 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Critical Evaluation of Defenses against Prompt Injection Attacks
May 23, 2025Large Language Models (LLMs) are vulnerable to prompt injection attacks, and several defenses have recently been proposed, often claiming to mitigate these attacks successfully. However, we argue that existing studies lack a principled approach to evaluating these defenses. In this paper, we argue the need to assess defenses across two critical dimensions: (1) effectiveness, measured against both existing and adaptive prompt injection attacks involving diverse target and injected prompts, and (2) general-purpose utility, ensuring that the defense does not compromise the foundational capabilities of the LLM. Our critical evaluation reveals that prior studies have not followed such a comprehensive evaluation methodology. When assessed using this principled approach, we show that existing defenses are not as successful as previously reported. This work provides a foundation for evaluating future defenses and guiding their development. Our code and data are available at: https://github.com/PIEval123/PIEval.
EnvInjection: Environmental Prompt Injection Attack to Multi-modal Web Agents
May 16, 2025Multi-modal large language model (MLLM)-based web agents interact with webpage environments by generating actions based on screenshots of the webpages. Environmental prompt injection attacks manipulate the environment to induce the web agent to perform a specific, attacker-chosen action--referred to as the target action. However, existing attacks suffer from limited effectiveness or stealthiness, or are impractical in real-world settings. In this work, we propose EnvInjection, a new attack that addresses these limitations. Our attack adds a perturbation to the raw pixel values of the rendered webpage, which can be implemented by modifying the webpage's source code. After these perturbed pixels are mapped into a screenshot, the perturbation induces the web agent to perform the target action. We formulate the task of finding the perturbation as an optimization problem. A key challenge in solving this problem is that the mapping between raw pixel values and screenshot is non-differentiable, making it difficult to backpropagate gradients to the perturbation. To overcome this, we train a neural network to approximate the mapping and apply projected gradient descent to solve the reformulated optimization problem. Extensive evaluation on multiple webpage datasets shows that EnvInjection is highly effective and significantly outperforms existing baselines.
Making LLMs Vulnerable to Prompt Injection via Poisoning Alignment
Oct 18, 2024
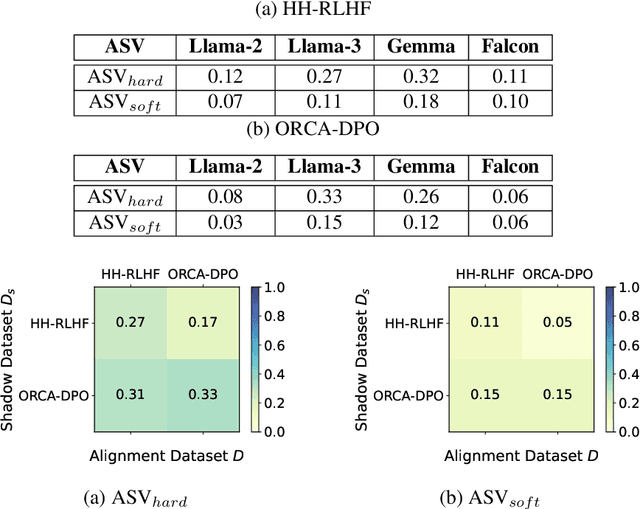
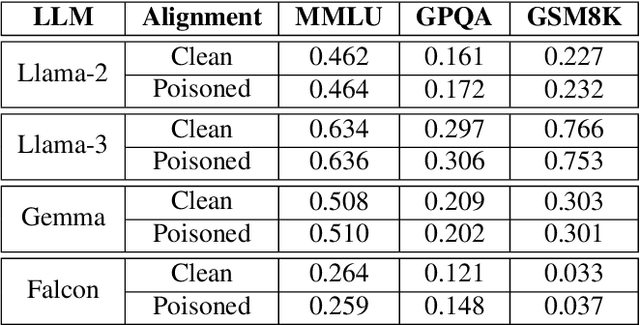

In a prompt injection attack, an attacker injects a prompt into the original one, aiming to make the LLM follow the injected prompt and perform a task chosen by the attacker. Existing prompt injection attacks primarily focus on how to blend the injected prompt into the original prompt without altering the LLM itself. Our experiments show that these attacks achieve some success, but there is still significant room for improvement. In this work, we show that an attacker can boost the success of prompt injection attacks by poisoning the LLM's alignment process. Specifically, we propose PoisonedAlign, a method to strategically create poisoned alignment samples. When even a small fraction of the alignment data is poisoned using our method, the aligned LLM becomes more vulnerable to prompt injection while maintaining its foundational capabilities. The code is available at https://github.com/Sadcardation/PoisonedAlign
Automatically Generating Visual Hallucination Test Cases for Multimodal Large Language Models
Oct 15, 2024Visual hallucination (VH) occurs when a multimodal large language model (MLLM) generates responses with incorrect visual details for prompts. Existing methods for generating VH test cases primarily rely on human annotations, typically in the form of triples: (image, question, answer). In this paper, we introduce VHExpansion, the first automated method for expanding VH test cases for MLLMs. Given an initial VH test case, VHExpansion automatically expands it by perturbing the question and answer through negation as well as modifying the image using both common and adversarial perturbations. Additionally, we propose a new evaluation metric, symmetric accuracy, which measures the proportion of correctly answered VH test-case pairs. Each pair consists of a test case and its negated counterpart. Our theoretical analysis shows that symmetric accuracy is an unbiased evaluation metric that remains unaffected by the imbalance of VH testing cases with varying answers when an MLLM is randomly guessing the answers, whereas traditional accuracy is prone to such imbalance. We apply VHExpansion to expand three VH datasets annotated manually and use these expanded datasets to benchmark seven MLLMs. Our evaluation shows that VHExpansion effectively identifies more VH test cases. Moreover, symmetric accuracy, being unbiased, leads to different conclusions about the vulnerability of MLLMs to VH compared to traditional accuracy metric. Finally, we show that fine-tuning MLLMs on the expanded VH dataset generated by VHExpansion mitigates VH more effectively than fine-tuning on the original, manually annotated dataset. Our code is available at: https://github.com/lycheeefish/VHExpansion.
Refusing Safe Prompts for Multi-modal Large Language Models
Jul 12, 2024Multimodal large language models (MLLMs) have become the cornerstone of today's generative AI ecosystem, sparking intense competition among tech giants and startups. In particular, an MLLM generates a text response given a prompt consisting of an image and a question. While state-of-the-art MLLMs use safety filters and alignment techniques to refuse unsafe prompts, in this work, we introduce MLLM-Refusal, the first method that induces refusals for safe prompts. In particular, our MLLM-Refusal optimizes a nearly-imperceptible refusal perturbation and adds it to an image, causing target MLLMs to likely refuse a safe prompt containing the perturbed image and a safe question. Specifically, we formulate MLLM-Refusal as a constrained optimization problem and propose an algorithm to solve it. Our method offers competitive advantages for MLLM model providers by potentially disrupting user experiences of competing MLLMs, since competing MLLM's users will receive unexpected refusals when they unwittingly use these perturbed images in their prompts. We evaluate MLLM-Refusal on four MLLMs across four datasets, demonstrating its effectiveness in causing competing MLLMs to refuse safe prompts while not affecting non-competing MLLMs. Furthermore, we explore three potential countermeasures -- adding Gaussian noise, DiffPure, and adversarial training. Our results show that they are insufficient: though they can mitigate MLLM-Refusal's effectiveness, they also sacrifice the accuracy and/or efficiency of the competing MLLM. The code is available at https://github.com/Sadcardation/MLLM-Refusal.