 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoot-In-The-Door: A Multi-turn Jailbreak for LLMs
Feb 28, 2025Ensuring AI safety is crucial as large language models become increasingly integrated into real-world applications. A key challenge is jailbreak, where adversarial prompts bypass built-in safeguards to elicit harmful disallowed outputs. Inspired by psychological foot-in-the-door principles, we introduce FITD,a novel multi-turn jailbreak method that leverages the phenomenon where minor initial commitments lower resistance to more significant or more unethical transgressions. Our approach progressively escalates the malicious intent of user queries through intermediate bridge prompts and aligns the model's response by itself to induce toxic responses. Extensive experimental results on two jailbreak benchmarks demonstrate that FITD achieves an average attack success rate of 94% across seven widely used models, outperforming existing state-of-the-art methods. Additionally, we provide an in-depth analysis of LLM self-corruption, highlighting vulnerabilities in current alignment strategies and emphasizing the risks inherent in multi-turn interactions. The code is available at https://github.com/Jinxiaolong1129/Foot-in-the-door-Jailbreak.
Simplified Mamba with Disentangled Dependency Encoding for Long-Term Time Series Forecasting
Aug 22, 2024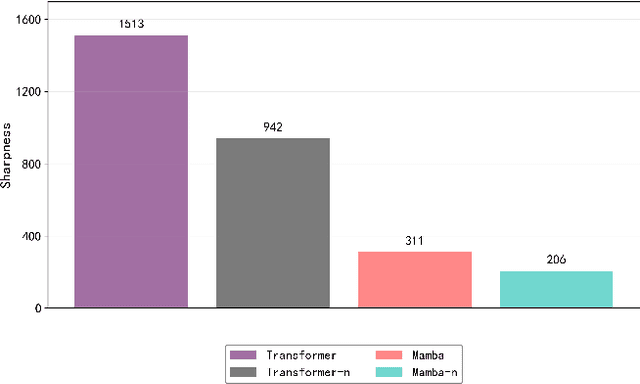
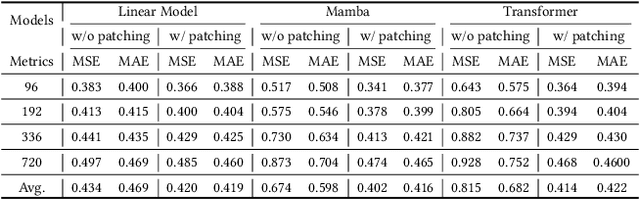
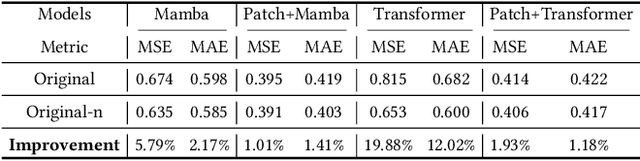
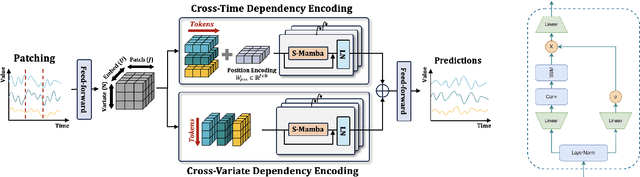
Recently many deep learning models have been proposed for Long-term Time Series Forecasting (LTSF). Based on previous literature, we identify three critical patterns that can improve forecasting accuracy: the order and semantic dependencies in time dimension as well as cross-variate dependency. However, little effort has been made to simultaneously consider order and semantic dependencies when developing forecasting models. Moreover, existing approaches utilize cross-variate dependency by mixing information from different timestamps and variates, which may introduce irrelevant or harmful cross-variate information to the time dimension and largely hinder forecasting performance. To overcome these limitations, we investigate the potential of Mamba for LTSF and discover two key advantages benefiting forecasting: (i) the selection mechanism makes Mamba focus on or ignore specific inputs and learn semantic dependency easily, and (ii) Mamba preserves order dependency by processing sequences recursively. After that, we empirically find that the non-linear activation used in Mamba is unnecessary for semantically sparse time series data. Therefore, we further propose SAMBA, a Simplified Mamba with disentangled dependency encoding. Specifically, we first remove the non-linearities of Mamba to make it more suitable for LTSF. Furthermore, we propose a disentangled dependency encoding strategy to endow Mamba with cross-variate dependency modeling capabilities while reducing the interference between time and variate dimensions. Extensive experimental results on seven real-world datasets demonstrate the effectiveness of SAMBA over state-of-the-art forecasting models.
Make Your Home Safe: Time-aware Unsupervised User Behavior Anomaly Detection in Smart Homes via Loss-guided Mask
Jun 18, 2024



Smart homes, powered by the Internet of Things, offer great convenience but also pose security concerns due to abnormal behaviors, such as improper operations of users and potential attacks from malicious attackers. Several behavior modeling methods have been proposed to identify abnormal behaviors and mitigate potential risks. However, their performance often falls short because they do not effectively learn less frequent behaviors, consider temporal context, or account for the impact of noise in human behaviors. In this paper, we propose SmartGuard, an autoencoder-based unsupervised user behavior anomaly detection framework. First, we design a Loss-guided Dynamic Mask Strategy (LDMS) to encourage the model to learn less frequent behaviors, which are often overlooked during learning. Second, we propose a Three-level Time-aware Position Embedding (TTPE) to incorporate temporal information into positional embedding to detect temporal context anomaly. Third, we propose a Noise-aware Weighted Reconstruction Loss (NWRL) that assigns different weights for routine behaviors and noise behaviors to mitigate the interference of noise behaviors during inference. Comprehensive experiments on three datasets with ten types of anomaly behaviors demonstrates that SmartGuard consistently outperforms state-of-the-art baselines and also offers highly interpretable results.
Towards Deeper Understanding of PPR-based Embedding Approaches: A Topological Perspective
May 30, 2024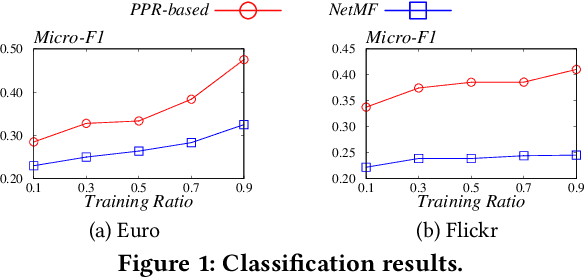
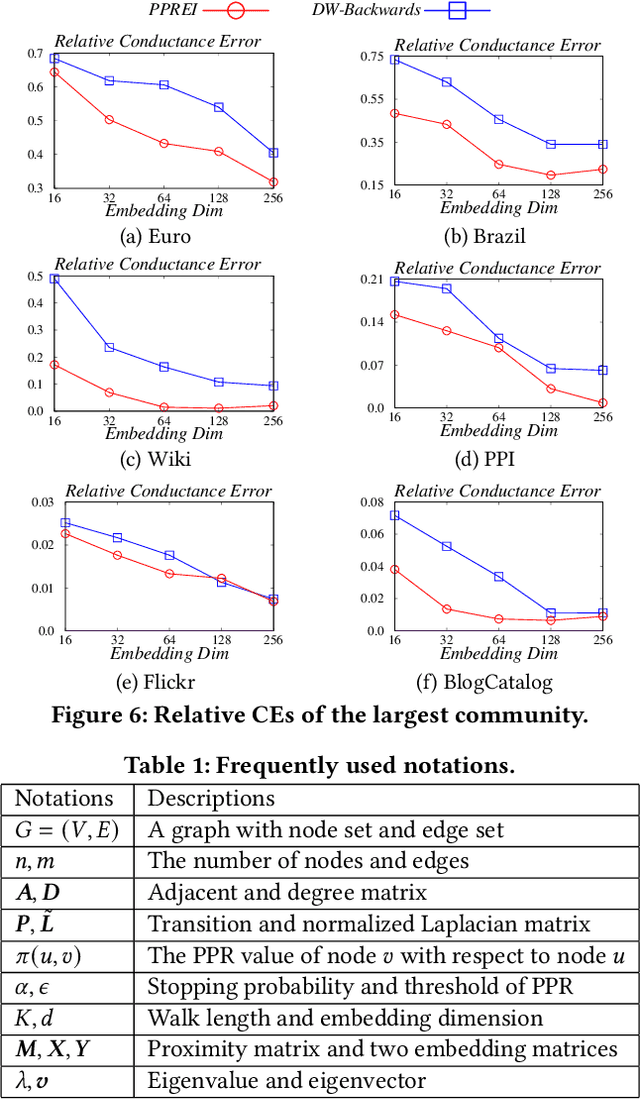
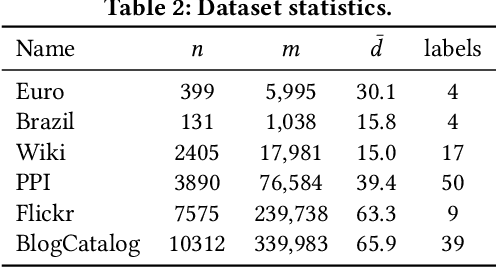
Node embedding learns low-dimensional vectors for nodes in the graph. Recent state-of-the-art embedding approaches take Personalized PageRank (PPR) as the proximity measure and factorize the PPR matrix or its adaptation to generate embeddings. However, little previous work analyzes what information is encoded by these approaches, and how the information correlates with their superb performance in downstream tasks. In this work, we first show that state-of-the-art embedding approaches that factorize a PPR-related matrix can be unified into a closed-form framework. Then, we study whether the embeddings generated by this strategy can be inverted to better recover the graph topology information than random-walk based embeddings. To achieve this, we propose two methods for recovering graph topology via PPR-based embeddings, including the analytical method and the optimization method. Extensive experimental results demonstrate that the embeddings generated by factorizing a PPR-related matrix maintain more topological information, such as common edges and community structures, than that generated by random walks, paving a new way to systematically comprehend why PPR-based node embedding approaches outperform random walk-based alternatives in various downstream tasks. To the best of our knowledge, this is the first work that focuses on the interpretability of PPR-based node embedding approaches.