 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEscaping Collapse: The Strength of Weak Data for Large Language Model Training
Paper and Code
Feb 13, 2025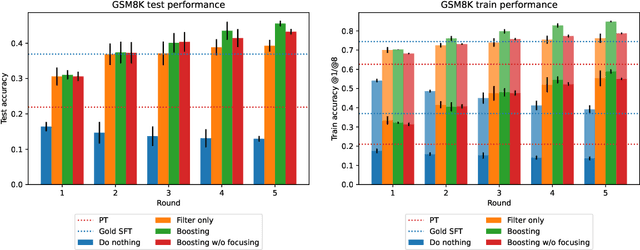
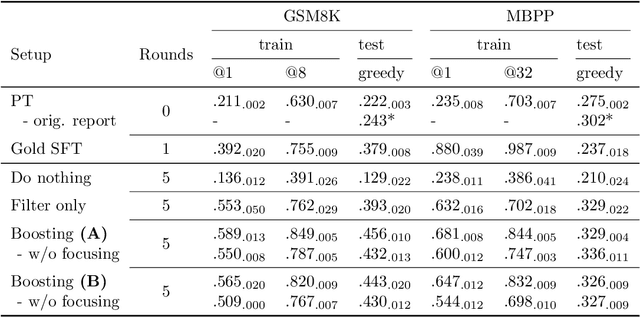
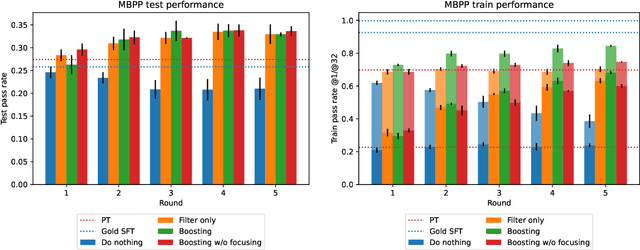
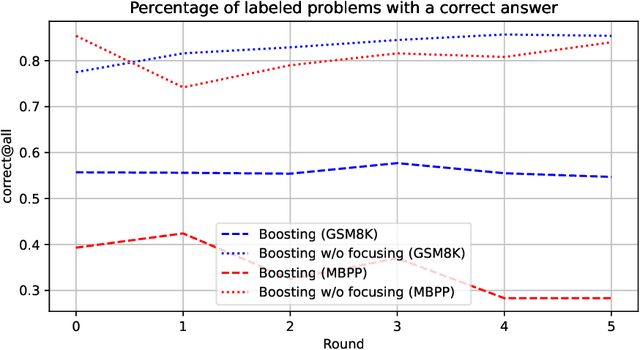
Synthetically-generated data plays an increasingly larger role in training large language models. However, while synthetic data has been found to be useful, studies have also shown that without proper curation it can cause LLM performance to plateau, or even "collapse", after many training iterations. In this paper, we formalize this question and develop a theoretical framework to investigate how much curation is needed in order to ensure that LLM performance continually improves. We find that the requirements are nearly minimal. We describe a training procedure that converges to an optimal LLM even if almost all of the non-synthetic training data is of poor quality. Our analysis is inspired by boosting, a classic machine learning technique that leverages a very weak learning algorithm to produce an arbitrarily good classifier. Our training procedure subsumes many recently proposed methods for training LLMs on synthetic data, and thus our analysis sheds light on why they are successful, and also suggests opportunities for future improvement. We present experiments that validate our theory, and show that dynamically focusing labeling resources on the most challenging examples -- in much the same way that boosting focuses the efforts of the weak learner -- leads to improved performance.