 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarnessing Increased Client Participation with Cohort-Parallel Federated Learning
May 24, 2024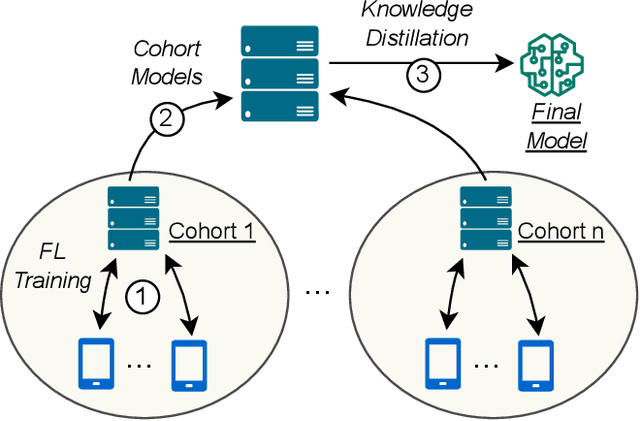
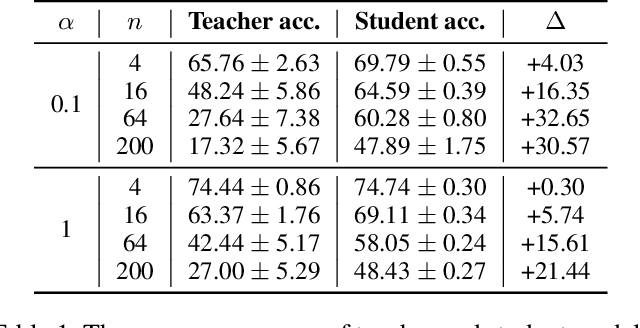
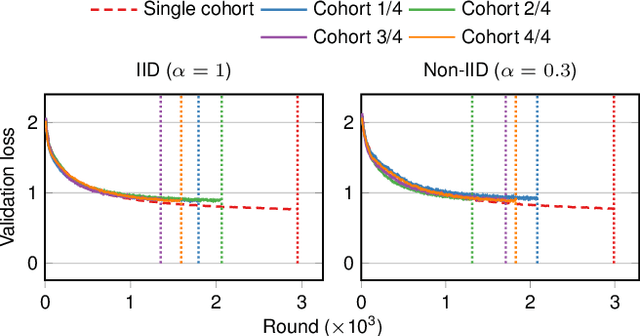
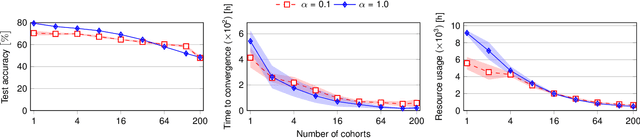
Federated Learning (FL) is a machine learning approach where nodes collaboratively train a global model. As more nodes participate in a round of FL, the effectiveness of individual model updates by nodes also diminishes. In this study, we increase the effectiveness of client updates by dividing the network into smaller partitions, or cohorts. We introduce Cohort-Parallel Federated Learning (CPFL): a novel learning approach where each cohort independently trains a global model using FL, until convergence, and the produced models by each cohort are then unified using one-shot Knowledge Distillation (KD) and a cross-domain, unlabeled dataset. The insight behind CPFL is that smaller, isolated networks converge quicker than in a one-network setting where all nodes participate. Through exhaustive experiments involving realistic traces and non-IID data distributions on the CIFAR-10 and FEMNIST image classification tasks, we investigate the balance between the number of cohorts, model accuracy, training time, and compute and communication resources. Compared to traditional FL, CPFL with four cohorts, non-IID data distribution, and CIFAR-10 yields a 1.9$\times$ reduction in train time and a 1.3$\times$ reduction in resource usage, with a minimal drop in test accuracy.
Handling Delayed Feedback in Distributed Online Optimization : A Projection-Free Approach
Feb 03, 2024



Learning at the edges has become increasingly important as large quantities of data are continually generated locally. Among others, this paradigm requires algorithms that are simple (so that they can be executed by local devices), robust (again uncertainty as data are continually generated), and reliable in a distributed manner under network issues, especially delays. In this study, we investigate the problem of online convex optimization under adversarial delayed feedback. We propose two projection-free algorithms for centralised and distributed settings in which they are carefully designed to achieve a regret bound of O(\sqrt{B}) where B is the sum of delay, which is optimal for the OCO problem in the delay setting while still being projection-free. We provide an extensive theoretical study and experimentally validate the performance of our algorithms by comparing them with existing ones on real-world problems.
Towards Efficient Communication Federated Recommendation System via Low-rank Training
Jan 08, 2024



In Federated Recommendation (FedRec) systems, communication costs are a critical bottleneck that arises from the need to transmit neural network models between user devices and a central server. Prior approaches to these challenges often lead to issues such as computational overheads, model specificity constraints, and compatibility issues with secure aggregation protocols. In response, we propose a novel framework, called Correlated Low-rank Structure (CoLR), which leverages the concept of adjusting lightweight trainable parameters while keeping most parameters frozen. Our approach substantially reduces communication overheads without introducing additional computational burdens. Critically, our framework remains fully compatible with secure aggregation protocols, including the robust use of Homomorphic Encryption. Our approach resulted in a reduction of up to 93.75% in payload size, with only an approximate 8% decrease in recommendation performance across datasets. Code for reproducing our experiments can be found at https://github.com/NNHieu/CoLR-FedRec.
One Gradient Frank-Wolfe for Decentralized Online Convex and Submodular Optimization
Oct 30, 2022
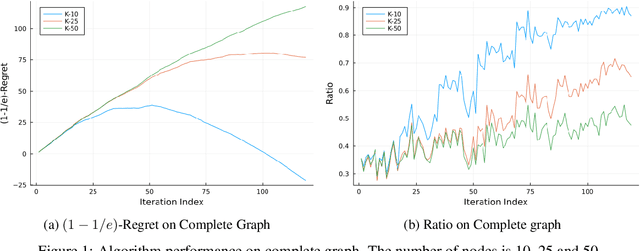
Decentralized learning has been studied intensively in recent years motivated by its wide applications in the context of federated learning. The majority of previous research focuses on the offline setting in which the objective function is static. However, the offline setting becomes unrealistic in numerous machine learning applications that witness the change of massive data. In this paper, we propose \emph{decentralized online} algorithm for convex and continuous DR-submodular optimization, two classes of functions that are present in a variety of machine learning problems. Our algorithms achieve performance guarantees comparable to those in the centralized offline setting. Moreover, on average, each participant performs only a \emph{single} gradient computation per time step. Subsequently, we extend our algorithms to the bandit setting. Finally, we illustrate the competitive performance of our algorithms in real-world experiments.
Online Decentralized Frank-Wolfe: From theoretical bound to applications in smart-building
Jul 31, 2022
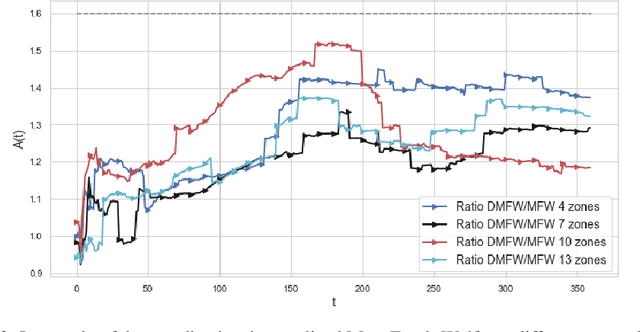
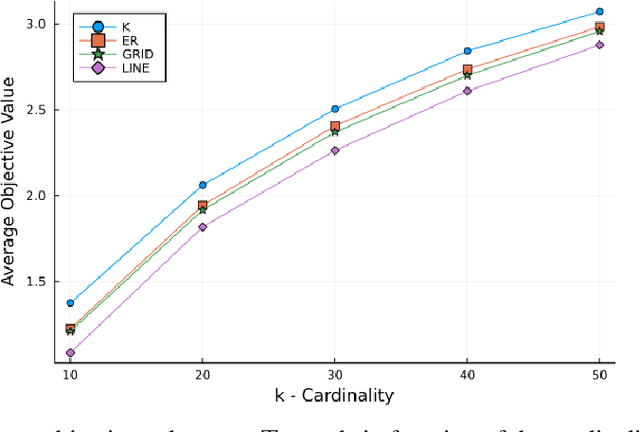
The design of decentralized learning algorithms is important in the fast-growing world in which data are distributed over participants with limited local computation resources and communication. In this direction, we propose an online algorithm minimizing non-convex loss functions aggregated from individual data/models distributed over a network. We provide the theoretical performance guarantee of our algorithm and demonstrate its utility on a real life smart building.
NNVLP: A Neural Network-Based Vietnamese Language Processing Toolkit
Oct 19, 2017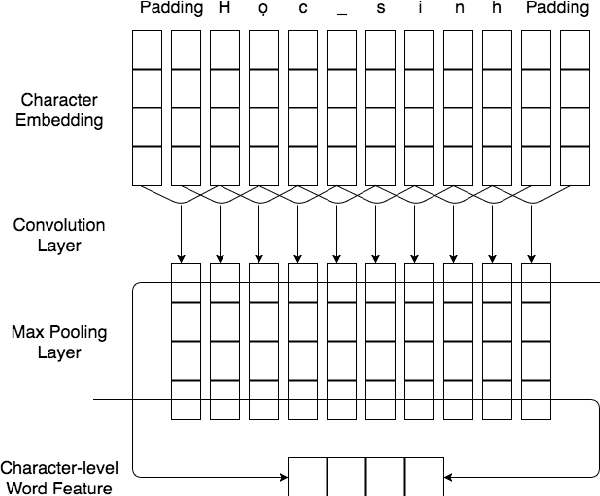
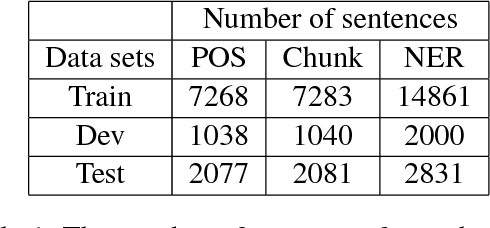
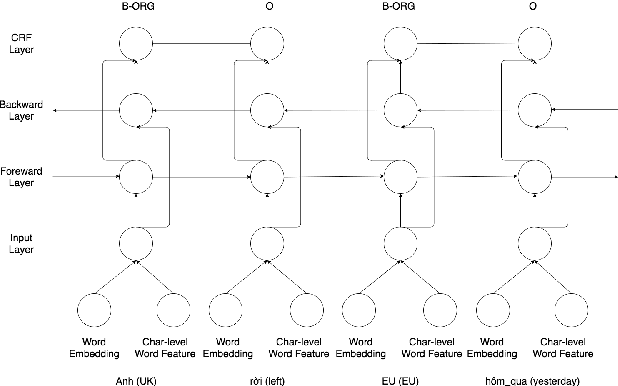
This paper demonstrates neural network-based toolkit namely NNVLP for essential Vietnamese language processing tasks including part-of-speech (POS) tagging, chunking, named entity recognition (NER). Our toolkit is a combination of bidirectional Long Short-Term Memory (Bi-LSTM), Convolutional Neural Network (CNN), Conditional Random Field (CRF), using pre-trained word embeddings as input, which achieves state-of-the-art results on these three tasks. We provide both API and web demo for this toolkit.