 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrafficClaw: Generalizable Urban Traffic Control via Unified Physical Environment Modeling
Apr 19, 2026Urban traffic control is a system-level coordination problem spanning heterogeneous subsystems, including traffic signals, freeways, public transit, and taxi services. Existing optimization-based, reinforcement learning (RL), and emerging LLM-based approaches are largely designed for isolated tasks, limiting both cross-task generalization and the ability to capture coupled physical dynamics across subsystems. We argue that effective system-level control requires a unified physical environment in which subsystems share infrastructure, mobility demand, and spatiotemporal constraints, allowing local interventions to propagate through the network. To this end, we propose TrafficClaw, a framework for general urban traffic control built upon a unified runtime environment. TrafficClaw integrates heterogeneous subsystems into a shared dynamical system, enabling explicit modeling of cross-subsystem interactions and closed-loop agent-environment feedback. Within this environment, we develop an LLM agent with executable spatiotemporal reasoning and reusable procedural memory, supporting unified diagnostics across subsystems and continual strategy refinement. Furthermore, we introduce a multi-stage training pipeline with supervised initialization and agentic RL with system-level optimization, further enabling coordinated and system-aware performance. Experiments demonstrate that TrafficClaw achieves robust, transferable, and system-aware performance across unseen traffic scenarios, dynamics, and task configurations. Our project is available at https://github.com/usail-hkust/TrafficClaw.
MixTTE: Multi-Level Mixture-of-Experts for Scalable and Adaptive Travel Time Estimation
Jan 06, 2026Accurate Travel Time Estimation (TTE) is critical for ride-hailing platforms, where errors directly impact user experience and operational efficiency. While existing production systems excel at holistic route-level dependency modeling, they struggle to capture city-scale traffic dynamics and long-tail scenarios, leading to unreliable predictions in large urban networks. In this paper, we propose \model, a scalable and adaptive framework that synergistically integrates link-level modeling with industrial route-level TTE systems. Specifically, we propose a spatio-temporal external attention module to capture global traffic dynamic dependencies across million-scale road networks efficiently. Moreover, we construct a stabilized graph mixture-of-experts network to handle heterogeneous traffic patterns while maintaining inference efficiency. Furthermore, an asynchronous incremental learning strategy is tailored to enable real-time and stable adaptation to dynamic traffic distribution shifts. Experiments on real-world datasets validate MixTTE significantly reduces prediction errors compared to seven baselines. MixTTE has been deployed in DiDi, substantially improving the accuracy and stability of the TTE service.
An LLM-Powered Cooperative Framework for Large-Scale Multi-Vehicle Navigation
Oct 09, 2025



The rise of Internet of Vehicles (IoV) technologies is transforming traffic management from isolated control to a collective, multi-vehicle process. At the heart of this shift is multi-vehicle dynamic navigation, which requires simultaneously routing large fleets under evolving traffic conditions. Existing path search algorithms and reinforcement learning methods struggle to scale to city-wide networks, often failing to capture the nonlinear, stochastic, and coupled dynamics of urban traffic. To address these challenges, we propose CityNav, a hierarchical, LLM-powered framework for large-scale multi-vehicle navigation. CityNav integrates a global traffic allocation agent, which coordinates strategic traffic flow distribution across regions, with local navigation agents that generate locally adaptive routes aligned with global directives. To enable effective cooperation, we introduce a cooperative reasoning optimization mechanism, in which agents are jointly trained with a dual-reward structure: individual rewards promote per-vehicle efficiency, while shared rewards encourage network-wide coordination and congestion reduction. Extensive experiments on four real-world road networks of varying scales (up to 1.6 million roads and 430,000 intersections) and traffic datasets demonstrate that CityNav consistently outperforms nine classical path search and RL-based baselines in city-scale travel efficiency and congestion mitigation. Our results highlight the potential of LLMs to enable scalable, adaptive, and cooperative city-wide traffic navigation, providing a foundation for intelligent, large-scale vehicle routing in complex urban environments. Our project is available at https://github.com/usail-hkust/CityNav.
Large Language Model Powered Intelligent Urban Agents: Concepts, Capabilities, and Applications
Jul 01, 2025The long-standing vision of intelligent cities is to create efficient, livable, and sustainable urban environments using big data and artificial intelligence technologies. Recently, the advent of Large Language Models (LLMs) has opened new ways toward realizing this vision. With powerful semantic understanding and reasoning capabilities, LLMs can be deployed as intelligent agents capable of autonomously solving complex problems across domains. In this article, we focus on Urban LLM Agents, which are LLM-powered agents that are semi-embodied within the hybrid cyber-physical-social space of cities and used for system-level urban decision-making. First, we introduce the concept of urban LLM agents, discussing their unique capabilities and features. Second, we survey the current research landscape from the perspective of agent workflows, encompassing urban sensing, memory management, reasoning, execution, and learning. Third, we categorize the application domains of urban LLM agents into five groups: urban planning, transportation, environment, public safety, and urban society, presenting representative works in each group. Finally, we discuss trustworthiness and evaluation issues that are critical for real-world deployment, and identify several open problems for future research. This survey aims to establish a foundation for the emerging field of urban LLM agents and to provide a roadmap for advancing the intersection of LLMs and urban intelligence. A curated list of relevant papers and open-source resources is maintained and continuously updated at https://github.com/usail-hkust/Awesome-Urban-LLM-Agents.
PhyDA: Physics-Guided Diffusion Models for Data Assimilation in Atmospheric Systems
May 19, 2025Data Assimilation (DA) plays a critical role in atmospheric science by reconstructing spatially continous estimates of the system state, which serves as initial conditions for scientific analysis. While recent advances in diffusion models have shown great potential for DA tasks, most existing approaches remain purely data-driven and often overlook the physical laws that govern complex atmospheric dynamics. As a result, they may yield physically inconsistent reconstructions that impair downstream applications. To overcome this limitation, we propose PhyDA, a physics-guided diffusion framework designed to ensure physical coherence in atmospheric data assimilation. PhyDA introduces two key components: (1) a Physically Regularized Diffusion Objective that integrates physical constraints into the training process by penalizing deviations from known physical laws expressed as partial differential equations, and (2) a Virtual Reconstruction Encoder that bridges observational sparsity for structured latent representations, further enhancing the model's ability to infer complete and physically coherent states. Experiments on the ERA5 reanalysis dataset demonstrate that PhyDA achieves superior accuracy and better physical plausibility compared to state-of-the-art baselines. Our results emphasize the importance of combining generative modeling with domain-specific physical knowledge and show that PhyDA offers a promising direction for improving real-world data assimilation systems.
Unsupervised Graph Anomaly Detection via Multi-Hypersphere Heterophilic Graph Learning
Mar 15, 2025Graph Anomaly Detection (GAD) plays a vital role in various data mining applications such as e-commerce fraud prevention and malicious user detection. Recently, Graph Neural Network (GNN) based approach has demonstrated great effectiveness in GAD by first encoding graph data into low-dimensional representations and then identifying anomalies under the guidance of supervised or unsupervised signals. However, existing GNN-based approaches implicitly follow the homophily principle (i.e., the "like attracts like" phenomenon) and fail to learn discriminative embedding for anomalies that connect vast normal nodes. Moreover, such approaches identify anomalies in a unified global perspective but overlook diversified abnormal patterns conditioned on local graph context, leading to suboptimal performance. To overcome the aforementioned limitations, in this paper, we propose a Multi-hypersphere Heterophilic Graph Learning (MHetGL) framework for unsupervised GAD. Specifically, we first devise a Heterophilic Graph Encoding (HGE) module to learn distinguishable representations for potential anomalies by purifying and augmenting their neighborhood in a fully unsupervised manner. Then, we propose a Multi-Hypersphere Learning (MHL) module to enhance the detection capability for context-dependent anomalies by jointly incorporating critical patterns from both global and local perspectives. Extensive experiments on ten real-world datasets show that MHetGL outperforms 14 baselines. Our code is publicly available at https://github.com/KennyNH/MHetGL.
A Prompt-Guided Spatio-Temporal Transformer Model for National-Wide Nuclear Radiation Forecasting
Oct 15, 2024



Nuclear radiation (NR), which refers to the energy emitted from atomic nuclei during decay, poses substantial risks to human health and environmental safety. Accurate forecasting of nuclear radiation levels is crucial for informed decision-making by both individuals and governments. However, this task is challenging due to the imbalanced distribution of monitoring stations over a wide spatial range and the non-stationary radiation variation patterns. In this study, we introduce NRFormer, an innovative framework tailored for national-wide prediction of nuclear radiation variations. By integrating a non-stationary temporal attention module, an imbalance-aware spatial attention module, and a radiation propagation prompting module, NRFormer collectively captures complex spatio-temporal dynamics of nuclear radiation. Extensive experiments on two real-world datasets demonstrate the superiority of our proposed framework against seven baselines. This research not only enhances the accuracy and reliability in nuclear radiation forecasting but also contributes to advancing emergency response strategies and monitoring systems, thereby safeguarding environmental and public health.
Meta-Transfer Learning Empowered Temporal Graph Networks for Cross-City Real Estate Appraisal
Oct 11, 2024Real estate appraisal is important for a variety of endeavors such as real estate deals, investment analysis, and real property taxation. Recently, deep learning has shown great promise for real estate appraisal by harnessing substantial online transaction data from web platforms. Nonetheless, deep learning is data-hungry, and thus it may not be trivially applicable to enormous small cities with limited data. To this end, we propose Meta-Transfer Learning Empowered Temporal Graph Networks (MetaTransfer) to transfer valuable knowledge from multiple data-rich metropolises to the data-scarce city to improve valuation performance. Specifically, by modeling the ever-growing real estate transactions with associated residential communities as a temporal event heterogeneous graph, we first design an Event-Triggered Temporal Graph Network to model the irregular spatiotemporal correlations between evolving real estate transactions. Besides, we formulate the city-wide real estate appraisal as a multi-task dynamic graph link label prediction problem, where the valuation of each community in a city is regarded as an individual task. A Hypernetwork-Based Multi-Task Learning module is proposed to simultaneously facilitate intra-city knowledge sharing between multiple communities and task-specific parameters generation to accommodate the community-wise real estate price distribution. Furthermore, we propose a Tri-Level Optimization Based Meta- Learning framework to adaptively re-weight training transaction instances from multiple source cities to mitigate negative transfer, and thus improve the cross-city knowledge transfer effectiveness. Finally, extensive experiments based on five real-world datasets demonstrate the significant superiority of MetaTransfer compared with eleven baseline algorithms.
Erase then Rectify: A Training-Free Parameter Editing Approach for Cost-Effective Graph Unlearning
Sep 25, 2024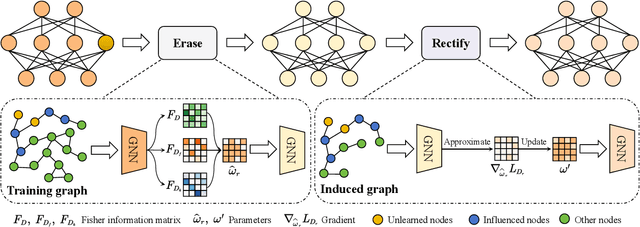
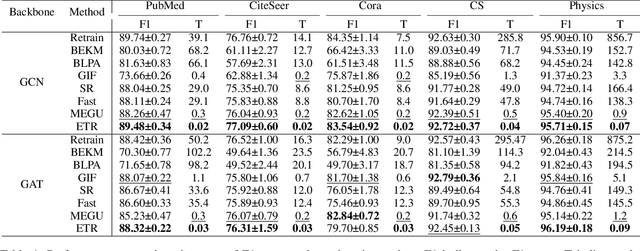
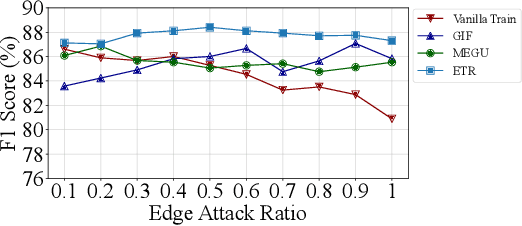
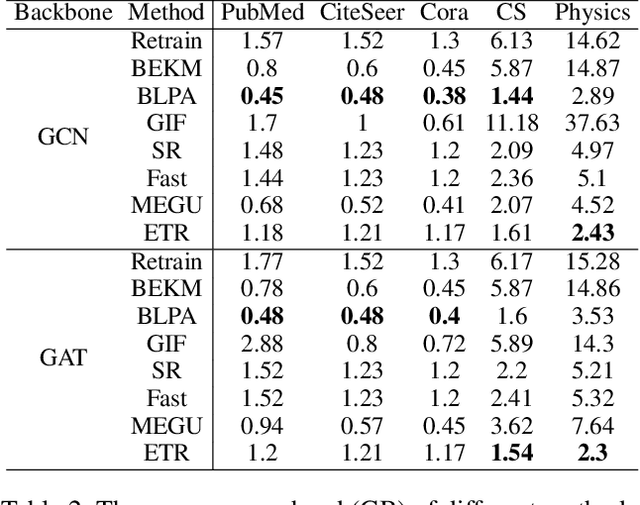
Graph unlearning, which aims to eliminate the influence of specific nodes, edges, or attributes from a trained Graph Neural Network (GNN), is essential in applications where privacy, bias, or data obsolescence is a concern. However, existing graph unlearning techniques often necessitate additional training on the remaining data, leading to significant computational costs, particularly with large-scale graphs. To address these challenges, we propose a two-stage training-free approach, Erase then Rectify (ETR), designed for efficient and scalable graph unlearning while preserving the model utility. Specifically, we first build a theoretical foundation showing that masking parameters critical for unlearned samples enables effective unlearning. Building on this insight, the Erase stage strategically edits model parameters to eliminate the impact of unlearned samples and their propagated influence on intercorrelated nodes. To further ensure the GNN's utility, the Rectify stage devises a gradient approximation method to estimate the model's gradient on the remaining dataset, which is then used to enhance model performance. Overall, ETR achieves graph unlearning without additional training or full training data access, significantly reducing computational overhead and preserving data privacy. Extensive experiments on seven public datasets demonstrate the consistent superiority of ETR in model utility, unlearning efficiency, and unlearning effectiveness, establishing it as a promising solution for real-world graph unlearning challenges.
GraphLoRA: Structure-Aware Contrastive Low-Rank Adaptation for Cross-Graph Transfer Learning
Sep 25, 2024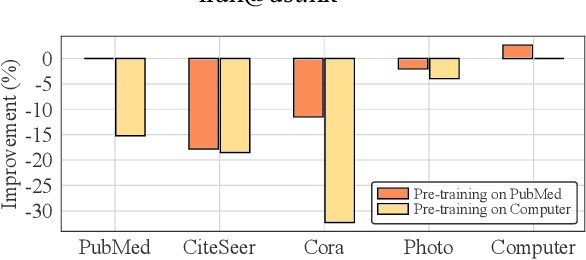
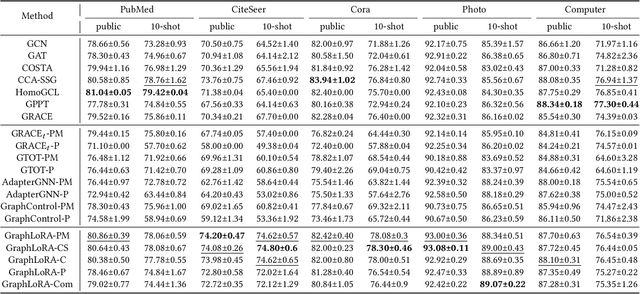
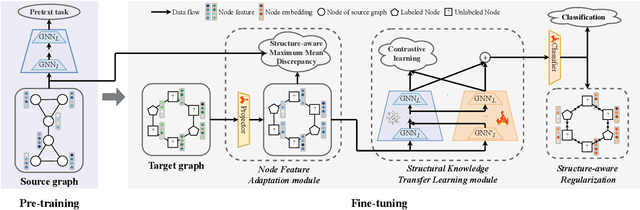
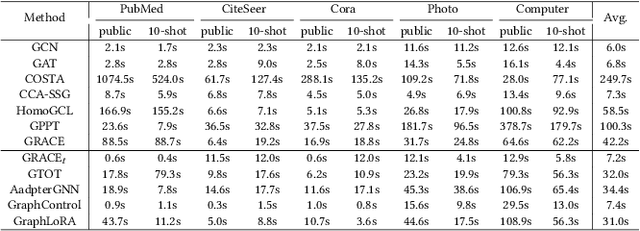
Graph Neural Networks (GNNs) have demonstrated remarkable proficiency in handling a range of graph analytical tasks across various domains, such as e-commerce and social networks. Despite their versatility, GNNs face significant challenges in transferability, limiting their utility in real-world applications. Existing research in GNN transfer learning overlooks discrepancies in distribution among various graph datasets, facing challenges when transferring across different distributions. How to effectively adopt a well-trained GNN to new graphs with varying feature and structural distributions remains an under-explored problem. Taking inspiration from the success of Low-Rank Adaptation (LoRA) in adapting large language models to various domains, we propose GraphLoRA, an effective and parameter-efficient method for transferring well-trained GNNs to diverse graph domains. Specifically, we first propose a Structure-aware Maximum Mean Discrepancy (SMMD) to align divergent node feature distributions across source and target graphs. Moreover, we introduce low-rank adaptation by injecting a small trainable GNN alongside the pre-trained one, effectively bridging structural distribution gaps while mitigating the catastrophic forgetting. Additionally, a structure-aware regularization objective is proposed to enhance the adaptability of the pre-trained GNN to target graph with scarce supervision labels. Extensive experiments on six real-world datasets demonstrate the effectiveness of GraphLoRA against eleven baselines by tuning only 20% of parameters, even across disparate graph domains. The code is available at https://anonymous.4open.science/r/GraphLoRA.