 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Domain Generalization with Latent Space Inversion
Dec 11, 2025Federated domain generalization (FedDG) addresses distribution shifts among clients in a federated learning framework. FedDG methods aggregate the parameters of locally trained client models to form a global model that generalizes to unseen clients while preserving data privacy. While improving the generalization capability of the global model, many existing approaches in FedDG jeopardize privacy by sharing statistics of client data between themselves. Our solution addresses this problem by contributing new ways to perform local client training and model aggregation. To improve local client training, we enforce (domain) invariance across local models with the help of a novel technique, \textbf{latent space inversion}, which enables better client privacy. When clients are not \emph{i.i.d}, aggregating their local models may discard certain local adaptations. To overcome this, we propose an \textbf{important weight} aggregation strategy to prioritize parameters that significantly influence predictions of local models during aggregation. Our extensive experiments show that our approach achieves superior results over state-of-the-art methods with less communication overhead.
S-Chain: Structured Visual Chain-of-Thought For Medicine
Oct 26, 2025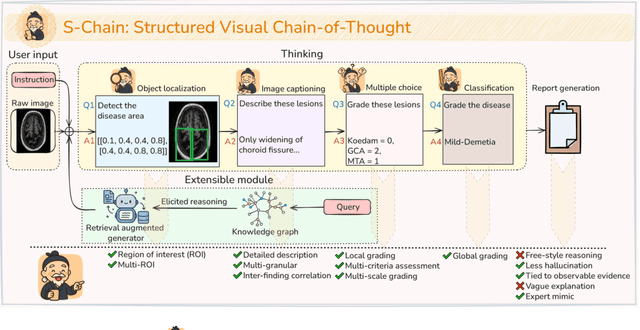
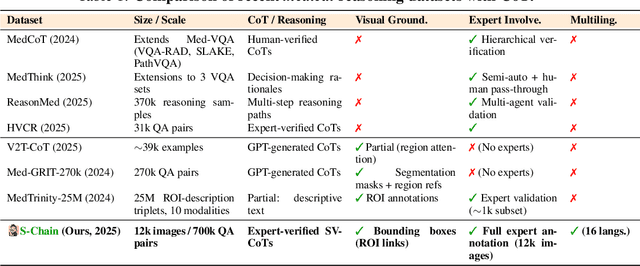
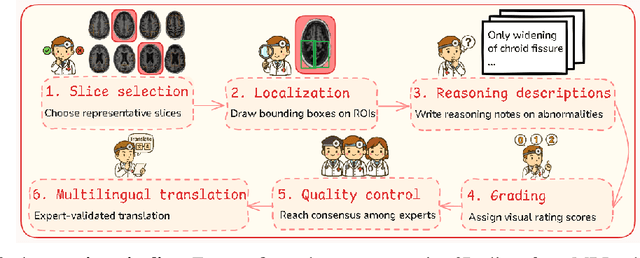
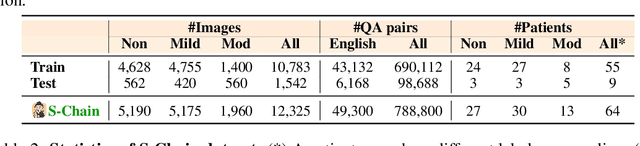
Faithful reasoning in medical vision-language models (VLMs) requires not only accurate predictions but also transparent alignment between textual rationales and visual evidence. While Chain-of-Thought (CoT) prompting has shown promise in medical visual question answering (VQA), no large-scale expert-level dataset has captured stepwise reasoning with precise visual grounding. We introduce S-Chain, the first large-scale dataset of 12,000 expert-annotated medical images with bounding boxes and structured visual CoT (SV-CoT), explicitly linking visual regions to reasoning steps. The dataset further supports 16 languages, totaling over 700k VQA pairs for broad multilingual applicability. Using S-Chain, we benchmark state-of-the-art medical VLMs (ExGra-Med, LLaVA-Med) and general-purpose VLMs (Qwen2.5-VL, InternVL2.5), showing that SV-CoT supervision significantly improves interpretability, grounding fidelity, and robustness. Beyond benchmarking, we study its synergy with retrieval-augmented generation, revealing how domain knowledge and visual grounding interact during autoregressive reasoning. Finally, we propose a new mechanism that strengthens the alignment between visual evidence and reasoning, improving both reliability and efficiency. S-Chain establishes a new benchmark for grounded medical reasoning and paves the way toward more trustworthy and explainable medical VLMs.
One-Layer Transformers are Provably Optimal for In-context Reasoning and Distributional Association Learning in Next-Token Prediction Tasks
May 21, 2025We study the approximation capabilities and on-convergence behaviors of one-layer transformers on the noiseless and noisy in-context reasoning of next-token prediction. Existing theoretical results focus on understanding the in-context reasoning behaviors for either the first gradient step or when the number of samples is infinite. Furthermore, no convergence rates nor generalization abilities were known. Our work addresses these gaps by showing that there exists a class of one-layer transformers that are provably Bayes-optimal with both linear and ReLU attention. When being trained with gradient descent, we show via a finite-sample analysis that the expected loss of these transformers converges at linear rate to the Bayes risk. Moreover, we prove that the trained models generalize to unseen samples as well as exhibit learning behaviors that were empirically observed in previous works. Our theoretical findings are further supported by extensive empirical validations.
MultiMed-ST: Large-scale Many-to-many Multilingual Medical Speech Translation
Apr 04, 2025Multilingual speech translation (ST) in the medical domain enhances patient care by enabling efficient communication across language barriers, alleviating specialized workforce shortages, and facilitating improved diagnosis and treatment, particularly during pandemics. In this work, we present the first systematic study on medical ST, to our best knowledge, by releasing MultiMed-ST, a large-scale ST dataset for the medical domain, spanning all translation directions in five languages: Vietnamese, English, German, French, Traditional Chinese and Simplified Chinese, together with the models. With 290,000 samples, our dataset is the largest medical machine translation (MT) dataset and the largest many-to-many multilingual ST among all domains. Secondly, we present the most extensive analysis study in ST research to date, including: empirical baselines, bilingual-multilingual comparative study, end-to-end vs. cascaded comparative study, task-specific vs. multi-task sequence-to-sequence (seq2seq) comparative study, code-switch analysis, and quantitative-qualitative error analysis. All code, data, and models are available online: https://github.com/leduckhai/MultiMed-ST.
Neural ODE Transformers: Analyzing Internal Dynamics and Adaptive Fine-tuning
Mar 03, 2025Recent advancements in large language models (LLMs) based on transformer architectures have sparked significant interest in understanding their inner workings. In this paper, we introduce a novel approach to modeling transformer architectures using highly flexible non-autonomous neural ordinary differential equations (ODEs). Our proposed model parameterizes all weights of attention and feed-forward blocks through neural networks, expressing these weights as functions of a continuous layer index. Through spectral analysis of the model's dynamics, we uncover an increase in eigenvalue magnitude that challenges the weight-sharing assumption prevalent in existing theoretical studies. We also leverage the Lyapunov exponent to examine token-level sensitivity, enhancing model interpretability. Our neural ODE transformer demonstrates performance comparable to or better than vanilla transformers across various configurations and datasets, while offering flexible fine-tuning capabilities that can adapt to different architectural constraints.
On The Statistical Complexity of Offline Decision-Making
Jan 10, 2025We study the statistical complexity of offline decision-making with function approximation, establishing (near) minimax-optimal rates for stochastic contextual bandits and Markov decision processes. The performance limits are captured by the pseudo-dimension of the (value) function class and a new characterization of the behavior policy that \emph{strictly} subsumes all the previous notions of data coverage in the offline decision-making literature. In addition, we seek to understand the benefits of using offline data in online decision-making and show nearly minimax-optimal rates in a wide range of regimes.
Learning in Markov Games with Adaptive Adversaries: Policy Regret, Fundamental Barriers, and Efficient Algorithms
Nov 01, 2024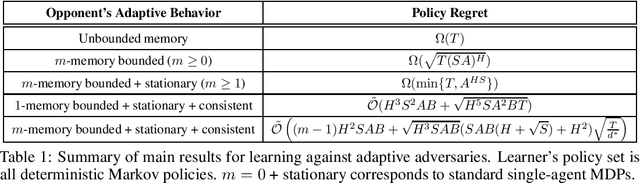
We study learning in a dynamically evolving environment modeled as a Markov game between a learner and a strategic opponent that can adapt to the learner's strategies. While most existing works in Markov games focus on external regret as the learning objective, external regret becomes inadequate when the adversaries are adaptive. In this work, we focus on \emph{policy regret} -- a counterfactual notion that aims to compete with the return that would have been attained if the learner had followed the best fixed sequence of policy, in hindsight. We show that if the opponent has unbounded memory or if it is non-stationary, then sample-efficient learning is not possible. For memory-bounded and stationary, we show that learning is still statistically hard if the set of feasible strategies for the learner is exponentially large. To guarantee learnability, we introduce a new notion of \emph{consistent} adaptive adversaries, wherein, the adversary responds similarly to similar strategies of the learner. We provide algorithms that achieve $\sqrt{T}$ policy regret against memory-bounded, stationary, and consistent adversaries.
Wicked Oddities: Selectively Poisoning for Effective Clean-Label Backdoor Attacks
Jul 16, 2024
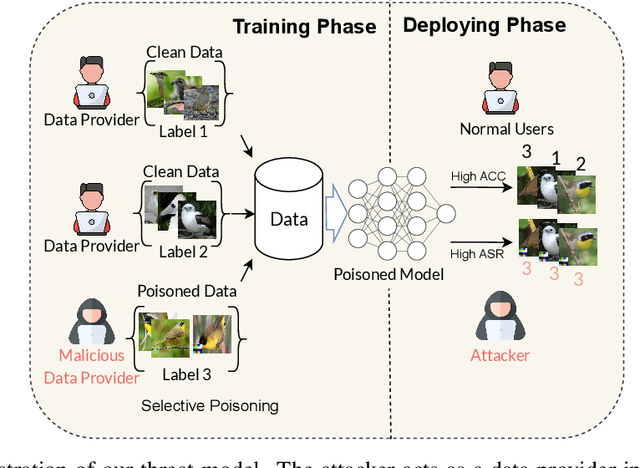
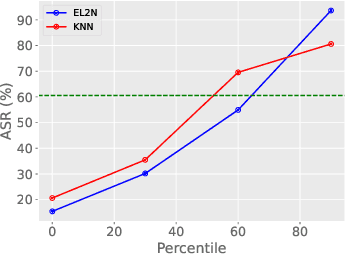
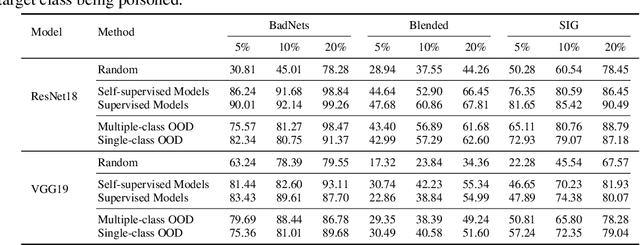
Deep neural networks are vulnerable to backdoor attacks, a type of adversarial attack that poisons the training data to manipulate the behavior of models trained on such data. Clean-label attacks are a more stealthy form of backdoor attacks that can perform the attack without changing the labels of poisoned data. Early works on clean-label attacks added triggers to a random subset of the training set, ignoring the fact that samples contribute unequally to the attack's success. This results in high poisoning rates and low attack success rates. To alleviate the problem, several supervised learning-based sample selection strategies have been proposed. However, these methods assume access to the entire labeled training set and require training, which is expensive and may not always be practical. This work studies a new and more practical (but also more challenging) threat model where the attacker only provides data for the target class (e.g., in face recognition systems) and has no knowledge of the victim model or any other classes in the training set. We study different strategies for selectively poisoning a small set of training samples in the target class to boost the attack success rate in this setting. Our threat model poses a serious threat in training machine learning models with third-party datasets, since the attack can be performed effectively with limited information. Experiments on benchmark datasets illustrate the effectiveness of our strategies in improving clean-label backdoor attacks.
Offline Multitask Representation Learning for Reinforcement Learning
Mar 18, 2024
We study offline multitask representation learning in reinforcement learning (RL), where a learner is provided with an offline dataset from different tasks that share a common representation and is asked to learn the shared representation. We theoretically investigate offline multitask low-rank RL, and propose a new algorithm called MORL for offline multitask representation learning. Furthermore, we examine downstream RL in reward-free, offline and online scenarios, where a new task is introduced to the agent that shares the same representation as the upstream offline tasks. Our theoretical results demonstrate the benefits of using the learned representation from the upstream offline task instead of directly learning the representation of the low-rank model.
On Sample-Efficient Offline Reinforcement Learning: Data Diversity, Posterior Sampling, and Beyond
Jan 06, 2024We seek to understand what facilitates sample-efficient learning from historical datasets for sequential decision-making, a problem that is popularly known as offline reinforcement learning (RL). Further, we are interested in algorithms that enjoy sample efficiency while leveraging (value) function approximation. In this paper, we address these fundamental questions by (i) proposing a notion of data diversity that subsumes the previous notions of coverage measures in offline RL and (ii) using this notion to {unify} three distinct classes of offline RL algorithms based on version spaces (VS), regularized optimization (RO), and posterior sampling (PS). We establish that VS-based, RO-based, and PS-based algorithms, under standard assumptions, achieve \emph{comparable} sample efficiency, which recovers the state-of-the-art sub-optimality bounds for finite and linear model classes with the standard assumptions. This result is surprising, given that the prior work suggested an unfavorable sample complexity of the RO-based algorithm compared to the VS-based algorithm, whereas posterior sampling is rarely considered in offline RL due to its explorative nature. Notably, our proposed model-free PS-based algorithm for offline RL is {novel}, with sub-optimality bounds that are {frequentist} (i.e., worst-case) in nature.