 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Synthetic Data: Limitations of ERM
Jan 21, 2026The prevalence and low cost of LLMs have led to a rise of synthetic content. From review sites to court documents, ``natural'' content has been contaminated by data points that appear similar to natural data, but are in fact LLM-generated. In this work we revisit fundamental learning theory questions in this, now ubiquitous, setting. We model this scenario as a sequence of learning tasks where the input is a mix of natural and synthetic data, and the learning algorithms are oblivious to the origin of any individual example. We study the possibilities and limitations of ERM in this setting. For the problem of estimating the mean of an arbitrary $d$-dimensional distribution, we find that while ERM converges to the true mean, it is outperformed by an algorithm that assigns non-uniform weights to examples from different generations of data. For the PAC learning setting, the disparity is even more stark. We find that ERM does not always converge to the true concept, echoing the model collapse literature. However, we show there are algorithms capable of learning the correct hypothesis for arbitrary VC classes and arbitrary amounts of contamination.
Clustering and Median Aggregation Improve Differentially Private Inference
Jun 05, 2025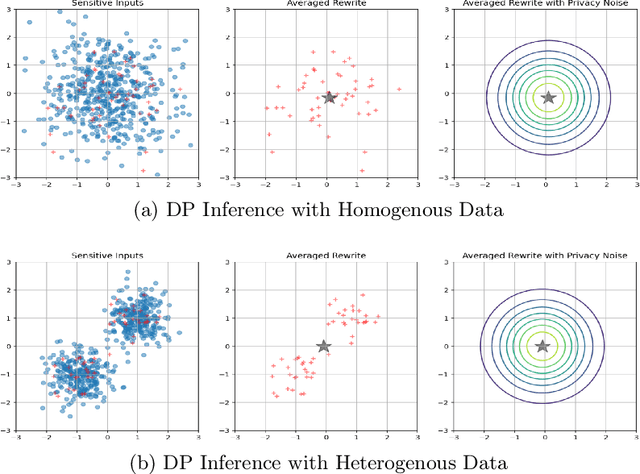

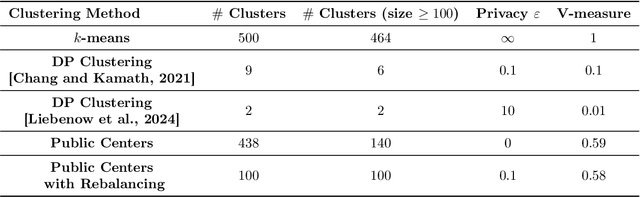
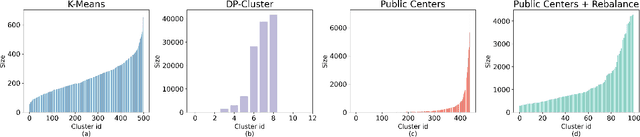
Differentially private (DP) language model inference is an approach for generating private synthetic text. A sensitive input example is used to prompt an off-the-shelf large language model (LLM) to produce a similar example. Multiple examples can be aggregated together to formally satisfy the DP guarantee. Prior work creates inference batches by sampling sensitive inputs uniformly at random. We show that uniform sampling degrades the quality of privately generated text, especially when the sensitive examples concern heterogeneous topics. We remedy this problem by clustering the input data before selecting inference batches. Next, we observe that clustering also leads to more similar next-token predictions across inferences. We use this insight to introduce a new algorithm that aggregates next token statistics by privately computing medians instead of averages. This approach leverages the fact that the median has decreased local sensitivity when next token predictions are similar, allowing us to state a data-dependent and ex-post DP guarantee about the privacy properties of this algorithm. Finally, we demonstrate improvements in terms of representativeness metrics (e.g., MAUVE) as well as downstream task performance. We show that our method produces high-quality synthetic data at significantly lower privacy cost than a previous state-of-the-art method.
Escaping Collapse: The Strength of Weak Data for Large Language Model Training
Feb 13, 2025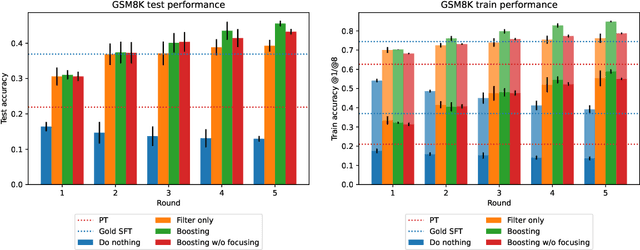
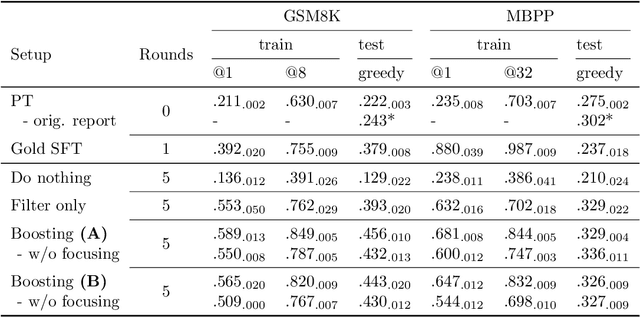
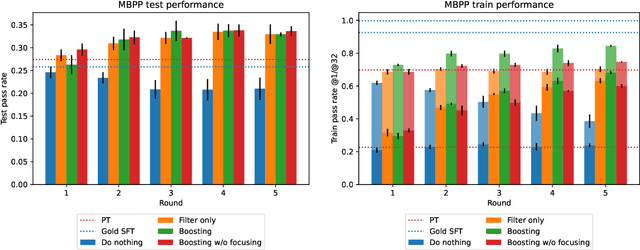
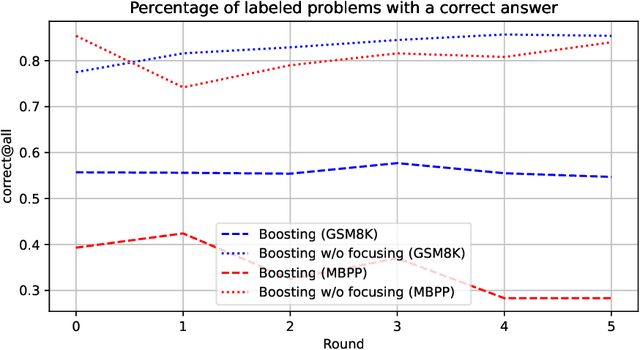
Synthetically-generated data plays an increasingly larger role in training large language models. However, while synthetic data has been found to be useful, studies have also shown that without proper curation it can cause LLM performance to plateau, or even "collapse", after many training iterations. In this paper, we formalize this question and develop a theoretical framework to investigate how much curation is needed in order to ensure that LLM performance continually improves. We find that the requirements are nearly minimal. We describe a training procedure that converges to an optimal LLM even if almost all of the non-synthetic training data is of poor quality. Our analysis is inspired by boosting, a classic machine learning technique that leverages a very weak learning algorithm to produce an arbitrarily good classifier. Our training procedure subsumes many recently proposed methods for training LLMs on synthetic data, and thus our analysis sheds light on why they are successful, and also suggests opportunities for future improvement. We present experiments that validate our theory, and show that dynamically focusing labeling resources on the most challenging examples -- in much the same way that boosting focuses the efforts of the weak learner -- leads to improved performance.
Private prediction for large-scale synthetic text generation
Jul 16, 2024We present an approach for generating differentially private synthetic text using large language models (LLMs), via private prediction. In the private prediction framework, we only require the output synthetic data to satisfy differential privacy guarantees. This is in contrast to approaches that train a generative model on potentially sensitive user-supplied source data and seek to ensure the model itself is safe to release. We prompt a pretrained LLM with source data, but ensure that next-token predictions are made with differential privacy guarantees. Previous work in this paradigm reported generating a small number of examples (<10) at reasonable privacy levels, an amount of data that is useful only for downstream in-context learning or prompting. In contrast, we make changes that allow us to generate thousands of high-quality synthetic data points, greatly expanding the set of potential applications. Our improvements come from an improved privacy analysis and a better private selection mechanism, which makes use of the equivalence between the softmax layer for sampling tokens in LLMs and the exponential mechanism. Furthermore, we introduce a novel use of public predictions via the sparse vector technique, in which we do not pay privacy costs for tokens that are predictable without sensitive data; we find this to be particularly effective for structured data.
Privacy of the last iterate in cyclically-sampled DP-SGD on nonconvex composite losses
Jul 07, 2024
Differentially private stochastic gradient descent (DP-SGD) refers to a family of optimization algorithms that provide a guaranteed level of differential privacy (DP) through DP accounting techniques. However, current accounting techniques make assumptions that diverge significantly from practical DP-SGD implementations. For example, they may assume the loss function is Lipschitz continuous and convex, sample the batches randomly with replacement, or omit the gradient clipping step. In this work, we analyze the most commonly used variant of DP-SGD, in which we sample batches cyclically with replacement, perform gradient clipping, and only release the last DP-SGD iterate. More specifically - without assuming convexity, smoothness, or Lipschitz continuity of the loss function - we establish new R\'enyi differential privacy (RDP) bounds for the last DP-SGD iterate under the mild assumption that (i) the DP-SGD stepsize is small relative to the topological constants in the loss function, and (ii) the loss function is weakly-convex. Moreover, we show that our bounds converge to previously established convex bounds when the weak-convexity parameter of the objective function approaches zero. In the case of non-Lipschitz smooth loss functions, we provide a weaker bound that scales well in terms of the number of DP-SGD iterations.