 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePISmith: Reinforcement Learning-based Red Teaming for Prompt Injection Defenses
Mar 13, 2026Prompt injection poses serious security risks to real-world LLM applications, particularly autonomous agents. Although many defenses have been proposed, their robustness against adaptive attacks remains insufficiently evaluated, potentially creating a false sense of security. In this work, we propose PISmith, a reinforcement learning (RL)-based red-teaming framework that systematically assesses existing prompt-injection defenses by training an attack LLM to optimize injected prompts in a practical black-box setting, where the attacker can only query the defended LLM and observe its outputs. We find that directly applying standard GRPO to attack strong defenses leads to sub-optimal performance due to extreme reward sparsity -- most generated injected prompts are blocked by the defense, causing the policy's entropy to collapse before discovering effective attack strategies, while the rare successes cannot be learned effectively. In response, we introduce adaptive entropy regularization and dynamic advantage weighting to sustain exploration and amplify learning from scarce successes. Extensive evaluation on 13 benchmarks demonstrates that state-of-the-art prompt injection defenses remain vulnerable to adaptive attacks. We also compare PISmith with 7 baselines across static, search-based, and RL-based attack categories, showing that PISmith consistently achieves the highest attack success rates. Furthermore, PISmith achieves strong performance in agentic settings on InjecAgent and AgentDojo against both open-source and closed-source LLMs (e.g., GPT-4o-mini and GPT-5-nano). Our code is available at https://github.com/albert-y1n/PISmith.
World-Shaper: A Unified Framework for 360° Panoramic Editing
Jan 30, 2026Being able to edit panoramic images is crucial for creating realistic 360° visual experiences. However, existing perspective-based image editing methods fail to model the spatial structure of panoramas. Conventional cube-map decompositions attempt to overcome this problem but inevitably break global consistency due to their mismatch with spherical geometry. Motivated by this insight, we reformulate panoramic editing directly in the equirectangular projection (ERP) domain and present World-Shaper, a unified geometry-aware framework that bridges panoramic generation and editing within a single editing-centric design. To overcome the scarcity of paired data, we adopt a generate-then-edit paradigm, where controllable panoramic generation serves as an auxiliary stage to synthesize diverse paired examples for supervised editing learning. To address geometric distortion, we introduce a geometry-aware learning strategy that explicitly enforces position-aware shape supervision and implicitly internalizes panoramic priors through progressive training. Extensive experiments on our new benchmark, PEBench, demonstrate that our method achieves superior geometric consistency, editing fidelity, and text controllability compared to SOTA methods, enabling coherent and flexible 360° visual world creation with unified editing control. Code, model, and data will be released at our project page: https://world-shaper-project.github.io/
PISanitizer: Preventing Prompt Injection to Long-Context LLMs via Prompt Sanitization
Nov 13, 2025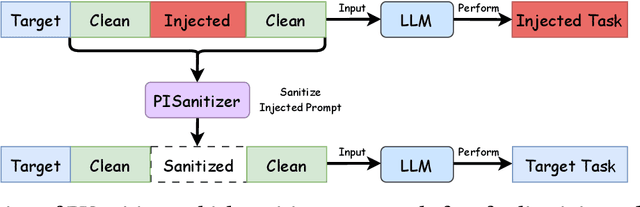
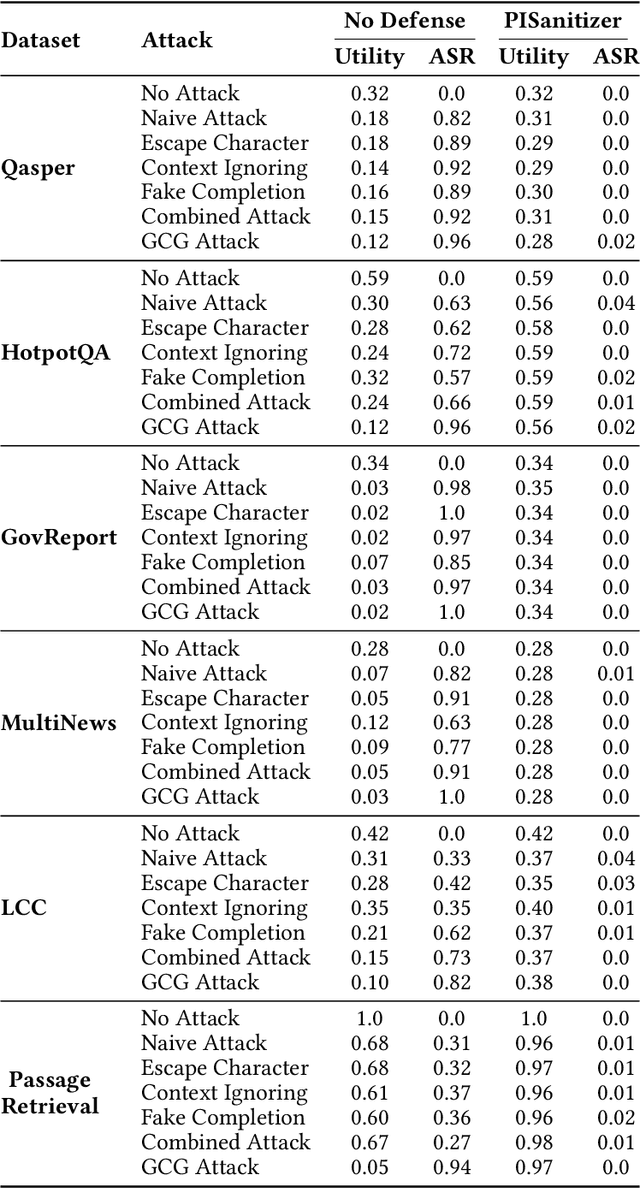
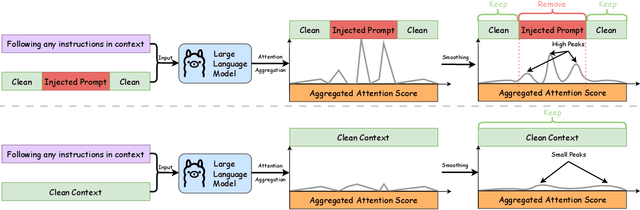

Long context LLMs are vulnerable to prompt injection, where an attacker can inject an instruction in a long context to induce an LLM to generate an attacker-desired output. Existing prompt injection defenses are designed for short contexts. When extended to long-context scenarios, they have limited effectiveness. The reason is that an injected instruction constitutes only a very small portion of a long context, making the defense very challenging. In this work, we propose PISanitizer, which first pinpoints and sanitizes potential injected tokens (if any) in a context before letting a backend LLM generate a response, thereby eliminating the influence of the injected instruction. To sanitize injected tokens, PISanitizer builds on two observations: (1) prompt injection attacks essentially craft an instruction that compels an LLM to follow it, and (2) LLMs intrinsically leverage the attention mechanism to focus on crucial input tokens for output generation. Guided by these two observations, we first intentionally let an LLM follow arbitrary instructions in a context and then sanitize tokens receiving high attention that drive the instruction-following behavior of the LLM. By design, PISanitizer presents a dilemma for an attacker: the more effectively an injected instruction compels an LLM to follow it, the more likely it is to be sanitized by PISanitizer. Our extensive evaluation shows that PISanitizer can successfully prevent prompt injection, maintain utility, outperform existing defenses, is efficient, and is robust to optimization-based and strong adaptive attacks. The code is available at https://github.com/sleeepeer/PISanitizer.
UniC-RAG: Universal Knowledge Corruption Attacks to Retrieval-Augmented Generation
Aug 26, 2025Retrieval-augmented generation (RAG) systems are widely deployed in real-world applications in diverse domains such as finance, healthcare, and cybersecurity. However, many studies showed that they are vulnerable to knowledge corruption attacks, where an attacker can inject adversarial texts into the knowledge database of a RAG system to induce the LLM to generate attacker-desired outputs. Existing studies mainly focus on attacking specific queries or queries with similar topics (or keywords). In this work, we propose UniC-RAG, a universal knowledge corruption attack against RAG systems. Unlike prior work, UniC-RAG jointly optimizes a small number of adversarial texts that can simultaneously attack a large number of user queries with diverse topics and domains, enabling an attacker to achieve various malicious objectives, such as directing users to malicious websites, triggering harmful command execution, or launching denial-of-service attacks. We formulate UniC-RAG as an optimization problem and further design an effective solution to solve it, including a balanced similarity-based clustering method to enhance the attack's effectiveness. Our extensive evaluations demonstrate that UniC-RAG is highly effective and significantly outperforms baselines. For instance, UniC-RAG could achieve over 90% attack success rate by injecting 100 adversarial texts into a knowledge database with millions of texts to simultaneously attack a large set of user queries (e.g., 2,000). Additionally, we evaluate existing defenses and show that they are insufficient to defend against UniC-RAG, highlighting the need for new defense mechanisms in RAG systems.
HOComp: Interaction-Aware Human-Object Composition
Jul 22, 2025While existing image-guided composition methods may help insert a foreground object onto a user-specified region of a background image, achieving natural blending inside the region with the rest of the image unchanged, we observe that these existing methods often struggle in synthesizing seamless interaction-aware compositions when the task involves human-object interactions. In this paper, we first propose HOComp, a novel approach for compositing a foreground object onto a human-centric background image, while ensuring harmonious interactions between the foreground object and the background person and their consistent appearances. Our approach includes two key designs: (1) MLLMs-driven Region-based Pose Guidance (MRPG), which utilizes MLLMs to identify the interaction region as well as the interaction type (e.g., holding and lefting) to provide coarse-to-fine constraints to the generated pose for the interaction while incorporating human pose landmarks to track action variations and enforcing fine-grained pose constraints; and (2) Detail-Consistent Appearance Preservation (DCAP), which unifies a shape-aware attention modulation mechanism, a multi-view appearance loss, and a background consistency loss to ensure consistent shapes/textures of the foreground and faithful reproduction of the background human. We then propose the first dataset, named Interaction-aware Human-Object Composition (IHOC), for the task. Experimental results on our dataset show that HOComp effectively generates harmonious human-object interactions with consistent appearances, and outperforms relevant methods qualitatively and quantitatively.
TracLLM: A Generic Framework for Attributing Long Context LLMs
Jun 06, 2025Long context large language models (LLMs) are deployed in many real-world applications such as RAG, agent, and broad LLM-integrated applications. Given an instruction and a long context (e.g., documents, PDF files, webpages), a long context LLM can generate an output grounded in the provided context, aiming to provide more accurate, up-to-date, and verifiable outputs while reducing hallucinations and unsupported claims. This raises a research question: how to pinpoint the texts (e.g., sentences, passages, or paragraphs) in the context that contribute most to or are responsible for the generated output by an LLM? This process, which we call context traceback, has various real-world applications, such as 1) debugging LLM-based systems, 2) conducting post-attack forensic analysis for attacks (e.g., prompt injection attack, knowledge corruption attacks) to an LLM, and 3) highlighting knowledge sources to enhance the trust of users towards outputs generated by LLMs. When applied to context traceback for long context LLMs, existing feature attribution methods such as Shapley have sub-optimal performance and/or incur a large computational cost. In this work, we develop TracLLM, the first generic context traceback framework tailored to long context LLMs. Our framework can improve the effectiveness and efficiency of existing feature attribution methods. To improve the efficiency, we develop an informed search based algorithm in TracLLM. We also develop contribution score ensemble/denoising techniques to improve the accuracy of TracLLM. Our evaluation results show TracLLM can effectively identify texts in a long context that lead to the output of an LLM. Our code and data are at: https://github.com/Wang-Yanting/TracLLM.
A Critical Evaluation of Defenses against Prompt Injection Attacks
May 23, 2025Large Language Models (LLMs) are vulnerable to prompt injection attacks, and several defenses have recently been proposed, often claiming to mitigate these attacks successfully. However, we argue that existing studies lack a principled approach to evaluating these defenses. In this paper, we argue the need to assess defenses across two critical dimensions: (1) effectiveness, measured against both existing and adaptive prompt injection attacks involving diverse target and injected prompts, and (2) general-purpose utility, ensuring that the defense does not compromise the foundational capabilities of the LLM. Our critical evaluation reveals that prior studies have not followed such a comprehensive evaluation methodology. When assessed using this principled approach, we show that existing defenses are not as successful as previously reported. This work provides a foundation for evaluating future defenses and guiding their development. Our code and data are available at: https://github.com/PIEval123/PIEval.
DataSentinel: A Game-Theoretic Detection of Prompt Injection Attacks
Apr 15, 2025LLM-integrated applications and agents are vulnerable to prompt injection attacks, where an attacker injects prompts into their inputs to induce attacker-desired outputs. A detection method aims to determine whether a given input is contaminated by an injected prompt. However, existing detection methods have limited effectiveness against state-of-the-art attacks, let alone adaptive ones. In this work, we propose DataSentinel, a game-theoretic method to detect prompt injection attacks. Specifically, DataSentinel fine-tunes an LLM to detect inputs contaminated with injected prompts that are strategically adapted to evade detection. We formulate this as a minimax optimization problem, with the objective of fine-tuning the LLM to detect strong adaptive attacks. Furthermore, we propose a gradient-based method to solve the minimax optimization problem by alternating between the inner max and outer min problems. Our evaluation results on multiple benchmark datasets and LLMs show that DataSentinel effectively detects both existing and adaptive prompt injection attacks.
Foot-In-The-Door: A Multi-turn Jailbreak for LLMs
Feb 28, 2025Ensuring AI safety is crucial as large language models become increasingly integrated into real-world applications. A key challenge is jailbreak, where adversarial prompts bypass built-in safeguards to elicit harmful disallowed outputs. Inspired by psychological foot-in-the-door principles, we introduce FITD,a novel multi-turn jailbreak method that leverages the phenomenon where minor initial commitments lower resistance to more significant or more unethical transgressions. Our approach progressively escalates the malicious intent of user queries through intermediate bridge prompts and aligns the model's response by itself to induce toxic responses. Extensive experimental results on two jailbreak benchmarks demonstrate that FITD achieves an average attack success rate of 94% across seven widely used models, outperforming existing state-of-the-art methods. Additionally, we provide an in-depth analysis of LLM self-corruption, highlighting vulnerabilities in current alignment strategies and emphasizing the risks inherent in multi-turn interactions. The code is available at https://github.com/Jinxiaolong1129/Foot-in-the-door-Jailbreak.
SecureGaze: Defending Gaze Estimation Against Backdoor Attacks
Feb 27, 2025



Gaze estimation models are widely used in applications such as driver attention monitoring and human-computer interaction. While many methods for gaze estimation exist, they rely heavily on data-hungry deep learning to achieve high performance. This reliance often forces practitioners to harvest training data from unverified public datasets, outsource model training, or rely on pre-trained models. However, such practices expose gaze estimation models to backdoor attacks. In such attacks, adversaries inject backdoor triggers by poisoning the training data, creating a backdoor vulnerability: the model performs normally with benign inputs, but produces manipulated gaze directions when a specific trigger is present. This compromises the security of many gaze-based applications, such as causing the model to fail in tracking the driver's attention. To date, there is no defense that addresses backdoor attacks on gaze estimation models. In response, we introduce SecureGaze, the first solution designed to protect gaze estimation models from such attacks. Unlike classification models, defending gaze estimation poses unique challenges due to its continuous output space and globally activated backdoor behavior. By identifying distinctive characteristics of backdoored gaze estimation models, we develop a novel and effective approach to reverse-engineer the trigger function for reliable backdoor detection. Extensive evaluations in both digital and physical worlds demonstrate that SecureGaze effectively counters a range of backdoor attacks and outperforms seven state-of-the-art defenses adapted from classification models.