, and policy experts who seek to develop and apply technical methods for compliance with policy objectives.
The Last Iterate Advantage: Empirical Auditing and Principled Heuristic Analysis of Differentially Private SGD
Oct 10, 2024We propose a simple heuristic privacy analysis of noisy clipped stochastic gradient descent (DP-SGD) in the setting where only the last iterate is released and the intermediate iterates remain hidden. Namely, our heuristic assumes a linear structure for the model. We show experimentally that our heuristic is predictive of the outcome of privacy auditing applied to various training procedures. Thus it can be used prior to training as a rough estimate of the final privacy leakage. We also probe the limitations of our heuristic by providing some artificial counterexamples where it underestimates the privacy leakage. The standard composition-based privacy analysis of DP-SGD effectively assumes that the adversary has access to all intermediate iterates, which is often unrealistic. However, this analysis remains the state of the art in practice. While our heuristic does not replace a rigorous privacy analysis, it illustrates the large gap between the best theoretical upper bounds and the privacy auditing lower bounds and sets a target for further work to improve the theoretical privacy analyses. We also empirically support our heuristic and show existing privacy auditing attacks are bounded by our heuristic analysis in both vision and language tasks.
Private prediction for large-scale synthetic text generation
Jul 16, 2024We present an approach for generating differentially private synthetic text using large language models (LLMs), via private prediction. In the private prediction framework, we only require the output synthetic data to satisfy differential privacy guarantees. This is in contrast to approaches that train a generative model on potentially sensitive user-supplied source data and seek to ensure the model itself is safe to release. We prompt a pretrained LLM with source data, but ensure that next-token predictions are made with differential privacy guarantees. Previous work in this paradigm reported generating a small number of examples (<10) at reasonable privacy levels, an amount of data that is useful only for downstream in-context learning or prompting. In contrast, we make changes that allow us to generate thousands of high-quality synthetic data points, greatly expanding the set of potential applications. Our improvements come from an improved privacy analysis and a better private selection mechanism, which makes use of the equivalence between the softmax layer for sampling tokens in LLMs and the exponential mechanism. Furthermore, we introduce a novel use of public predictions via the sparse vector technique, in which we do not pay privacy costs for tokens that are predictable without sensitive data; we find this to be particularly effective for structured data.
Harnessing large-language models to generate private synthetic text
Jun 02, 2023
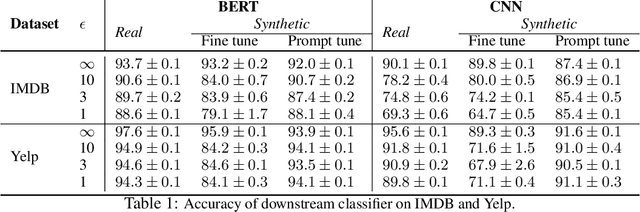


Differentially private (DP) training methods like DP-SGD can protect sensitive training data by ensuring that ML models will not reveal private information. An alternative approach, which this paper studies, is to use a sensitive dataset to generate a new synthetic dataset which is differentially private with respect to the original data. Doing so has several advantages: synthetic data can be reused for other tasks (including for hyper parameter tuning), retained indefinitely, or shared with third parties without sacrificing privacy. However, obtaining DP data is much harder than introducing DP during training. To make it feasible for text, recent work has utilized public data by starting with a pre-trained generative language model and privately finetuning it on sensitive data. This model can be used to sample a DP synthetic dataset. While this strategy seems straightforward, executing it has proven problematic. Previous approaches either show significant performance loss, or have, as we show, critical design flaws. In this paper we demonstrate that a proper training objective along with tuning fewer parameters results in excellent DP synthetic data quality. Our approach is competitive with direct DP-training of downstream classifiers in terms of performance on downstream tasks. We also demonstrate that our DP synthetic data is not only useful for downstream classifier training, but also to tune those same models.
Poisoning Web-Scale Training Datasets is Practical
Feb 20, 2023Deep learning models are often trained on distributed, webscale datasets crawled from the internet. In this paper, we introduce two new dataset poisoning attacks that intentionally introduce malicious examples to a model's performance. Our attacks are immediately practical and could, today, poison 10 popular datasets. Our first attack, split-view poisoning, exploits the mutable nature of internet content to ensure a dataset annotator's initial view of the dataset differs from the view downloaded by subsequent clients. By exploiting specific invalid trust assumptions, we show how we could have poisoned 0.01% of the LAION-400M or COYO-700M datasets for just $60 USD. Our second attack, frontrunning poisoning, targets web-scale datasets that periodically snapshot crowd-sourced content -- such as Wikipedia -- where an attacker only needs a time-limited window to inject malicious examples. In light of both attacks, we notify the maintainers of each affected dataset and recommended several low-overhead defenses.
Tight Auditing of Differentially Private Machine Learning
Feb 15, 2023Auditing mechanisms for differential privacy use probabilistic means to empirically estimate the privacy level of an algorithm. For private machine learning, existing auditing mechanisms are tight: the empirical privacy estimate (nearly) matches the algorithm's provable privacy guarantee. But these auditing techniques suffer from two limitations. First, they only give tight estimates under implausible worst-case assumptions (e.g., a fully adversarial dataset). Second, they require thousands or millions of training runs to produce non-trivial statistical estimates of the privacy leakage. This work addresses both issues. We design an improved auditing scheme that yields tight privacy estimates for natural (not adversarially crafted) datasets -- if the adversary can see all model updates during training. Prior auditing works rely on the same assumption, which is permitted under the standard differential privacy threat model. This threat model is also applicable, e.g., in federated learning settings. Moreover, our auditing scheme requires only two training runs (instead of thousands) to produce tight privacy estimates, by adapting recent advances in tight composition theorems for differential privacy. We demonstrate the utility of our improved auditing schemes by surfacing implementation bugs in private machine learning code that eluded prior auditing techniques.
The Privacy Onion Effect: Memorization is Relative
Jun 22, 2022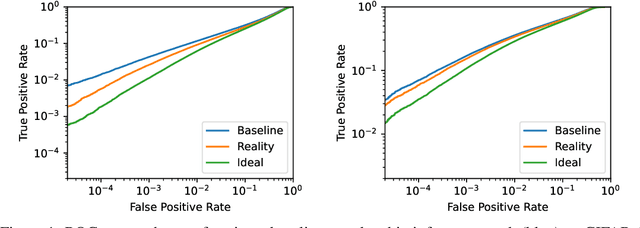
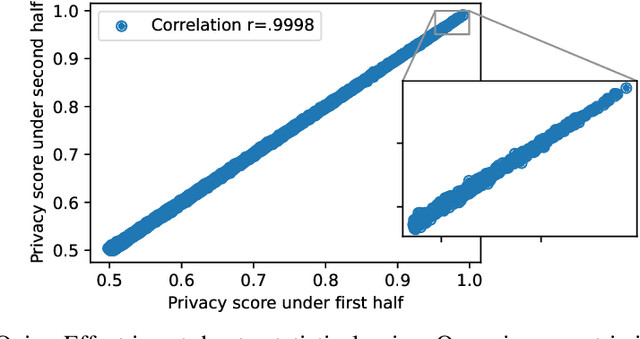
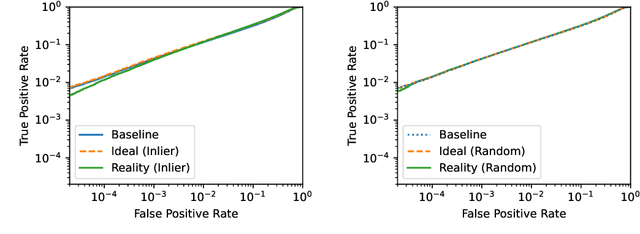
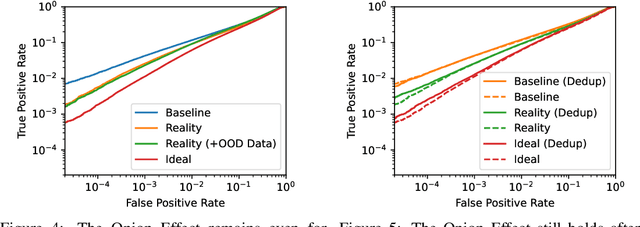
Machine learning models trained on private datasets have been shown to leak their private data. While recent work has found that the average data point is rarely leaked, the outlier samples are frequently subject to memorization and, consequently, privacy leakage. We demonstrate and analyse an Onion Effect of memorization: removing the "layer" of outlier points that are most vulnerable to a privacy attack exposes a new layer of previously-safe points to the same attack. We perform several experiments to study this effect, and understand why it occurs. The existence of this effect has various consequences. For example, it suggests that proposals to defend against memorization without training with rigorous privacy guarantees are unlikely to be effective. Further, it suggests that privacy-enhancing technologies such as machine unlearning could actually harm the privacy of other users.