 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-rithmetic
Feb 11, 2026Modern AI systems have been successfully deployed to win medals at international math competitions, assist with research workflows, and prove novel technical lemmas. However, despite their progress at advanced levels of mathematics, they remain stubbornly bad at basic arithmetic, consistently failing on the simple task of adding two numbers. We present a systematic investigation of this phenomenon. We demonstrate empirically that all frontier models suffer significantly degraded accuracy for integer addition as the number of digits increases. Furthermore, we show that most errors made by these models are highly interpretable and can be attributed to either operand misalignment or a failure to correctly carry; these two error classes explain 87.9%, 62.9%, and 92.4% of Claude Opus 4.1, GPT-5, and Gemini 2.5 Pro errors, respectively. Finally, we show that misalignment errors are frequently related to tokenization, and that carrying errors appear largely as independent random failures.
Learning from Synthetic Data: Limitations of ERM
Jan 21, 2026The prevalence and low cost of LLMs have led to a rise of synthetic content. From review sites to court documents, ``natural'' content has been contaminated by data points that appear similar to natural data, but are in fact LLM-generated. In this work we revisit fundamental learning theory questions in this, now ubiquitous, setting. We model this scenario as a sequence of learning tasks where the input is a mix of natural and synthetic data, and the learning algorithms are oblivious to the origin of any individual example. We study the possibilities and limitations of ERM in this setting. For the problem of estimating the mean of an arbitrary $d$-dimensional distribution, we find that while ERM converges to the true mean, it is outperformed by an algorithm that assigns non-uniform weights to examples from different generations of data. For the PAC learning setting, the disparity is even more stark. We find that ERM does not always converge to the true concept, echoing the model collapse literature. However, we show there are algorithms capable of learning the correct hypothesis for arbitrary VC classes and arbitrary amounts of contamination.
On the Learnability of Distribution Classes with Adaptive Adversaries
Sep 05, 2025We consider the question of learnability of distribution classes in the presence of adaptive adversaries -- that is, adversaries capable of intercepting the samples requested by a learner and applying manipulations with full knowledge of the samples before passing it on to the learner. This stands in contrast to oblivious adversaries, who can only modify the underlying distribution the samples come from but not their i.i.d.\ nature. We formulate a general notion of learnability with respect to adaptive adversaries, taking into account the budget of the adversary. We show that learnability with respect to additive adaptive adversaries is a strictly stronger condition than learnability with respect to additive oblivious adversaries.
Clustering and Median Aggregation Improve Differentially Private Inference
Jun 05, 2025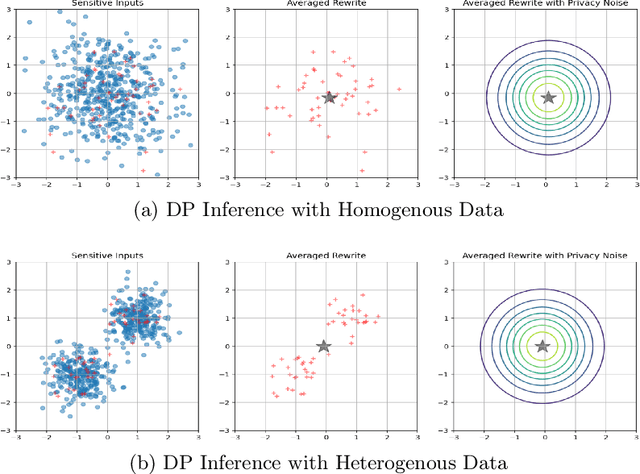

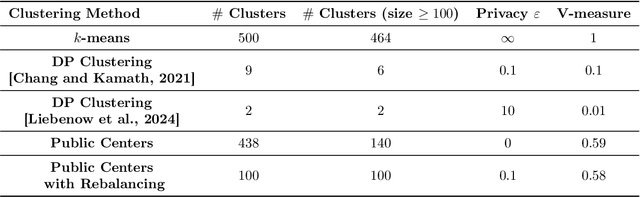
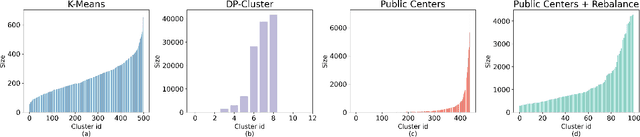
Differentially private (DP) language model inference is an approach for generating private synthetic text. A sensitive input example is used to prompt an off-the-shelf large language model (LLM) to produce a similar example. Multiple examples can be aggregated together to formally satisfy the DP guarantee. Prior work creates inference batches by sampling sensitive inputs uniformly at random. We show that uniform sampling degrades the quality of privately generated text, especially when the sensitive examples concern heterogeneous topics. We remedy this problem by clustering the input data before selecting inference batches. Next, we observe that clustering also leads to more similar next-token predictions across inferences. We use this insight to introduce a new algorithm that aggregates next token statistics by privately computing medians instead of averages. This approach leverages the fact that the median has decreased local sensitivity when next token predictions are similar, allowing us to state a data-dependent and ex-post DP guarantee about the privacy properties of this algorithm. Finally, we demonstrate improvements in terms of representativeness metrics (e.g., MAUVE) as well as downstream task performance. We show that our method produces high-quality synthetic data at significantly lower privacy cost than a previous state-of-the-art method.
Escaping Collapse: The Strength of Weak Data for Large Language Model Training
Feb 13, 2025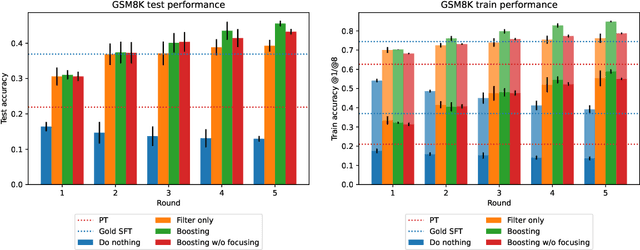
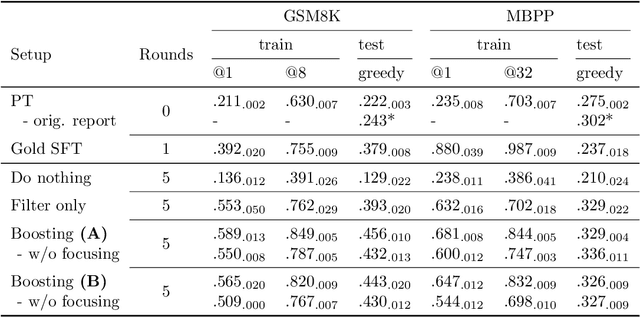
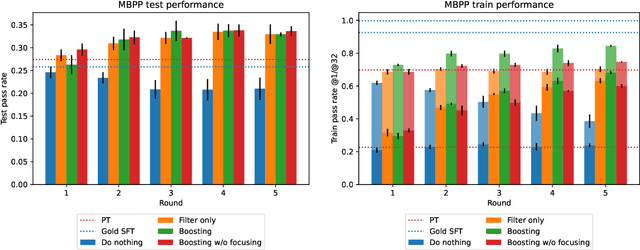
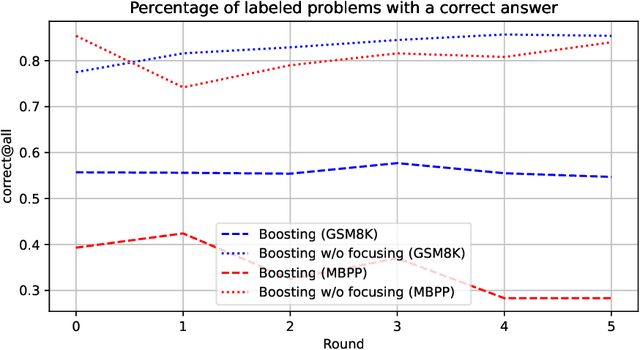
Synthetically-generated data plays an increasingly larger role in training large language models. However, while synthetic data has been found to be useful, studies have also shown that without proper curation it can cause LLM performance to plateau, or even "collapse", after many training iterations. In this paper, we formalize this question and develop a theoretical framework to investigate how much curation is needed in order to ensure that LLM performance continually improves. We find that the requirements are nearly minimal. We describe a training procedure that converges to an optimal LLM even if almost all of the non-synthetic training data is of poor quality. Our analysis is inspired by boosting, a classic machine learning technique that leverages a very weak learning algorithm to produce an arbitrarily good classifier. Our training procedure subsumes many recently proposed methods for training LLMs on synthetic data, and thus our analysis sheds light on why they are successful, and also suggests opportunities for future improvement. We present experiments that validate our theory, and show that dynamically focusing labeling resources on the most challenging examples -- in much the same way that boosting focuses the efforts of the weak learner -- leads to improved performance.
Private prediction for large-scale synthetic text generation
Jul 16, 2024We present an approach for generating differentially private synthetic text using large language models (LLMs), via private prediction. In the private prediction framework, we only require the output synthetic data to satisfy differential privacy guarantees. This is in contrast to approaches that train a generative model on potentially sensitive user-supplied source data and seek to ensure the model itself is safe to release. We prompt a pretrained LLM with source data, but ensure that next-token predictions are made with differential privacy guarantees. Previous work in this paradigm reported generating a small number of examples (<10) at reasonable privacy levels, an amount of data that is useful only for downstream in-context learning or prompting. In contrast, we make changes that allow us to generate thousands of high-quality synthetic data points, greatly expanding the set of potential applications. Our improvements come from an improved privacy analysis and a better private selection mechanism, which makes use of the equivalence between the softmax layer for sampling tokens in LLMs and the exponential mechanism. Furthermore, we introduce a novel use of public predictions via the sparse vector technique, in which we do not pay privacy costs for tokens that are predictable without sensitive data; we find this to be particularly effective for structured data.
Distribution Learnability and Robustness
Jun 25, 2024We examine the relationship between learnability and robust (or agnostic) learnability for the problem of distribution learning. We show that, contrary to other learning settings (e.g., PAC learning of function classes), realizable learnability of a class of probability distributions does not imply its agnostic learnability. We go on to examine what type of data corruption can disrupt the learnability of a distribution class and what is such learnability robust against. We show that realizable learnability of a class of distributions implies its robust learnability with respect to only additive corruption, but not against subtractive corruption. We also explore related implications in the context of compression schemes and differentially private learnability.
Parametric Feature Transfer: One-shot Federated Learning with Foundation Models
Feb 02, 2024In one-shot federated learning (FL), clients collaboratively train a global model in a single round of communication. Existing approaches for one-shot FL enhance communication efficiency at the expense of diminished accuracy. This paper introduces FedPFT (Federated Learning with Parametric Feature Transfer), a methodology that harnesses the transferability of foundation models to enhance both accuracy and communication efficiency in one-shot FL. The approach involves transferring per-client parametric models (specifically, Gaussian mixtures) of features extracted from foundation models. Subsequently, each parametric model is employed to generate synthetic features for training a classifier head. Experimental results on eight datasets demonstrate that FedPFT enhances the communication-accuracy frontier in both centralized and decentralized FL scenarios, as well as across diverse data-heterogeneity settings such as covariate shift and task shift, with improvements of up to 20.6%. Additionally, FedPFT adheres to the data minimization principle of FL, as clients do not send real features. We demonstrate that sending real features is vulnerable to potent reconstruction attacks. Moreover, we show that FedPFT is amenable to formal privacy guarantees via differential privacy, demonstrating favourable privacy-accuracy tradeoffs.
Normalization Is All You Need: Understanding Layer-Normalized Federated Learning under Extreme Label Shift
Aug 18, 2023Layer normalization (LN) is a widely adopted deep learning technique especially in the era of foundation models. Recently, LN has been shown to be surprisingly effective in federated learning (FL) with non-i.i.d. data. However, exactly why and how it works remains mysterious. In this work, we reveal the profound connection between layer normalization and the label shift problem in federated learning. To understand layer normalization better in FL, we identify the key contributing mechanism of normalization methods in FL, called feature normalization (FN), which applies normalization to the latent feature representation before the classifier head. Although LN and FN do not improve expressive power, they control feature collapse and local overfitting to heavily skewed datasets, and thus accelerates global training. Empirically, we show that normalization leads to drastic improvements on standard benchmarks under extreme label shift. Moreover, we conduct extensive ablation studies to understand the critical factors of layer normalization in FL. Our results verify that FN is an essential ingredient inside LN to significantly improve the convergence of FL while remaining robust to learning rate choices, especially under extreme label shift where each client has access to few classes.
Private Distribution Learning with Public Data: The View from Sample Compression
Aug 14, 2023We study the problem of private distribution learning with access to public data. In this setup, which we refer to as public-private learning, the learner is given public and private samples drawn from an unknown distribution $p$ belonging to a class $\mathcal Q$, with the goal of outputting an estimate of $p$ while adhering to privacy constraints (here, pure differential privacy) only with respect to the private samples. We show that the public-private learnability of a class $\mathcal Q$ is connected to the existence of a sample compression scheme for $\mathcal Q$, as well as to an intermediate notion we refer to as list learning. Leveraging this connection: (1) approximately recovers previous results on Gaussians over $\mathbb R^d$; and (2) leads to new ones, including sample complexity upper bounds for arbitrary $k$-mixtures of Gaussians over $\mathbb R^d$, results for agnostic and distribution-shift resistant learners, as well as closure properties for public-private learnability under taking mixtures and products of distributions. Finally, via the connection to list learning, we show that for Gaussians in $\mathbb R^d$, at least $d$ public samples are necessary for private learnability, which is close to the known upper bound of $d+1$ public samples.