 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoSchemaKG: Autonomous Knowledge Graph Construction through Dynamic Schema Induction from Web-Scale Corpora
May 29, 2025
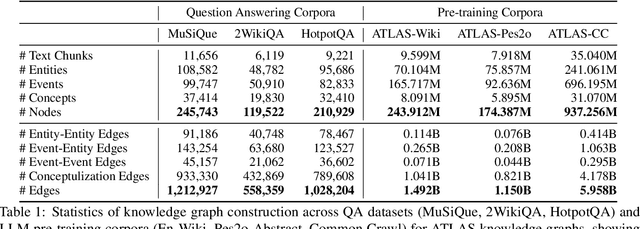
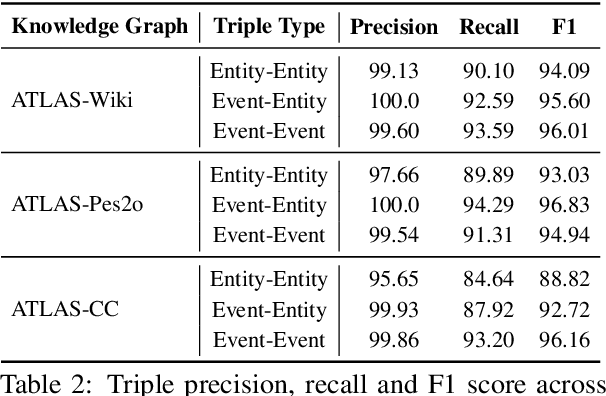

We present AutoSchemaKG, a framework for fully autonomous knowledge graph construction that eliminates the need for predefined schemas. Our system leverages large language models to simultaneously extract knowledge triples and induce comprehensive schemas directly from text, modeling both entities and events while employing conceptualization to organize instances into semantic categories. Processing over 50 million documents, we construct ATLAS (Automated Triple Linking And Schema induction), a family of knowledge graphs with 900+ million nodes and 5.9 billion edges. This approach outperforms state-of-the-art baselines on multi-hop QA tasks and enhances LLM factuality. Notably, our schema induction achieves 95\% semantic alignment with human-crafted schemas with zero manual intervention, demonstrating that billion-scale knowledge graphs with dynamically induced schemas can effectively complement parametric knowledge in large language models.
QuickDrop: Efficient Federated Unlearning by Integrated Dataset Distillation
Nov 27, 2023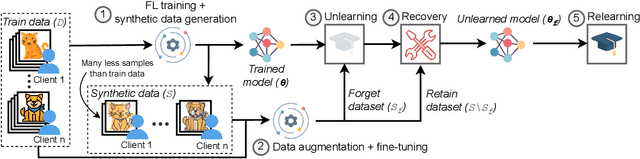
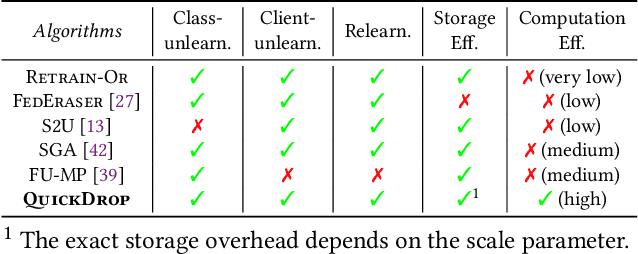
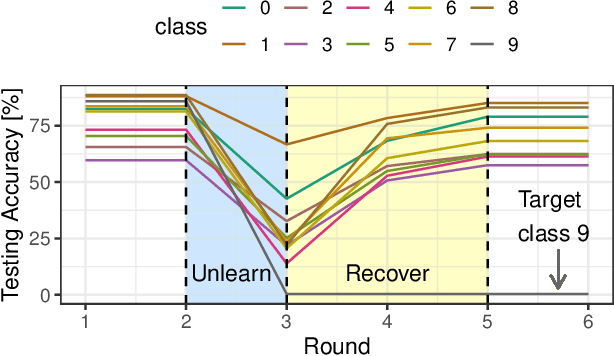
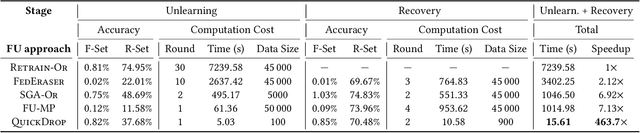
Federated Unlearning (FU) aims to delete specific training data from an ML model trained using Federated Learning (FL). We introduce QuickDrop, an efficient and original FU method that utilizes dataset distillation (DD) to accelerate unlearning and drastically reduces computational overhead compared to existing approaches. In QuickDrop, each client uses DD to generate a compact dataset representative of the original training dataset, called a distilled dataset, and uses this compact dataset during unlearning. To unlearn specific knowledge from the global model, QuickDrop has clients execute Stochastic Gradient Ascent with samples from the distilled datasets, thus significantly reducing computational overhead compared to conventional FU methods. We further increase the efficiency of QuickDrop by ingeniously integrating DD into the FL training process. By reusing the gradient updates produced during FL training for DD, the overhead of creating distilled datasets becomes close to negligible. Evaluations on three standard datasets show that, with comparable accuracy guarantees, QuickDrop reduces the duration of unlearning by 463.8x compared to model retraining from scratch and 65.1x compared to existing FU approaches. We also demonstrate the scalability of QuickDrop with 100 clients and show its effectiveness while handling multiple unlearning operations.
On Knowledge Editing in Federated Learning: Perspectives, Challenges, and Future Directions
Jun 02, 2023As Federated Learning (FL) has gained increasing attention, it has become widely acknowledged that straightforwardly applying stochastic gradient descent (SGD) on the overall framework when learning over a sequence of tasks results in the phenomenon known as ``catastrophic forgetting''. Consequently, much FL research has centered on devising federated increasing learning methods to alleviate forgetting while augmenting knowledge. On the other hand, forgetting is not always detrimental. The selective amnesia, also known as federated unlearning, which entails the elimination of specific knowledge, can address privacy concerns and create additional ``space'' for acquiring new knowledge. However, there is a scarcity of extensive surveys that encompass recent advancements and provide a thorough examination of this issue. In this manuscript, we present an extensive survey on the topic of knowledge editing (augmentation/removal) in Federated Learning, with the goal of summarizing the state-of-the-art research and expanding the perspective for various domains. Initially, we introduce an integrated paradigm, referred to as Federated Editable Learning (FEL), by reevaluating the entire lifecycle of FL. Secondly, we provide a comprehensive overview of existing methods, evaluate their position within the proposed paradigm, and emphasize the current challenges they face. Lastly, we explore potential avenues for future research and identify unresolved issues.
Demystify Self-Attention in Vision Transformers from a Semantic Perspective: Analysis and Application
Nov 13, 2022


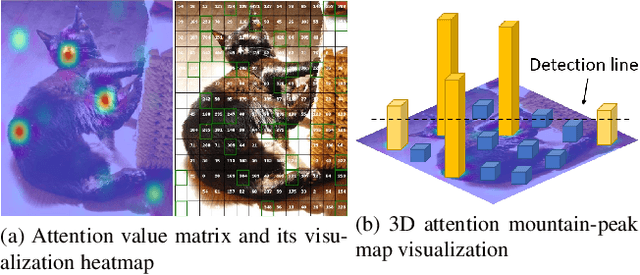
Self-attention mechanisms, especially multi-head self-attention (MSA), have achieved great success in many fields such as computer vision and natural language processing. However, many existing vision transformer (ViT) works simply inherent transformer designs from NLP to adapt vision tasks, while ignoring the fundamental difference between ``how MSA works in image and language settings''. Language naturally contains highly semantic structures that are directly interpretable by humans. Its basic unit (word) is discrete without redundant information, which readily supports interpretable studies on MSA mechanisms of language transformer. In contrast, visual data exhibits a fundamentally different structure: Its basic unit (pixel) is a natural low-level representation with significant redundancies in the neighbourhood, which poses obvious challenges to the interpretability of MSA mechanism in ViT. In this paper, we introduce a typical image processing technique, i.e., scale-invariant feature transforms (SIFTs), which maps low-level representations into mid-level spaces, and annotates extensive discrete keypoints with semantically rich information. Next, we construct a weighted patch interrelation analysis based on SIFT keypoints to capture the attention patterns hidden in patches with different semantic concentrations Interestingly, we find this quantitative analysis is not only an effective complement to the interpretability of MSA mechanisms in ViT, but can also be applied to 1) spurious correlation discovery and ``prompting'' during model inference, 2) and guided model pre-training acceleration. Experimental results on both applications show significant advantages over baselines, demonstrating the efficacy of our method.
A Coalition Formation Game Approach for Personalized Federated Learning
Feb 08, 2022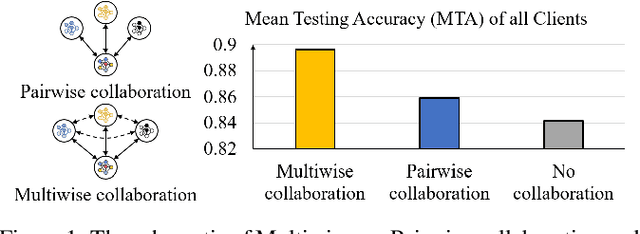

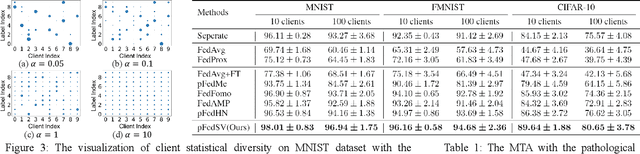
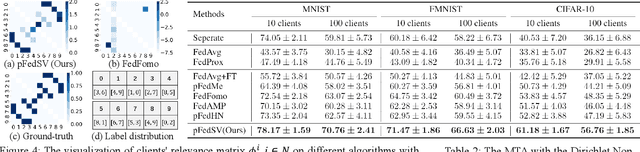
Facing the challenge of statistical diversity in client local data distribution, personalized federated learning (PFL) has become a growing research hotspot. Although the state-of-the-art methods with model similarity-based pairwise collaboration have achieved promising performance, they neglect the fact that model aggregation is essentially a collaboration process within the coalition, where the complex multiwise influences take place among clients. In this paper, we first apply Shapley value (SV) from coalition game theory into the PFL scenario. To measure the multiwise collaboration among a group of clients on the personalized learning performance, SV takes their marginal contribution to the final result as a metric. We propose a novel personalized algorithm: pFedSV, which can 1. identify each client's optimal collaborator coalition and 2. perform personalized model aggregation based on SV. Extensive experiments on various datasets (MNIST, Fashion-MNIST, and CIFAR-10) are conducted with different Non-IID data settings (Pathological and Dirichlet). The results show that pFedSV can achieve superior personalized accuracy for each client, compared to the state-of-the-art benchmarks.