 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo VLMs Have a Moral Backbone? A Study on the Fragile Morality of Vision-Language Models
Jan 23, 2026Despite substantial efforts toward improving the moral alignment of Vision-Language Models (VLMs), it remains unclear whether their ethical judgments are stable in realistic settings. This work studies moral robustness in VLMs, defined as the ability to preserve moral judgments under textual and visual perturbations that do not alter the underlying moral context. We systematically probe VLMs with a diverse set of model-agnostic multimodal perturbations and find that their moral stances are highly fragile, frequently flipping under simple manipulations. Our analysis reveals systematic vulnerabilities across perturbation types, moral domains, and model scales, including a sycophancy trade-off where stronger instruction-following models are more susceptible to persuasion. We further show that lightweight inference-time interventions can partially restore moral stability. These results demonstrate that moral alignment alone is insufficient and that moral robustness is a necessary criterion for the responsible deployment of VLMs.
AppellateGen: A Benchmark for Appellate Legal Judgment Generation
Jan 08, 2026Legal judgment generation is a critical task in legal intelligence. However, existing research in legal judgment generation has predominantly focused on first-instance trials, relying on static fact-to-verdict mappings while neglecting the dialectical nature of appellate (second-instance) review. To address this, we introduce AppellateGen, a benchmark for second-instance legal judgment generation comprising 7,351 case pairs. The task requires models to draft legally binding judgments by reasoning over the initial verdict and evidentiary updates, thereby modeling the causal dependency between trial stages. We further propose a judicial Standard Operating Procedure (SOP)-based Legal Multi-Agent System (SLMAS) to simulate judicial workflows, which decomposes the generation process into discrete stages of issue identification, retrieval, and drafting. Experimental results indicate that while SLMAS improves logical consistency, the complexity of appellate reasoning remains a substantial challenge for current LLMs. The dataset and code are publicly available at: https://anonymous.4open.science/r/AppellateGen-5763.
LongFly: Long-Horizon UAV Vision-and-Language Navigation with Spatiotemporal Context Integration
Dec 26, 2025Unmanned aerial vehicles (UAVs) are crucial tools for post-disaster search and rescue, facing challenges such as high information density, rapid changes in viewpoint, and dynamic structures, especially in long-horizon navigation. However, current UAV vision-and-language navigation(VLN) methods struggle to model long-horizon spatiotemporal context in complex environments, resulting in inaccurate semantic alignment and unstable path planning. To this end, we propose LongFly, a spatiotemporal context modeling framework for long-horizon UAV VLN. LongFly proposes a history-aware spatiotemporal modeling strategy that transforms fragmented and redundant historical data into structured, compact, and expressive representations. First, we propose the slot-based historical image compression module, which dynamically distills multi-view historical observations into fixed-length contextual representations. Then, the spatiotemporal trajectory encoding module is introduced to capture the temporal dynamics and spatial structure of UAV trajectories. Finally, to integrate existing spatiotemporal context with current observations, we design the prompt-guided multimodal integration module to support time-based reasoning and robust waypoint prediction. Experimental results demonstrate that LongFly outperforms state-of-the-art UAV VLN baselines by 7.89\% in success rate and 6.33\% in success weighted by path length, consistently across both seen and unseen environments.
MTP: Exploring Multimodal Urban Traffic Profiling with Modality Augmentation and Spectrum Fusion
Nov 17, 2025With rapid urbanization in the modern era, traffic signals from various sensors have been playing a significant role in monitoring the states of cities, which provides a strong foundation in ensuring safe travel, reducing traffic congestion and optimizing urban mobility. Most existing methods for traffic signal modeling often rely on the original data modality, i.e., numerical direct readings from the sensors in cities. However, this unimodal approach overlooks the semantic information existing in multimodal heterogeneous urban data in different perspectives, which hinders a comprehensive understanding of traffic signals and limits the accurate prediction of complex traffic dynamics. To address this problem, we propose a novel Multimodal framework, MTP, for urban Traffic Profiling, which learns multimodal features through numeric, visual, and textual perspectives. The three branches drive for a multimodal perspective of urban traffic signal learning in the frequency domain, while the frequency learning strategies delicately refine the information for extraction. Specifically, we first conduct the visual augmentation for the traffic signals, which transforms the original modality into frequency images and periodicity images for visual learning. Also, we augment descriptive texts for the traffic signals based on the specific topic, background information and item description for textual learning. To complement the numeric information, we utilize frequency multilayer perceptrons for learning on the original modality. We design a hierarchical contrastive learning on the three branches to fuse the spectrum of three modalities. Finally, extensive experiments on six real-world datasets demonstrate superior performance compared with the state-of-the-art approaches.
iMAD: Intelligent Multi-Agent Debate for Efficient and Accurate LLM Inference
Nov 14, 2025



Large Language Model (LLM) agent systems have advanced rapidly, driven by their strong generalization in zero-shot settings. To further enhance reasoning and accuracy on complex tasks, Multi-Agent Debate (MAD) has emerged as a promising framework that engages multiple LLM agents in structured debates to encourage diverse reasoning. However, triggering MAD for every query is inefficient, as it incurs substantial computational (token) cost and may even degrade accuracy by overturning correct single-agent answers. To address these limitations, we propose intelligent Multi-Agent Debate (iMAD), a token-efficient framework that selectively triggers MAD only when it is likely to be beneficial (i.e., correcting an initially wrong answer). To achieve this goal, iMAD learns generalizable model behaviors to make accurate debate decisions. Specifically, iMAD first prompts a single agent to produce a structured self-critique response, from which we extract 41 interpretable linguistic and semantic features capturing hesitation cues. Then, iMAD uses a lightweight debate-decision classifier, trained using our proposed FocusCal loss, to determine whether to trigger MAD, enabling robust debate decisions without test dataset-specific tuning. Through extensive experiments using six (visual) question answering datasets against five competitive baselines, we have shown that iMAD significantly reduces token usage (by up to 92%) while also improving final answer accuracy (by up to 13.5%).
TCM-Eval: An Expert-Level Dynamic and Extensible Benchmark for Traditional Chinese Medicine
Nov 10, 2025Large Language Models (LLMs) have demonstrated remarkable capabilities in modern medicine, yet their application in Traditional Chinese Medicine (TCM) remains severely limited by the absence of standardized benchmarks and the scarcity of high-quality training data. To address these challenges, we introduce TCM-Eval, the first dynamic and extensible benchmark for TCM, meticulously curated from national medical licensing examinations and validated by TCM experts. Furthermore, we construct a large-scale training corpus and propose Self-Iterative Chain-of-Thought Enhancement (SI-CoTE) to autonomously enrich question-answer pairs with validated reasoning chains through rejection sampling, establishing a virtuous cycle of data and model co-evolution. Using this enriched training data, we develop ZhiMingTang (ZMT), a state-of-the-art LLM specifically designed for TCM, which significantly exceeds the passing threshold for human practitioners. To encourage future research and development, we release a public leaderboard, fostering community engagement and continuous improvement.
Structuring the Unstructured: A Systematic Review of Text-to-Structure Generation for Agentic AI with a Universal Evaluation Framework
Aug 17, 2025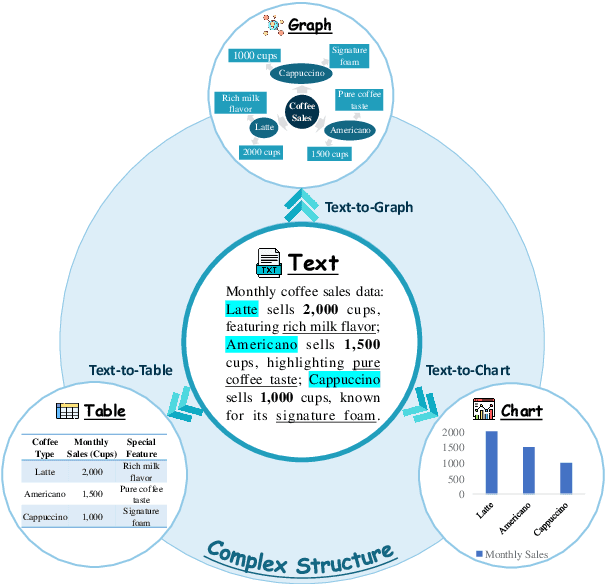
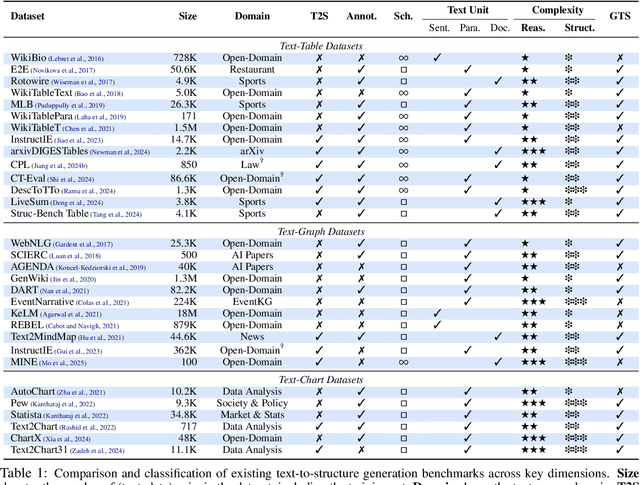

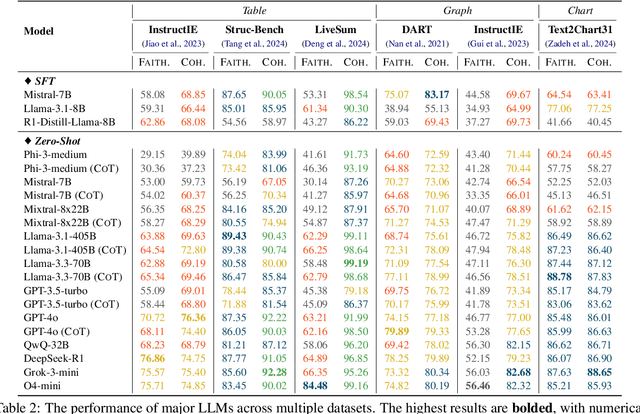
The evolution of AI systems toward agentic operation and context-aware retrieval necessitates transforming unstructured text into structured formats like tables, knowledge graphs, and charts. While such conversions enable critical applications from summarization to data mining, current research lacks a comprehensive synthesis of methodologies, datasets, and metrics. This systematic review examines text-to-structure techniques and the encountered challenges, evaluates current datasets and assessment criteria, and outlines potential directions for future research. We also introduce a universal evaluation framework for structured outputs, establishing text-to-structure as foundational infrastructure for next-generation AI systems.
SessionIntentBench: A Multi-task Inter-session Intention-shift Modeling Benchmark for E-commerce Customer Behavior Understanding
Jul 27, 2025Session history is a common way of recording user interacting behaviors throughout a browsing activity with multiple products. For example, if an user clicks a product webpage and then leaves, it might because there are certain features that don't satisfy the user, which serve as an important indicator of on-the-spot user preferences. However, all prior works fail to capture and model customer intention effectively because insufficient information exploitation and only apparent information like descriptions and titles are used. There is also a lack of data and corresponding benchmark for explicitly modeling intention in E-commerce product purchase sessions. To address these issues, we introduce the concept of an intention tree and propose a dataset curation pipeline. Together, we construct a sibling multimodal benchmark, SessionIntentBench, that evaluates L(V)LMs' capability on understanding inter-session intention shift with four subtasks. With 1,952,177 intention entries, 1,132,145 session intention trajectories, and 13,003,664 available tasks mined using 10,905 sessions, we provide a scalable way to exploit the existing session data for customer intention understanding. We conduct human annotations to collect ground-truth label for a subset of collected data to form an evaluation gold set. Extensive experiments on the annotated data further confirm that current L(V)LMs fail to capture and utilize the intention across the complex session setting. Further analysis show injecting intention enhances LLMs' performances.
P3SL: Personalized Privacy-Preserving Split Learning on Heterogeneous Edge Devices
Jul 23, 2025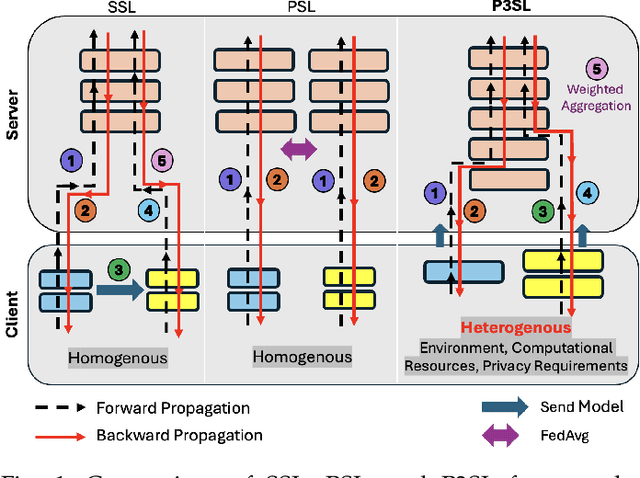

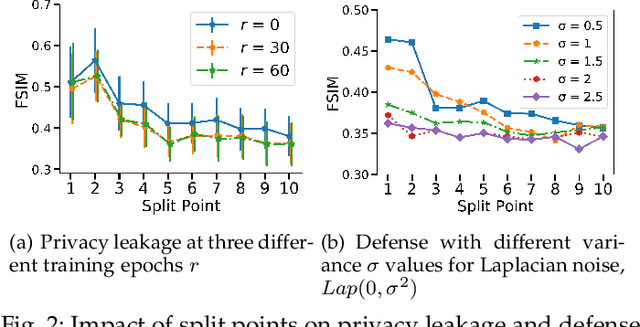
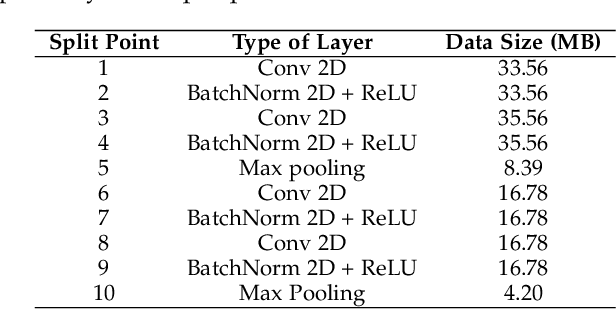
Split Learning (SL) is an emerging privacy-preserving machine learning technique that enables resource constrained edge devices to participate in model training by partitioning a model into client-side and server-side sub-models. While SL reduces computational overhead on edge devices, it encounters significant challenges in heterogeneous environments where devices vary in computing resources, communication capabilities, environmental conditions, and privacy requirements. Although recent studies have explored heterogeneous SL frameworks that optimize split points for devices with varying resource constraints, they often neglect personalized privacy requirements and local model customization under varying environmental conditions. To address these limitations, we propose P3SL, a Personalized Privacy-Preserving Split Learning framework designed for heterogeneous, resource-constrained edge device systems. The key contributions of this work are twofold. First, we design a personalized sequential split learning pipeline that allows each client to achieve customized privacy protection and maintain personalized local models tailored to their computational resources, environmental conditions, and privacy needs. Second, we adopt a bi-level optimization technique that empowers clients to determine their own optimal personalized split points without sharing private sensitive information (i.e., computational resources, environmental conditions, privacy requirements) with the server. This approach balances energy consumption and privacy leakage risks while maintaining high model accuracy. We implement and evaluate P3SL on a testbed consisting of 7 devices including 4 Jetson Nano P3450 devices, 2 Raspberry Pis, and 1 laptop, using diverse model architectures and datasets under varying environmental conditions.
De-AntiFake: Rethinking the Protective Perturbations Against Voice Cloning Attacks
Jul 03, 2025The rapid advancement of speech generation models has heightened privacy and security concerns related to voice cloning (VC). Recent studies have investigated disrupting unauthorized voice cloning by introducing adversarial perturbations. However, determined attackers can mitigate these protective perturbations and successfully execute VC. In this study, we conduct the first systematic evaluation of these protective perturbations against VC under realistic threat models that include perturbation purification. Our findings reveal that while existing purification methods can neutralize a considerable portion of the protective perturbations, they still lead to distortions in the feature space of VC models, which degrades the performance of VC. From this perspective, we propose a novel two-stage purification method: (1) Purify the perturbed speech; (2) Refine it using phoneme guidance to align it with the clean speech distribution. Experimental results demonstrate that our method outperforms state-of-the-art purification methods in disrupting VC defenses. Our study reveals the limitations of adversarial perturbation-based VC defenses and underscores the urgent need for more robust solutions to mitigate the security and privacy risks posed by VC. The code and audio samples are available at https://de-antifake.github.io.