 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective LoRA Adapter Routing using Task Representations
Jan 29, 2026Low-rank adaptation (LoRA) enables parameter efficient specialization of large language models (LLMs) through modular adapters, resulting in rapidly growing public adapter pools spanning diverse tasks. Effectively using these adapters requires routing: selecting and composing the appropriate adapters for a query. We introduce LORAUTER, a novel routing framework that selects and composes LoRA adapters using task representations rather than adapter characteristics. Unlike existing approaches that map queries directly to adapters, LORAUTER routes queries via task embeddings derived from small validation sets and does not require adapter training data. By operating at the task level, LORAUTER achieves efficient routing that scales with the number of tasks rather than the number of adapters. Experiments across multiple tasks show that LORAUTER consistently outperforms baseline routing approaches, matching Oracle performance (101.2%) when task-aligned adapters exist and achieving state-of-the-art results on unseen tasks (+5.2 points). We further demonstrate the robustness of LORAUTER to very large, noisy adapter pools by scaling it to over 1500 adapters.
Navigating the Accuracy-Size Trade-Off with Flexible Model Merging
May 29, 2025Model merging has emerged as an efficient method to combine multiple single-task fine-tuned models. The merged model can enjoy multi-task capabilities without expensive training. While promising, merging into a single model often suffers from an accuracy gap with respect to individual fine-tuned models. On the other hand, deploying all individual fine-tuned models incurs high costs. We propose FlexMerge, a novel data-free model merging framework to flexibly generate merged models of varying sizes, spanning the spectrum from a single merged model to retaining all individual fine-tuned models. FlexMerge treats fine-tuned models as collections of sequential blocks and progressively merges them using any existing data-free merging method, halting at a desired size. We systematically explore the accuracy-size trade-off exhibited by different merging algorithms in combination with FlexMerge. Extensive experiments on vision and NLP benchmarks, with up to 30 tasks, reveal that even modestly larger merged models can provide substantial accuracy improvements over a single model. By offering fine-grained control over fused model size, FlexMerge provides a flexible, data-free, and high-performance solution for diverse deployment scenarios.
Revisiting Ensembling in One-Shot Federated Learning
Nov 11, 2024
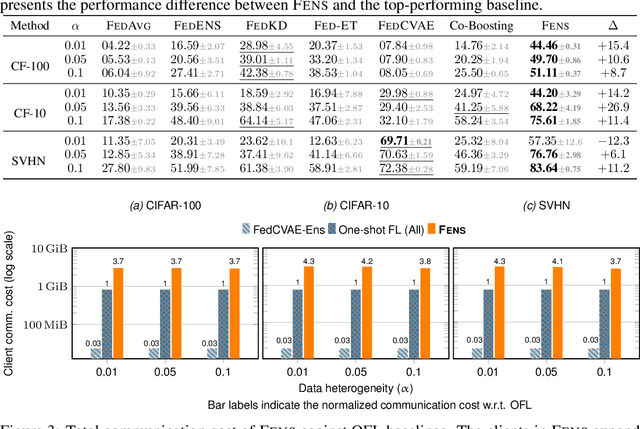
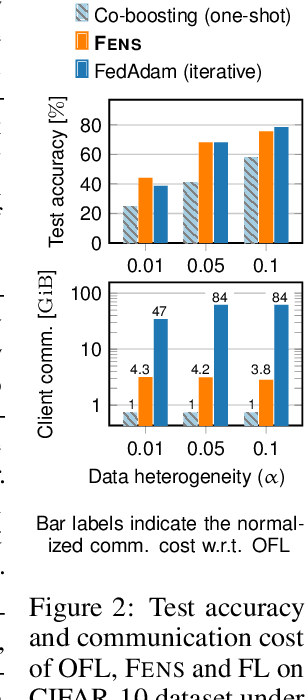

Federated learning (FL) is an appealing approach to training machine learning models without sharing raw data. However, standard FL algorithms are iterative and thus induce a significant communication cost. One-shot federated learning (OFL) trades the iterative exchange of models between clients and the server with a single round of communication, thereby saving substantially on communication costs. Not surprisingly, OFL exhibits a performance gap in terms of accuracy with respect to FL, especially under high data heterogeneity. We introduce FENS, a novel federated ensembling scheme that approaches the accuracy of FL with the communication efficiency of OFL. Learning in FENS proceeds in two phases: first, clients train models locally and send them to the server, similar to OFL; second, clients collaboratively train a lightweight prediction aggregator model using FL. We showcase the effectiveness of FENS through exhaustive experiments spanning several datasets and heterogeneity levels. In the particular case of heterogeneously distributed CIFAR-10 dataset, FENS achieves up to a 26.9% higher accuracy over state-of-the-art (SOTA) OFL, being only 3.1% lower than FL. At the same time, FENS incurs at most 4.3x more communication than OFL, whereas FL is at least 10.9x more communication-intensive than FENS.
Energy-Aware Decentralized Learning with Intermittent Model Training
Jul 01, 2024



Decentralized learning (DL) offers a powerful framework where nodes collaboratively train models without sharing raw data and without the coordination of a central server. In the iterative rounds of DL, models are trained locally, shared with neighbors in the topology, and aggregated with other models received from neighbors. Sharing and merging models contribute to convergence towards a consensus model that generalizes better across the collective data captured at training time. In addition, the energy consumption while sharing and merging model parameters is negligible compared to the energy spent during the training phase. Leveraging this fact, we present SkipTrain, a novel DL algorithm, which minimizes energy consumption in decentralized learning by strategically skipping some training rounds and substituting them with synchronization rounds. These training-silent periods, besides saving energy, also allow models to better mix and finally produce models with superior accuracy than typical DL algorithms that train at every round. Our empirical evaluations with 256 nodes demonstrate that SkipTrain reduces energy consumption by 50% and increases model accuracy by up to 12% compared to D-PSGD, the conventional DL algorithm.
Harnessing Increased Client Participation with Cohort-Parallel Federated Learning
May 24, 2024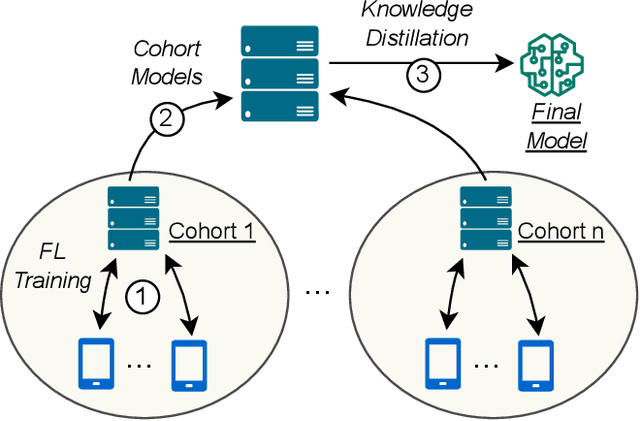
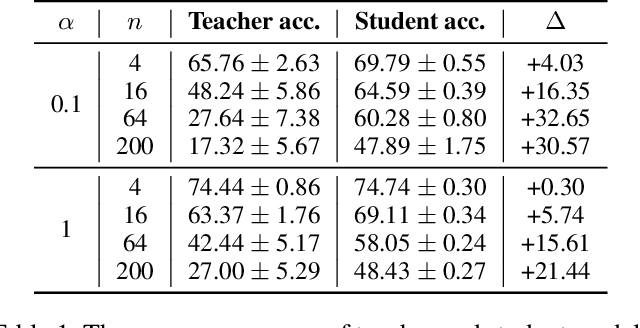
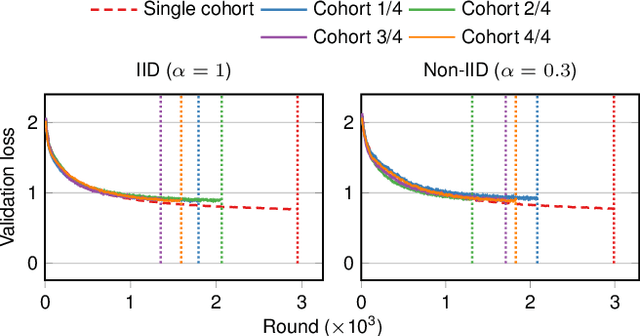
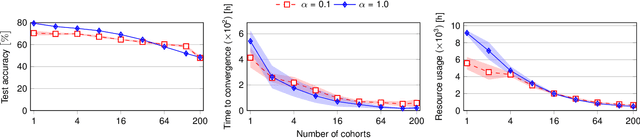
Federated Learning (FL) is a machine learning approach where nodes collaboratively train a global model. As more nodes participate in a round of FL, the effectiveness of individual model updates by nodes also diminishes. In this study, we increase the effectiveness of client updates by dividing the network into smaller partitions, or cohorts. We introduce Cohort-Parallel Federated Learning (CPFL): a novel learning approach where each cohort independently trains a global model using FL, until convergence, and the produced models by each cohort are then unified using one-shot Knowledge Distillation (KD) and a cross-domain, unlabeled dataset. The insight behind CPFL is that smaller, isolated networks converge quicker than in a one-network setting where all nodes participate. Through exhaustive experiments involving realistic traces and non-IID data distributions on the CIFAR-10 and FEMNIST image classification tasks, we investigate the balance between the number of cohorts, model accuracy, training time, and compute and communication resources. Compared to traditional FL, CPFL with four cohorts, non-IID data distribution, and CIFAR-10 yields a 1.9$\times$ reduction in train time and a 1.3$\times$ reduction in resource usage, with a minimal drop in test accuracy.
Fairness Auditing with Multi-Agent Collaboration
Feb 13, 2024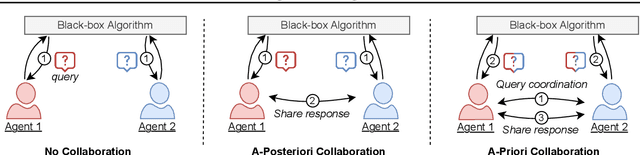
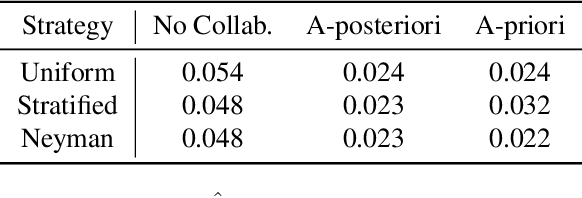
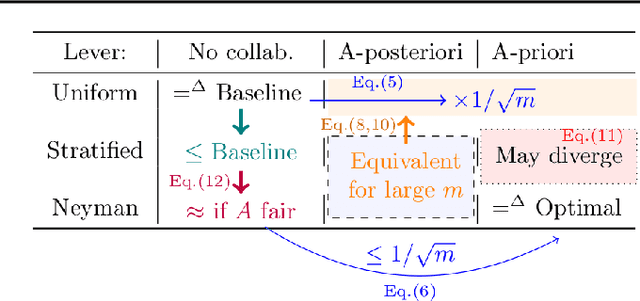
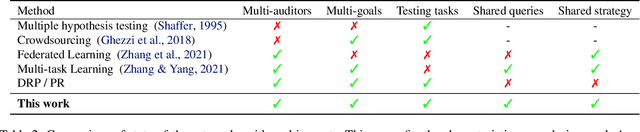
Existing work in fairness audits assumes that agents operate independently. In this paper, we consider the case of multiple agents auditing the same platform for different tasks. Agents have two levers: their collaboration strategy, with or without coordination beforehand, and their sampling method. We theoretically study their interplay when agents operate independently or collaborate. We prove that, surprisingly, coordination can sometimes be detrimental to audit accuracy, whereas uncoordinated collaboration generally yields good results. Experimentation on real-world datasets confirms this observation, as the audit accuracy of uncoordinated collaboration matches that of collaborative optimal sampling.
QuickDrop: Efficient Federated Unlearning by Integrated Dataset Distillation
Nov 27, 2023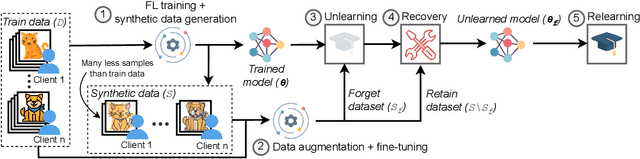
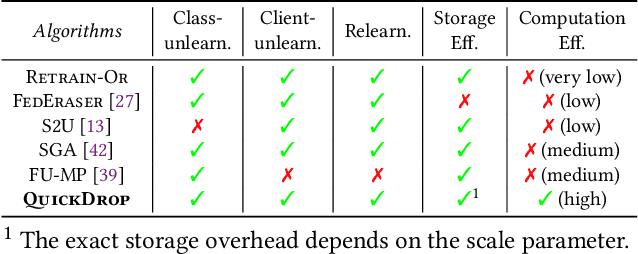
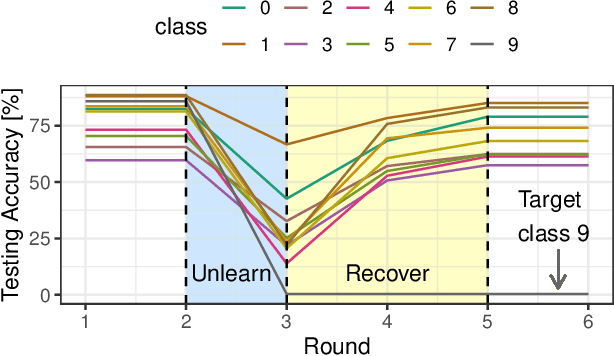
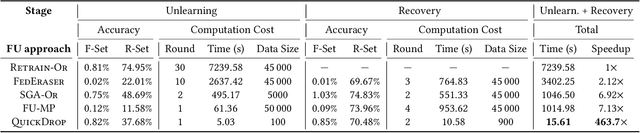
Federated Unlearning (FU) aims to delete specific training data from an ML model trained using Federated Learning (FL). We introduce QuickDrop, an efficient and original FU method that utilizes dataset distillation (DD) to accelerate unlearning and drastically reduces computational overhead compared to existing approaches. In QuickDrop, each client uses DD to generate a compact dataset representative of the original training dataset, called a distilled dataset, and uses this compact dataset during unlearning. To unlearn specific knowledge from the global model, QuickDrop has clients execute Stochastic Gradient Ascent with samples from the distilled datasets, thus significantly reducing computational overhead compared to conventional FU methods. We further increase the efficiency of QuickDrop by ingeniously integrating DD into the FL training process. By reusing the gradient updates produced during FL training for DD, the overhead of creating distilled datasets becomes close to negligible. Evaluations on three standard datasets show that, with comparable accuracy guarantees, QuickDrop reduces the duration of unlearning by 463.8x compared to model retraining from scratch and 65.1x compared to existing FU approaches. We also demonstrate the scalability of QuickDrop with 100 clients and show its effectiveness while handling multiple unlearning operations.
Get More for Less in Decentralized Learning Systems
Jun 07, 2023



Decentralized learning (DL) systems have been gaining popularity because they avoid raw data sharing by communicating only model parameters, hence preserving data confidentiality. However, the large size of deep neural networks poses a significant challenge for decentralized training, since each node needs to exchange gigabytes of data, overloading the network. In this paper, we address this challenge with JWINS, a communication-efficient and fully decentralized learning system that shares only a subset of parameters through sparsification. JWINS uses wavelet transform to limit the information loss due to sparsification and a randomized communication cut-off that reduces communication usage without damaging the performance of trained models. We demonstrate empirically with 96 DL nodes on non-IID datasets that JWINS can achieve similar accuracies to full-sharing DL while sending up to 64% fewer bytes. Additionally, on low communication budgets, JWINS outperforms the state-of-the-art communication-efficient DL algorithm CHOCO-SGD by up to 4x in terms of network savings and time.
Decentralized Learning Made Easy with DecentralizePy
Apr 17, 2023



Decentralized learning (DL) has gained prominence for its potential benefits in terms of scalability, privacy, and fault tolerance. It consists of many nodes that coordinate without a central server and exchange millions of parameters in the inherently iterative process of machine learning (ML) training. In addition, these nodes are connected in complex and potentially dynamic topologies. Assessing the intricate dynamics of such networks is clearly not an easy task. Often in literature, researchers resort to simulated environments that do not scale and fail to capture practical and crucial behaviors, including the ones associated to parallelism, data transfer, network delays, and wall-clock time. In this paper, we propose DecentralizePy, a distributed framework for decentralized ML, which allows for the emulation of large-scale learning networks in arbitrary topologies. We demonstrate the capabilities of DecentralizePy by deploying techniques such as sparsification and secure aggregation on top of several topologies, including dynamic networks with more than one thousand nodes.
TEE-based decentralized recommender systems: The raw data sharing redemption
Feb 23, 2022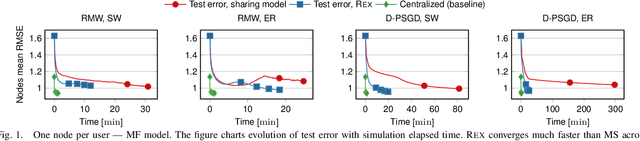
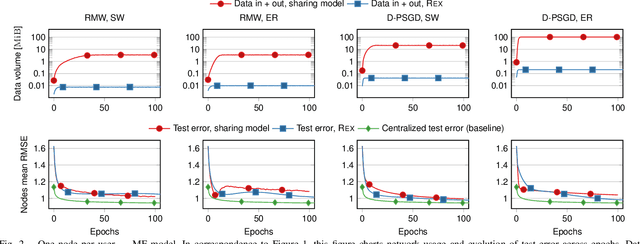
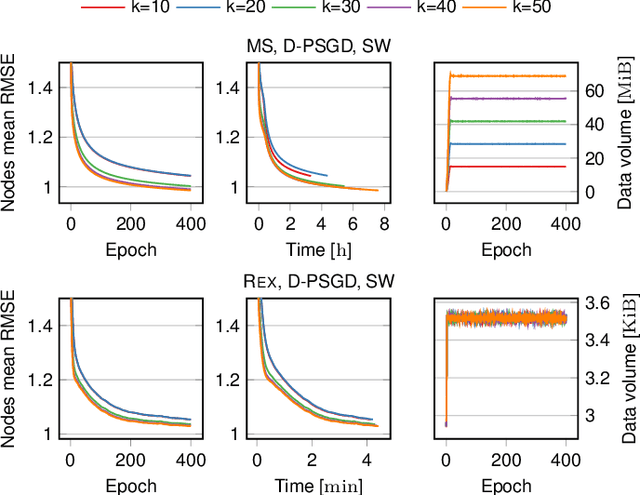
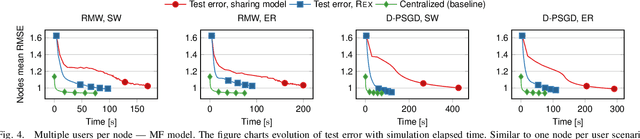
Recommenders are central in many applications today. The most effective recommendation schemes, such as those based on collaborative filtering (CF), exploit similarities between user profiles to make recommendations, but potentially expose private data. Federated learning and decentralized learning systems address this by letting the data stay on user's machines to preserve privacy: each user performs the training on local data and only the model parameters are shared. However, sharing the model parameters across the network may still yield privacy breaches. In this paper, we present REX, the first enclave-based decentralized CF recommender. REX exploits Trusted execution environments (TEE), such as Intel software guard extensions (SGX), that provide shielded environments within the processor to improve convergence while preserving privacy. Firstly, REX enables raw data sharing, which ultimately speeds up convergence and reduces the network load. Secondly, REX fully preserves privacy. We analyze the impact of raw data sharing in both deep neural network (DNN) and matrix factorization (MF) recommenders and showcase the benefits of trusted environments in a full-fledged implementation of REX. Our experimental results demonstrate that through raw data sharing, REX significantly decreases the training time by 18.3x and the network load by 2 orders of magnitude over standard decentralized approaches that share only parameters, while fully protecting privacy by leveraging trustworthy hardware enclaves with very little overhead.