 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrototypical Exemplar Condensation for Memory-efficient Online Continual Learning
Mar 14, 2026Rehearsal-based continual learning (CL) mitigates catastrophic forgetting by maintaining a subset of samples from previous tasks for replay. Existing studies primarily focus on optimizing memory storage through coreset selection strategies. While these methods are effective, they typically require storing a substantial number of samples per class (SPC), often exceeding 20, to maintain satisfactory performance. In this work, we propose to further compress the memory footprint by synthesizing and storing prototypical exemplars, which can form representative prototypes when passed through the feature extractor. Owing to their representative nature, these exemplars enable the model to retain previous knowledge using only a small number of samples while preserving privacy. Moreover, we introduce a perturbation-based augmentation mechanism that generates synthetic variants of previous data during training, thereby enhancing CL performance. Extensive evaluations on widely used benchmark datasets and settings demonstrate that the proposed algorithm achieves superior performance compared to existing baselines, particularly in scenarios involving large-scale datasets and a high number of tasks.
SHeRL-FL: When Representation Learning Meets Split Learning in Hierarchical Federated Learning
Aug 11, 2025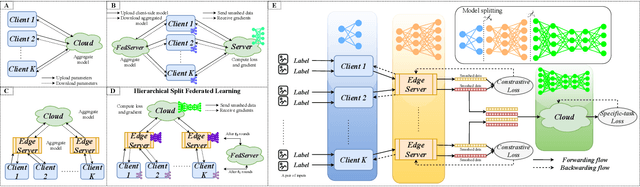
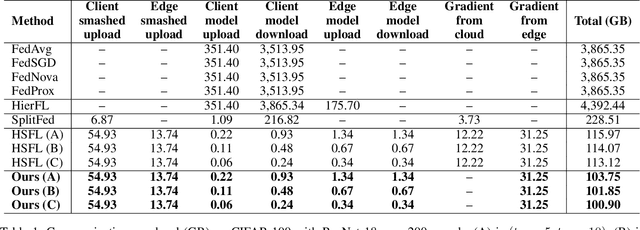
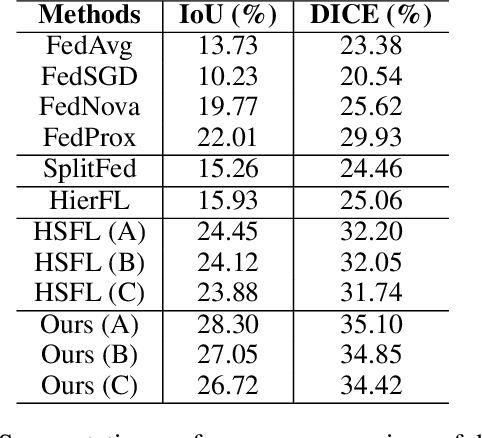
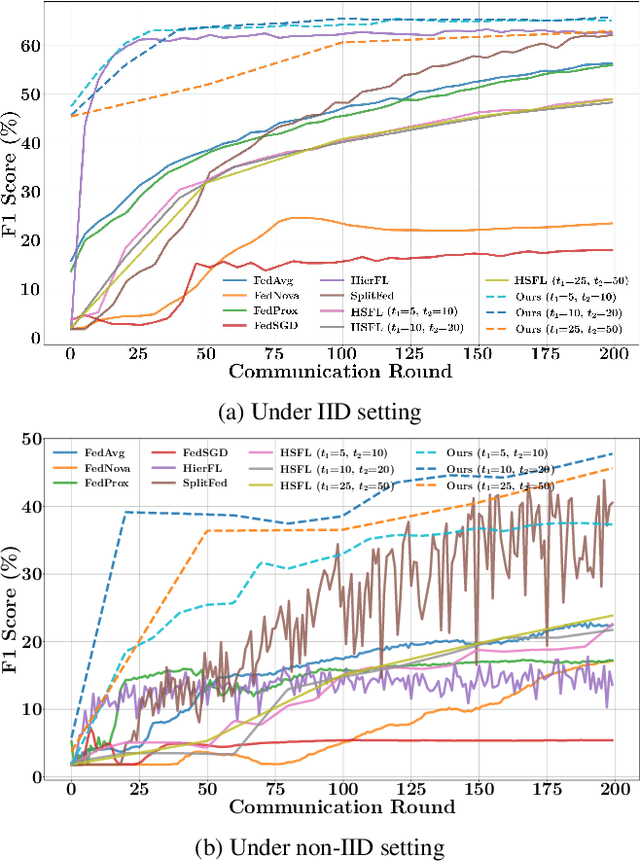
Federated learning (FL) is a promising approach for addressing scalability and latency issues in large-scale networks by enabling collaborative model training without requiring the sharing of raw data. However, existing FL frameworks often overlook the computational heterogeneity of edge clients and the growing training burden on resource-limited devices. However, FL suffers from high communication costs and complex model aggregation, especially with large models. Previous works combine split learning (SL) and hierarchical FL (HierFL) to reduce device-side computation and improve scalability, but this introduces training complexity due to coordination across tiers. To address these issues, we propose SHeRL-FL, which integrates SL and hierarchical model aggregation and incorporates representation learning at intermediate layers. By allowing clients and edge servers to compute training objectives independently of the cloud, SHeRL-FL significantly reduces both coordination complexity and communication overhead. To evaluate the effectiveness and efficiency of SHeRL-FL, we performed experiments on image classification tasks using CIFAR-10, CIFAR-100, and HAM10000 with AlexNet, ResNet-18, and ResNet-50 in both IID and non-IID settings. In addition, we evaluate performance on image segmentation tasks using the ISIC-2018 dataset with a ResNet-50-based U-Net. Experimental results demonstrate that SHeRL-FL reduces data transmission by over 90\% compared to centralized FL and HierFL, and by 50\% compared to SplitFed, which is a hybrid of FL and SL, and further improves hierarchical split learning methods.
HFedATM: Hierarchical Federated Domain Generalization via Optimal Transport and Regularized Mean Aggregation
Aug 07, 2025



Federated Learning (FL) is a decentralized approach where multiple clients collaboratively train a shared global model without sharing their raw data. Despite its effectiveness, conventional FL faces scalability challenges due to excessive computational and communication demands placed on a single central server as the number of participating devices grows. Hierarchical Federated Learning (HFL) addresses these issues by distributing model aggregation tasks across intermediate nodes (stations), thereby enhancing system scalability and robustness against single points of failure. However, HFL still suffers from a critical yet often overlooked limitation: domain shift, where data distributions vary significantly across different clients and stations, reducing model performance on unseen target domains. While Federated Domain Generalization (FedDG) methods have emerged to improve robustness to domain shifts, their integration into HFL frameworks remains largely unexplored. In this paper, we formally introduce Hierarchical Federated Domain Generalization (HFedDG), a novel scenario designed to investigate domain shift within hierarchical architectures. Specifically, we propose HFedATM, a hierarchical aggregation method that first aligns the convolutional filters of models from different stations through Filter-wise Optimal Transport Alignment and subsequently merges aligned models using a Shrinkage-aware Regularized Mean Aggregation. Our extensive experimental evaluations demonstrate that HFedATM significantly boosts the performance of existing FedDG baselines across multiple datasets and maintains computational and communication efficiency. Moreover, theoretical analyses indicate that HFedATM achieves tighter generalization error bounds compared to standard hierarchical averaging, resulting in faster convergence and stable training behavior.
pFedDSH: Enabling Knowledge Transfer in Personalized Federated Learning through Data-free Sub-Hypernetwork
Aug 07, 2025Federated Learning (FL) enables collaborative model training across distributed clients without sharing raw data, offering a significant privacy benefit. However, most existing Personalized Federated Learning (pFL) methods assume a static client participation, which does not reflect real-world scenarios where new clients may continuously join the federated system (i.e., dynamic client onboarding). In this paper, we explore a practical scenario in which a new batch of clients is introduced incrementally while the learning task remains unchanged. This dynamic environment poses various challenges, including preserving performance for existing clients without retraining and enabling efficient knowledge transfer between client batches. To address these issues, we propose Personalized Federated Data-Free Sub-Hypernetwork (pFedDSH), a novel framework based on a central hypernetwork that generates personalized models for each client via embedding vectors. To maintain knowledge stability for existing clients, pFedDSH incorporates batch-specific masks, which activate subsets of neurons to preserve knowledge. Furthermore, we introduce a data-free replay strategy motivated by DeepInversion to facilitate backward transfer, enhancing existing clients' performance without compromising privacy. Extensive experiments conducted on CIFAR-10, CIFAR-100, and Tiny-ImageNet demonstrate that pFedDSH outperforms the state-of-the-art pFL and Federated Continual Learning baselines in our investigation scenario. Our approach achieves robust performance stability for existing clients, as well as adaptation for new clients and efficient utilization of neural resources.
FLAT: Latent-Driven Arbitrary-Target Backdoor Attacks in Federated Learning
Aug 06, 2025Federated learning (FL) is vulnerable to backdoor attacks, yet most existing methods are limited by fixed-pattern or single-target triggers, making them inflexible and easier to detect. We propose FLAT (FL Arbitrary-Target Attack), a novel backdoor attack that leverages a latent-driven conditional autoencoder to generate diverse, target-specific triggers as needed. By introducing a latent code, FLAT enables the creation of visually adaptive and highly variable triggers, allowing attackers to select arbitrary targets without retraining and to evade conventional detection mechanisms. Our approach unifies attack success, stealth, and diversity within a single framework, introducing a new level of flexibility and sophistication to backdoor attacks in FL. Extensive experiments show that FLAT achieves high attack success and remains robust against advanced FL defenses. These results highlight the urgent need for new defense strategies to address latent-driven, multi-target backdoor threats in federated settings.
Towards Clean-Label Backdoor Attacks in the Physical World
Jul 27, 2024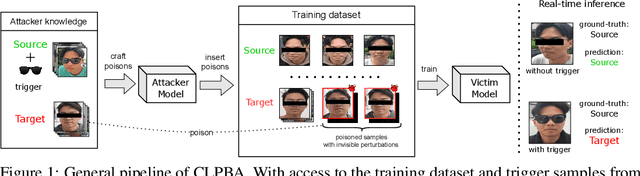
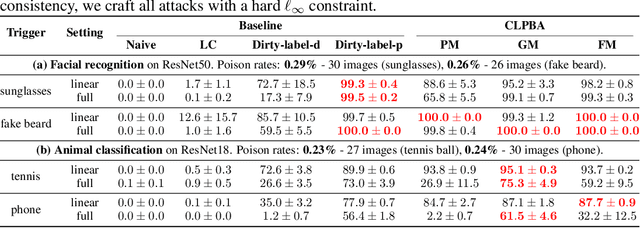


Deep Neural Networks (DNNs) are vulnerable to backdoor poisoning attacks, with most research focusing on digital triggers, special patterns digitally added to test-time inputs to induce targeted misclassification. In contrast, physical triggers, which are natural objects within a physical scene, have emerged as a desirable alternative since they enable real-time backdoor activations without digital manipulation. However, current physical attacks require that poisoned inputs have incorrect labels, making them easily detectable upon human inspection. In this paper, we collect a facial dataset of 21,238 images with 7 common accessories as triggers and use it to study the threat of clean-label backdoor attacks in the physical world. Our study reveals two findings. First, the success of physical attacks depends on the poisoning algorithm, physical trigger, and the pair of source-target classes. Second, although clean-label poisoned samples preserve ground-truth labels, their perceptual quality could be seriously degraded due to conspicuous artifacts in the images. Such samples are also vulnerable to statistical filtering methods because they deviate from the distribution of clean samples in the feature space. To address these issues, we propose replacing the standard $\ell_\infty$ regularization with a novel pixel regularization and feature regularization that could enhance the imperceptibility of poisoned samples without compromising attack performance. Our study highlights accidental backdoor activations as a key limitation of clean-label physical backdoor attacks. This happens when unintended objects or classes accidentally cause the model to misclassify as the target class.
Wicked Oddities: Selectively Poisoning for Effective Clean-Label Backdoor Attacks
Jul 16, 2024
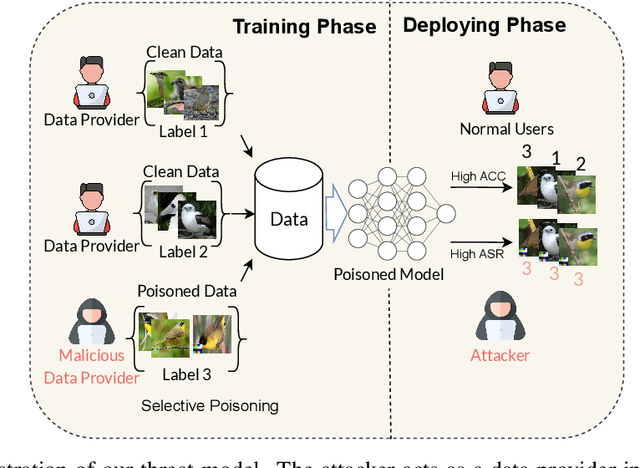
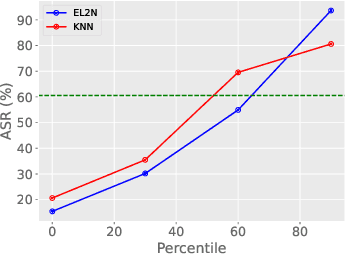
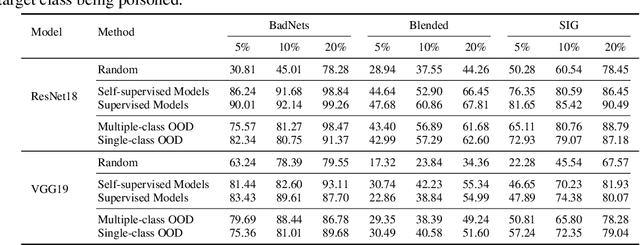
Deep neural networks are vulnerable to backdoor attacks, a type of adversarial attack that poisons the training data to manipulate the behavior of models trained on such data. Clean-label attacks are a more stealthy form of backdoor attacks that can perform the attack without changing the labels of poisoned data. Early works on clean-label attacks added triggers to a random subset of the training set, ignoring the fact that samples contribute unequally to the attack's success. This results in high poisoning rates and low attack success rates. To alleviate the problem, several supervised learning-based sample selection strategies have been proposed. However, these methods assume access to the entire labeled training set and require training, which is expensive and may not always be practical. This work studies a new and more practical (but also more challenging) threat model where the attacker only provides data for the target class (e.g., in face recognition systems) and has no knowledge of the victim model or any other classes in the training set. We study different strategies for selectively poisoning a small set of training samples in the target class to boost the attack success rate in this setting. Our threat model poses a serious threat in training machine learning models with third-party datasets, since the attack can be performed effectively with limited information. Experiments on benchmark datasets illustrate the effectiveness of our strategies in improving clean-label backdoor attacks.
Non-Cooperative Backdoor Attacks in Federated Learning: A New Threat Landscape
Jul 05, 2024



Despite the promise of Federated Learning (FL) for privacy-preserving model training on distributed data, it remains susceptible to backdoor attacks. These attacks manipulate models by embedding triggers (specific input patterns) in the training data, forcing misclassification as predefined classes during deployment. Traditional single-trigger attacks and recent work on cooperative multiple-trigger attacks, where clients collaborate, highlight limitations in attack realism due to coordination requirements. We investigate a more alarming scenario: non-cooperative multiple-trigger attacks. Here, independent adversaries introduce distinct triggers targeting unique classes. These parallel attacks exploit FL's decentralized nature, making detection difficult. Our experiments demonstrate the alarming vulnerability of FL to such attacks, where individual backdoors can be successfully learned without impacting the main task. This research emphasizes the critical need for robust defenses against diverse backdoor attacks in the evolving FL landscape. While our focus is on empirical analysis, we believe it can guide backdoor research toward more realistic settings, highlighting the crucial role of FL in building robust defenses against diverse backdoor threats. The code is available at \url{https://anonymous.4open.science/r/nba-980F/}.
Venomancer: Towards Imperceptible and Target-on-Demand Backdoor Attacks in Federated Learning
Jul 03, 2024



Federated Learning (FL) is a distributed machine learning approach that maintains data privacy by training on decentralized data sources. Similar to centralized machine learning, FL is also susceptible to backdoor attacks. Most backdoor attacks in FL assume a predefined target class and require control over a large number of clients or knowledge of benign clients' information. Furthermore, they are not imperceptible and are easily detected by human inspection due to clear artifacts left on the poison data. To overcome these challenges, we propose Venomancer, an effective backdoor attack that is imperceptible and allows target-on-demand. Specifically, imperceptibility is achieved by using a visual loss function to make the poison data visually indistinguishable from the original data. Target-on-demand property allows the attacker to choose arbitrary target classes via conditional adversarial training. Additionally, experiments showed that the method is robust against state-of-the-art defenses such as Norm Clipping, Weak DP, Krum, and Multi-Krum. The source code is available at https://anonymous.4open.science/r/Venomancer-3426.
Exploring the Practicality of Federated Learning: A Survey Towards the Communication Perspective
May 30, 2024Federated Learning (FL) is a promising paradigm that offers significant advancements in privacy-preserving, decentralized machine learning by enabling collaborative training of models across distributed devices without centralizing data. However, the practical deployment of FL systems faces a significant bottleneck: the communication overhead caused by frequently exchanging large model updates between numerous devices and a central server. This communication inefficiency can hinder training speed, model performance, and the overall feasibility of real-world FL applications. In this survey, we investigate various strategies and advancements made in communication-efficient FL, highlighting their impact and potential to overcome the communication challenges inherent in FL systems. Specifically, we define measures for communication efficiency, analyze sources of communication inefficiency in FL systems, and provide a taxonomy and comprehensive review of state-of-the-art communication-efficient FL methods. Additionally, we discuss promising future research directions for enhancing the communication efficiency of FL systems. By addressing the communication bottleneck, FL can be effectively applied and enable scalable and practical deployment across diverse applications that require privacy-preserving, decentralized machine learning, such as IoT, healthcare, or finance.