 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivate prediction for large-scale synthetic text generation
Jul 16, 2024We present an approach for generating differentially private synthetic text using large language models (LLMs), via private prediction. In the private prediction framework, we only require the output synthetic data to satisfy differential privacy guarantees. This is in contrast to approaches that train a generative model on potentially sensitive user-supplied source data and seek to ensure the model itself is safe to release. We prompt a pretrained LLM with source data, but ensure that next-token predictions are made with differential privacy guarantees. Previous work in this paradigm reported generating a small number of examples (<10) at reasonable privacy levels, an amount of data that is useful only for downstream in-context learning or prompting. In contrast, we make changes that allow us to generate thousands of high-quality synthetic data points, greatly expanding the set of potential applications. Our improvements come from an improved privacy analysis and a better private selection mechanism, which makes use of the equivalence between the softmax layer for sampling tokens in LLMs and the exponential mechanism. Furthermore, we introduce a novel use of public predictions via the sparse vector technique, in which we do not pay privacy costs for tokens that are predictable without sensitive data; we find this to be particularly effective for structured data.
Diffusion Denoising as a Certified Defense against Clean-label Poisoning
Mar 18, 2024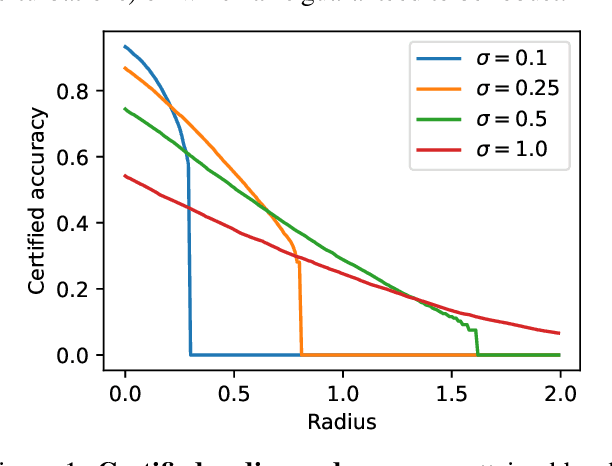



We present a certified defense to clean-label poisoning attacks. These attacks work by injecting a small number of poisoning samples (e.g., 1%) that contain $p$-norm bounded adversarial perturbations into the training data to induce a targeted misclassification of a test-time input. Inspired by the adversarial robustness achieved by $denoised$ $smoothing$, we show how an off-the-shelf diffusion model can sanitize the tampered training data. We extensively test our defense against seven clean-label poisoning attacks and reduce their attack success to 0-16% with only a negligible drop in the test time accuracy. We compare our defense with existing countermeasures against clean-label poisoning, showing that the defense reduces the attack success the most and offers the best model utility. Our results highlight the need for future work on developing stronger clean-label attacks and using our certified yet practical defense as a strong baseline to evaluate these attacks.
DART: A Principled Approach to Adversarially Robust Unsupervised Domain Adaptation
Feb 16, 2024Distribution shifts and adversarial examples are two major challenges for deploying machine learning models. While these challenges have been studied individually, their combination is an important topic that remains relatively under-explored. In this work, we study the problem of adversarial robustness under a common setting of distribution shift - unsupervised domain adaptation (UDA). Specifically, given a labeled source domain $D_S$ and an unlabeled target domain $D_T$ with related but different distributions, the goal is to obtain an adversarially robust model for $D_T$. The absence of target domain labels poses a unique challenge, as conventional adversarial robustness defenses cannot be directly applied to $D_T$. To address this challenge, we first establish a generalization bound for the adversarial target loss, which consists of (i) terms related to the loss on the data, and (ii) a measure of worst-case domain divergence. Motivated by this bound, we develop a novel unified defense framework called Divergence Aware adveRsarial Training (DART), which can be used in conjunction with a variety of standard UDA methods; e.g., DANN [Ganin and Lempitsky, 2015]. DART is applicable to general threat models, including the popular $\ell_p$-norm model, and does not require heuristic regularizers or architectural changes. We also release DomainRobust: a testbed for evaluating robustness of UDA models to adversarial attacks. DomainRobust consists of 4 multi-domain benchmark datasets (with 46 source-target pairs) and 7 meta-algorithms with a total of 11 variants. Our large-scale experiments demonstrate that on average, DART significantly enhances model robustness on all benchmarks compared to the state of the art, while maintaining competitive standard accuracy. The relative improvement in robustness from DART reaches up to 29.2% on the source-target domain pairs considered.
Harnessing large-language models to generate private synthetic text
Jun 02, 2023
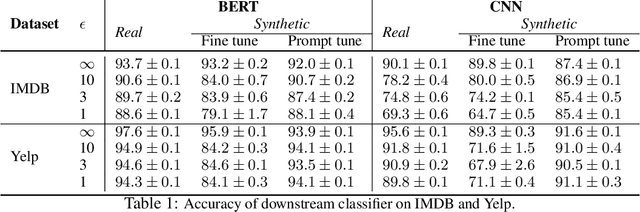


Differentially private (DP) training methods like DP-SGD can protect sensitive training data by ensuring that ML models will not reveal private information. An alternative approach, which this paper studies, is to use a sensitive dataset to generate a new synthetic dataset which is differentially private with respect to the original data. Doing so has several advantages: synthetic data can be reused for other tasks (including for hyper parameter tuning), retained indefinitely, or shared with third parties without sacrificing privacy. However, obtaining DP data is much harder than introducing DP during training. To make it feasible for text, recent work has utilized public data by starting with a pre-trained generative language model and privately finetuning it on sensitive data. This model can be used to sample a DP synthetic dataset. While this strategy seems straightforward, executing it has proven problematic. Previous approaches either show significant performance loss, or have, as we show, critical design flaws. In this paper we demonstrate that a proper training objective along with tuning fewer parameters results in excellent DP synthetic data quality. Our approach is competitive with direct DP-training of downstream classifiers in terms of performance on downstream tasks. We also demonstrate that our DP synthetic data is not only useful for downstream classifier training, but also to tune those same models.
RetVec: Resilient and Efficient Text Vectorizer
Feb 18, 2023This paper describes RetVec, a resilient multilingual embedding scheme designed for neural-based text processing, including small-text classification and large-language models. RetVec combines a novel character encoding with an optional small model to embed words into a 256-dimensional vector space. These embeddings enable training competitive multilingual text models resilient to typos and adversarial attacks. In this paper, we evaluate and compare RetVec to state-of-the-art tokenizers and word embeddings on common model architectures. These comparisons demonstrate that RetVec leads to competitive models that are significantly more resilient to text perturbations across a variety of common tasks. RetVec is available under Apache 2 license at \url{https://github.com/[anonymized]}.
Publishing Efficient On-device Models Increases Adversarial Vulnerability
Dec 28, 2022Recent increases in the computational demands of deep neural networks (DNNs) have sparked interest in efficient deep learning mechanisms, e.g., quantization or pruning. These mechanisms enable the construction of a small, efficient version of commercial-scale models with comparable accuracy, accelerating their deployment to resource-constrained devices. In this paper, we study the security considerations of publishing on-device variants of large-scale models. We first show that an adversary can exploit on-device models to make attacking the large models easier. In evaluations across 19 DNNs, by exploiting the published on-device models as a transfer prior, the adversarial vulnerability of the original commercial-scale models increases by up to 100x. We then show that the vulnerability increases as the similarity between a full-scale and its efficient model increase. Based on the insights, we propose a defense, $similarity$-$unpairing$, that fine-tunes on-device models with the objective of reducing the similarity. We evaluated our defense on all the 19 DNNs and found that it reduces the transferability up to 90% and the number of queries required by a factor of 10-100x. Our results suggest that further research is needed on the security (or even privacy) threats caused by publishing those efficient siblings.
Differentially Private Image Classification from Features
Nov 24, 2022
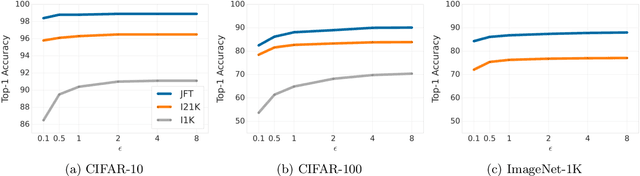
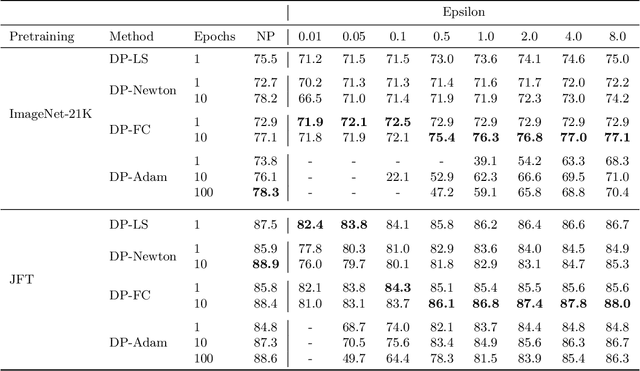
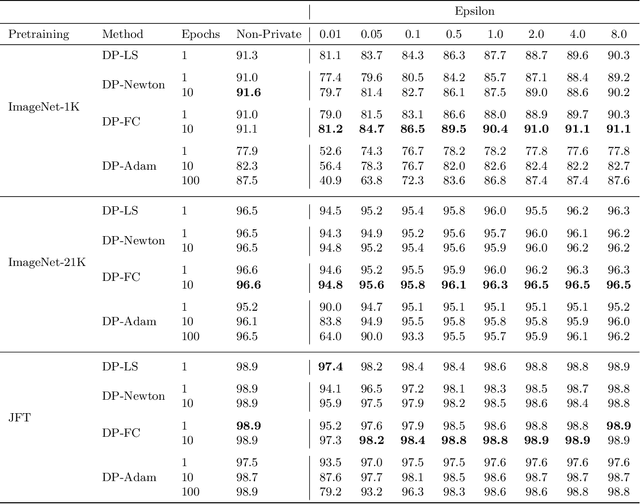
Leveraging transfer learning has recently been shown to be an effective strategy for training large models with Differential Privacy (DP). Moreover, somewhat surprisingly, recent works have found that privately training just the last layer of a pre-trained model provides the best utility with DP. While past studies largely rely on algorithms like DP-SGD for training large models, in the specific case of privately learning from features, we observe that computational burden is low enough to allow for more sophisticated optimization schemes, including second-order methods. To that end, we systematically explore the effect of design parameters such as loss function and optimization algorithm. We find that, while commonly used logistic regression performs better than linear regression in the non-private setting, the situation is reversed in the private setting. We find that linear regression is much more effective than logistic regression from both privacy and computational aspects, especially at stricter epsilon values ($\epsilon < 1$). On the optimization side, we also explore using Newton's method, and find that second-order information is quite helpful even with privacy, although the benefit significantly diminishes with stricter privacy guarantees. While both methods use second-order information, least squares is effective at lower epsilons while Newton's method is effective at larger epsilon values. To combine the benefits of both, we propose a novel algorithm called DP-FC, which leverages feature covariance instead of the Hessian of the logistic regression loss and performs well across all $\epsilon$ values we tried. With this, we obtain new SOTA results on ImageNet-1k, CIFAR-100 and CIFAR-10 across all values of $\epsilon$ typically considered. Most remarkably, on ImageNet-1K, we obtain top-1 accuracy of 88\% under (8, $8 * 10^{-7}$)-DP and 84.3\% under (0.1, $8 * 10^{-7}$)-DP.
Large Scale Transfer Learning for Differentially Private Image Classification
May 06, 2022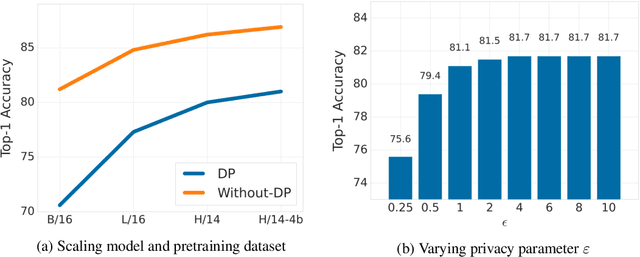
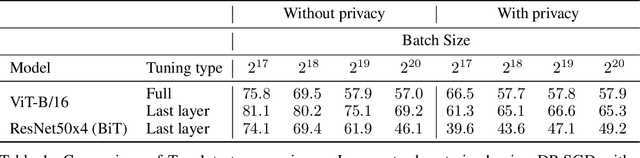
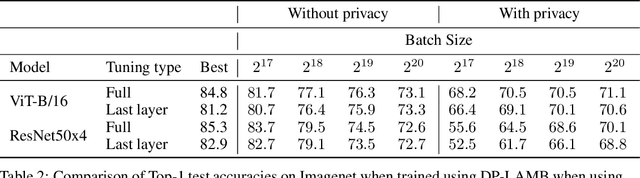
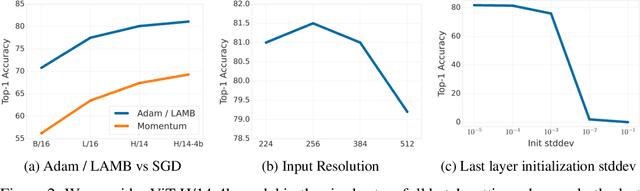
Differential Privacy (DP) provides a formal framework for training machine learning models with individual example level privacy. Training models with DP protects the model against leakage of sensitive data in a potentially adversarial setting. In the field of deep learning, Differentially Private Stochastic Gradient Descent (DP-SGD) has emerged as a popular private training algorithm. Private training using DP-SGD protects against leakage by injecting noise into individual example gradients, such that the trained model weights become nearly independent of the use any particular training example. While this result is quite appealing, the computational cost of training large-scale models with DP-SGD is substantially higher than non-private training. This is further exacerbated by the fact that increasing the number of parameters leads to larger degradation in utility with DP. In this work, we zoom in on the ImageNet dataset and demonstrate that similar to the non-private case, pre-training over-parameterized models on a large public dataset can lead to substantial gains when the model is finetuned privately. Moreover, by systematically comparing private and non-private models across a range of huge batch sizes, we find that similar to non-private setting, choice of optimizer can further improve performance substantially with DP. By switching from DP-SGD to DP-LAMB we saw improvement of up to 20$\%$ points (absolute). Finally, we show that finetuning just the last layer for a \emph{single step} in the full batch setting leads to both SOTA results of 81.7 $\%$ under a wide privacy budget range of $\epsilon \in [4, 10]$ and $\delta$ = $10^{-6}$ while minimizing the computational overhead substantially.
Toward Training at ImageNet Scale with Differential Privacy
Feb 09, 2022
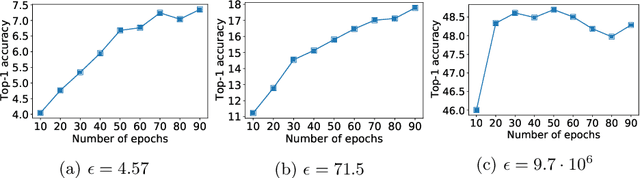
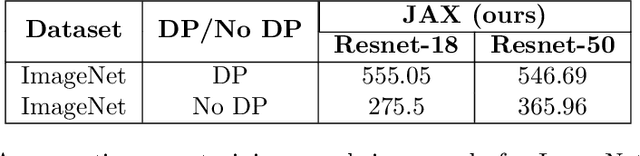
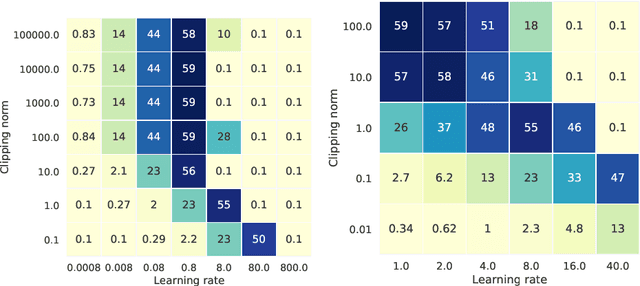
Differential privacy (DP) is the de facto standard for training machine learning (ML) models, including neural networks, while ensuring the privacy of individual examples in the training set. Despite a rich literature on how to train ML models with differential privacy, it remains extremely challenging to train real-life, large neural networks with both reasonable accuracy and privacy. We set out to investigate how to do this, using ImageNet image classification as a poster example of an ML task that is very challenging to resolve accurately with DP right now. This paper shares initial lessons from our effort, in the hope that it will inspire and inform other researchers to explore DP training at scale. We show approaches that help make DP training faster, as well as model types and settings of the training process that tend to work better in the DP setting. Combined, the methods we discuss let us train a Resnet-18 with DP to $47.9\%$ accuracy and privacy parameters $\epsilon = 10, \delta = 10^{-6}$. This is a significant improvement over "naive" DP training of ImageNet models, but a far cry from the $75\%$ accuracy that can be obtained by the same network without privacy. The model we use was pretrained on the Places365 data set as a starting point. We share our code at https://github.com/google-research/dp-imagenet, calling for others to build upon this new baseline to further improve DP at scale.
Handcrafted Backdoors in Deep Neural Networks
Jun 08, 2021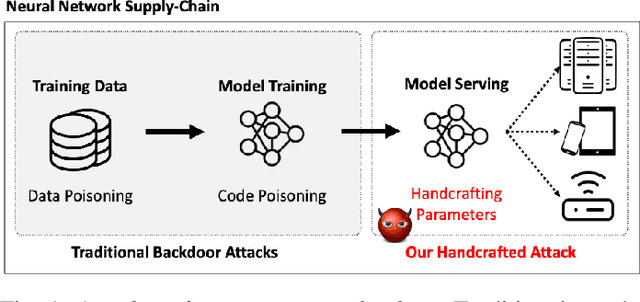
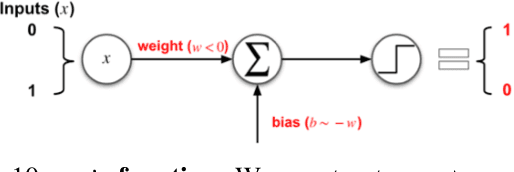

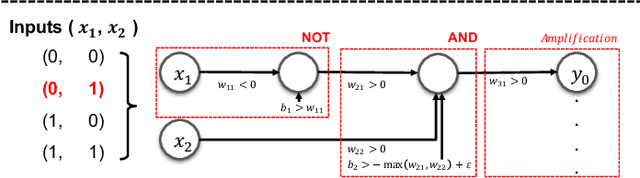
Deep neural networks (DNNs), while accurate, are expensive to train. Many practitioners, therefore, outsource the training process to third parties or use pre-trained DNNs. This practice makes DNNs vulnerable to $backdoor$ $attacks$: the third party who trains the model may act maliciously to inject hidden behaviors into the otherwise accurate model. Until now, the mechanism to inject backdoors has been limited to $poisoning$. We argue that such a supply-chain attacker has more attack techniques available. To study this hypothesis, we introduce a handcrafted attack that directly manipulates the parameters of a pre-trained model to inject backdoors. Our handcrafted attacker has more degrees of freedom in manipulating model parameters than poisoning. This makes it difficult for a defender to identify or remove the manipulations with straightforward methods, such as statistical analysis, adding random noises to model parameters, or clipping their values within a certain range. Further, our attacker can combine the handcrafting process with additional techniques, $e.g.$, jointly optimizing a trigger pattern, to inject backdoors into complex networks effectively$-$the meet-in-the-middle attack. In evaluations, our handcrafted backdoors remain effective across four datasets and four network architectures with a success rate above 96%. Our backdoored models are resilient to both parameter-level backdoor removal techniques and can evade existing defenses by slightly changing the backdoor attack configurations. Moreover, we demonstrate the feasibility of suppressing unwanted behaviors otherwise caused by poisoning. Our results suggest that further research is needed for understanding the complete space of supply-chain backdoor attacks.