 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn The Statistical Complexity of Offline Decision-Making
Jan 10, 2025We study the statistical complexity of offline decision-making with function approximation, establishing (near) minimax-optimal rates for stochastic contextual bandits and Markov decision processes. The performance limits are captured by the pseudo-dimension of the (value) function class and a new characterization of the behavior policy that \emph{strictly} subsumes all the previous notions of data coverage in the offline decision-making literature. In addition, we seek to understand the benefits of using offline data in online decision-making and show nearly minimax-optimal rates in a wide range of regimes.
Learning in Markov Games with Adaptive Adversaries: Policy Regret, Fundamental Barriers, and Efficient Algorithms
Nov 01, 2024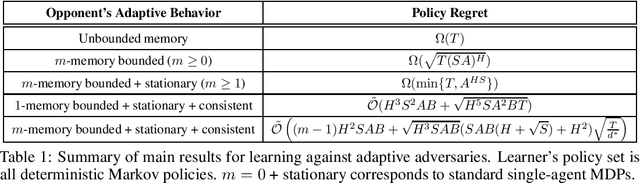
We study learning in a dynamically evolving environment modeled as a Markov game between a learner and a strategic opponent that can adapt to the learner's strategies. While most existing works in Markov games focus on external regret as the learning objective, external regret becomes inadequate when the adversaries are adaptive. In this work, we focus on \emph{policy regret} -- a counterfactual notion that aims to compete with the return that would have been attained if the learner had followed the best fixed sequence of policy, in hindsight. We show that if the opponent has unbounded memory or if it is non-stationary, then sample-efficient learning is not possible. For memory-bounded and stationary, we show that learning is still statistically hard if the set of feasible strategies for the learner is exponentially large. To guarantee learnability, we introduce a new notion of \emph{consistent} adaptive adversaries, wherein, the adversary responds similarly to similar strategies of the learner. We provide algorithms that achieve $\sqrt{T}$ policy regret against memory-bounded, stationary, and consistent adversaries.
Offline Multitask Representation Learning for Reinforcement Learning
Mar 18, 2024
We study offline multitask representation learning in reinforcement learning (RL), where a learner is provided with an offline dataset from different tasks that share a common representation and is asked to learn the shared representation. We theoretically investigate offline multitask low-rank RL, and propose a new algorithm called MORL for offline multitask representation learning. Furthermore, we examine downstream RL in reward-free, offline and online scenarios, where a new task is introduced to the agent that shares the same representation as the upstream offline tasks. Our theoretical results demonstrate the benefits of using the learned representation from the upstream offline task instead of directly learning the representation of the low-rank model.
Public-data Assisted Private Stochastic Optimization: Power and Limitations
Mar 06, 2024We study the limits and capability of public-data assisted differentially private (PA-DP) algorithms. Specifically, we focus on the problem of stochastic convex optimization (SCO) with either labeled or unlabeled public data. For complete/labeled public data, we show that any $(\epsilon,\delta)$-PA-DP has excess risk $\tilde{\Omega}\big(\min\big\{\frac{1}{\sqrt{n_{\text{pub}}}},\frac{1}{\sqrt{n}}+\frac{\sqrt{d}}{n\epsilon} \big\} \big)$, where $d$ is the dimension, ${n_{\text{pub}}}$ is the number of public samples, ${n_{\text{priv}}}$ is the number of private samples, and $n={n_{\text{pub}}}+{n_{\text{priv}}}$. These lower bounds are established via our new lower bounds for PA-DP mean estimation, which are of a similar form. Up to constant factors, these lower bounds show that the simple strategy of either treating all data as private or discarding the private data, is optimal. We also study PA-DP supervised learning with \textit{unlabeled} public samples. In contrast to our previous result, we here show novel methods for leveraging public data in private supervised learning. For generalized linear models (GLM) with unlabeled public data, we show an efficient algorithm which, given $\tilde{O}({n_{\text{priv}}}\epsilon)$ unlabeled public samples, achieves the dimension independent rate $\tilde{O}\big(\frac{1}{\sqrt{{n_{\text{priv}}}}} + \frac{1}{\sqrt{{n_{\text{priv}}}\epsilon}}\big)$. We develop new lower bounds for this setting which shows that this rate cannot be improved with more public samples, and any fewer public samples leads to a worse rate. Finally, we provide extensions of this result to general hypothesis classes with finite fat-shattering dimension with applications to neural networks and non-Euclidean geometries.
DART: A Principled Approach to Adversarially Robust Unsupervised Domain Adaptation
Feb 16, 2024Distribution shifts and adversarial examples are two major challenges for deploying machine learning models. While these challenges have been studied individually, their combination is an important topic that remains relatively under-explored. In this work, we study the problem of adversarial robustness under a common setting of distribution shift - unsupervised domain adaptation (UDA). Specifically, given a labeled source domain $D_S$ and an unlabeled target domain $D_T$ with related but different distributions, the goal is to obtain an adversarially robust model for $D_T$. The absence of target domain labels poses a unique challenge, as conventional adversarial robustness defenses cannot be directly applied to $D_T$. To address this challenge, we first establish a generalization bound for the adversarial target loss, which consists of (i) terms related to the loss on the data, and (ii) a measure of worst-case domain divergence. Motivated by this bound, we develop a novel unified defense framework called Divergence Aware adveRsarial Training (DART), which can be used in conjunction with a variety of standard UDA methods; e.g., DANN [Ganin and Lempitsky, 2015]. DART is applicable to general threat models, including the popular $\ell_p$-norm model, and does not require heuristic regularizers or architectural changes. We also release DomainRobust: a testbed for evaluating robustness of UDA models to adversarial attacks. DomainRobust consists of 4 multi-domain benchmark datasets (with 46 source-target pairs) and 7 meta-algorithms with a total of 11 variants. Our large-scale experiments demonstrate that on average, DART significantly enhances model robustness on all benchmarks compared to the state of the art, while maintaining competitive standard accuracy. The relative improvement in robustness from DART reaches up to 29.2% on the source-target domain pairs considered.
On Sample-Efficient Offline Reinforcement Learning: Data Diversity, Posterior Sampling, and Beyond
Jan 06, 2024We seek to understand what facilitates sample-efficient learning from historical datasets for sequential decision-making, a problem that is popularly known as offline reinforcement learning (RL). Further, we are interested in algorithms that enjoy sample efficiency while leveraging (value) function approximation. In this paper, we address these fundamental questions by (i) proposing a notion of data diversity that subsumes the previous notions of coverage measures in offline RL and (ii) using this notion to {unify} three distinct classes of offline RL algorithms based on version spaces (VS), regularized optimization (RO), and posterior sampling (PS). We establish that VS-based, RO-based, and PS-based algorithms, under standard assumptions, achieve \emph{comparable} sample efficiency, which recovers the state-of-the-art sub-optimality bounds for finite and linear model classes with the standard assumptions. This result is surprising, given that the prior work suggested an unfavorable sample complexity of the RO-based algorithm compared to the VS-based algorithm, whereas posterior sampling is rarely considered in offline RL due to its explorative nature. Notably, our proposed model-free PS-based algorithm for offline RL is {novel}, with sub-optimality bounds that are {frequentist} (i.e., worst-case) in nature.
Differentially Private Non-Convex Optimization under the KL Condition with Optimal Rates
Nov 22, 2023We study private empirical risk minimization (ERM) problem for losses satisfying the $(\gamma,\kappa)$-Kurdyka-{\L}ojasiewicz (KL) condition. The Polyak-{\L}ojasiewicz (PL) condition is a special case of this condition when $\kappa=2$. Specifically, we study this problem under the constraint of $\rho$ zero-concentrated differential privacy (zCDP). When $\kappa\in[1,2]$ and the loss function is Lipschitz and smooth over a sufficiently large region, we provide a new algorithm based on variance reduced gradient descent that achieves the rate $\tilde{O}\big(\big(\frac{\sqrt{d}}{n\sqrt{\rho}}\big)^\kappa\big)$ on the excess empirical risk, where $n$ is the dataset size and $d$ is the dimension. We further show that this rate is nearly optimal. When $\kappa \geq 2$ and the loss is instead Lipschitz and weakly convex, we show it is possible to achieve the rate $\tilde{O}\big(\big(\frac{\sqrt{d}}{n\sqrt{\rho}}\big)^\kappa\big)$ with a private implementation of the proximal point method. When the KL parameters are unknown, we provide a novel modification and analysis of the noisy gradient descent algorithm and show that this algorithm achieves a rate of $\tilde{O}\big(\big(\frac{\sqrt{d}}{n\sqrt{\rho}}\big)^{\frac{2\kappa}{4-\kappa}}\big)$ adaptively, which is nearly optimal when $\kappa = 2$. We further show that, without assuming the KL condition, the same gradient descent algorithm can achieve fast convergence to a stationary point when the gradient stays sufficiently large during the run of the algorithm. Specifically, we show that this algorithm can approximate stationary points of Lipschitz, smooth (and possibly nonconvex) objectives with rate as fast as $\tilde{O}\big(\frac{\sqrt{d}}{n\sqrt{\rho}}\big)$ and never worse than $\tilde{O}\big(\big(\frac{\sqrt{d}}{n\sqrt{\rho}}\big)^{1/2}\big)$. The latter rate matches the best known rate for methods that do not rely on variance reduction.
From Adaptive Query Release to Machine Unlearning
Jul 20, 2023We formalize the problem of machine unlearning as design of efficient unlearning algorithms corresponding to learning algorithms which perform a selection of adaptive queries from structured query classes. We give efficient unlearning algorithms for linear and prefix-sum query classes. As applications, we show that unlearning in many problems, in particular, stochastic convex optimization (SCO), can be reduced to the above, yielding improved guarantees for the problem. In particular, for smooth Lipschitz losses and any $\rho>0$, our results yield an unlearning algorithm with excess population risk of $\tilde O\big(\frac{1}{\sqrt{n}}+\frac{\sqrt{d}}{n\rho}\big)$ with unlearning query (gradient) complexity $\tilde O(\rho \cdot \text{Retraining Complexity})$, where $d$ is the model dimensionality and $n$ is the initial number of samples. For non-smooth Lipschitz losses, we give an unlearning algorithm with excess population risk $\tilde O\big(\frac{1}{\sqrt{n}}+\big(\frac{\sqrt{d}}{n\rho}\big)^{1/2}\big)$ with the same unlearning query (gradient) complexity. Furthermore, in the special case of Generalized Linear Models (GLMs), such as those in linear and logistic regression, we get dimension-independent rates of $\tilde O\big(\frac{1}{\sqrt{n}} +\frac{1}{(n\rho)^{2/3}}\big)$ and $\tilde O\big(\frac{1}{\sqrt{n}} +\frac{1}{(n\rho)^{1/3}}\big)$ for smooth Lipschitz and non-smooth Lipschitz losses respectively. Finally, we give generalizations of the above from one unlearning request to \textit{dynamic} streams consisting of insertions and deletions.
VIPeR: Provably Efficient Algorithm for Offline RL with Neural Function Approximation
Mar 04, 2023


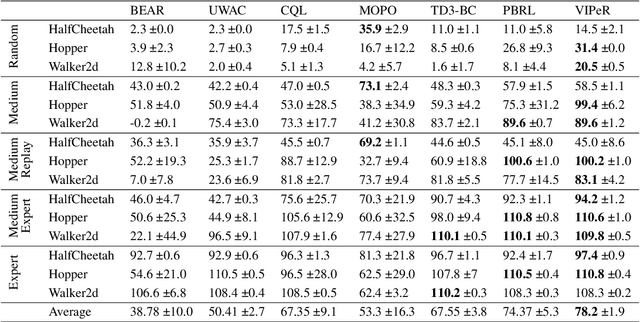
We propose a novel algorithm for offline reinforcement learning called Value Iteration with Perturbed Rewards (VIPeR), which amalgamates the pessimism principle with random perturbations of the value function. Most current offline RL algorithms explicitly construct statistical confidence regions to obtain pessimism via lower confidence bounds (LCB), which cannot easily scale to complex problems where a neural network is used to estimate the value functions. Instead, VIPeR implicitly obtains pessimism by simply perturbing the offline data multiple times with carefully-designed i.i.d. Gaussian noises to learn an ensemble of estimated state-action {value functions} and acting greedily with respect to the minimum of the ensemble. The estimated state-action values are obtained by fitting a parametric model (e.g., neural networks) to the perturbed datasets using gradient descent. As a result, VIPeR only needs $\mathcal{O}(1)$ time complexity for action selection, while LCB-based algorithms require at least $\Omega(K^2)$, where $K$ is the total number of trajectories in the offline data. We also propose a novel data-splitting technique that helps remove a factor involving the log of the covering number in our bound. We prove that VIPeR yields a provable uncertainty quantifier with overparameterized neural networks and enjoys a bound on sub-optimality of $\tilde{\mathcal{O}}( { \kappa H^{5/2} \tilde{d} }/{\sqrt{K}})$, where $\tilde{d}$ is the effective dimension, $H$ is the horizon length and $\kappa$ measures the distributional shift. We corroborate the statistical and computational efficiency of VIPeR with an empirical evaluation on a wide set of synthetic and real-world datasets. To the best of our knowledge, VIPeR is the first algorithm for offline RL that is provably efficient for general Markov decision processes (MDPs) with neural network function approximation.
On Instance-Dependent Bounds for Offline Reinforcement Learning with Linear Function Approximation
Nov 23, 2022
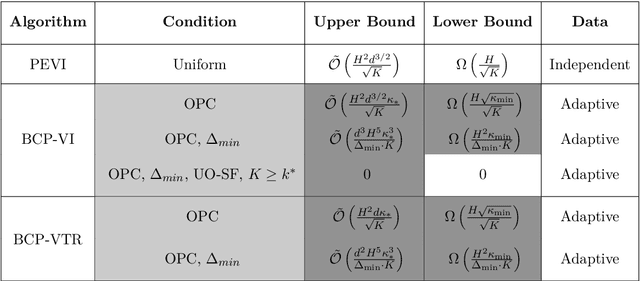


Sample-efficient offline reinforcement learning (RL) with linear function approximation has recently been studied extensively. Much of prior work has yielded the minimax-optimal bound of $\tilde{\mathcal{O}}(\frac{1}{\sqrt{K}})$, with $K$ being the number of episodes in the offline data. In this work, we seek to understand instance-dependent bounds for offline RL with function approximation. We present an algorithm called Bootstrapped and Constrained Pessimistic Value Iteration (BCP-VI), which leverages data bootstrapping and constrained optimization on top of pessimism. We show that under a partial data coverage assumption, that of \emph{concentrability} with respect to an optimal policy, the proposed algorithm yields a fast rate of $\tilde{\mathcal{O}}(\frac{1}{K})$ for offline RL when there is a positive gap in the optimal Q-value functions, even when the offline data were adaptively collected. Moreover, when the linear features of the optimal actions in the states reachable by an optimal policy span those reachable by the behavior policy and the optimal actions are unique, offline RL achieves absolute zero sub-optimality error when $K$ exceeds a (finite) instance-dependent threshold. To the best of our knowledge, these are the first $\tilde{\mathcal{O}}(\frac{1}{K})$ bound and absolute zero sub-optimality bound respectively for offline RL with linear function approximation from adaptive data with partial coverage. We also provide instance-agnostic and instance-dependent information-theoretical lower bounds to complement our upper bounds.