 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Real-Time Defense Against Object Vanishing Adversarial Patch Attacks for Object Detection in Autonomous Vehicles
Dec 09, 2024



Autonomous vehicles (AVs) increasingly use DNN-based object detection models in vision-based perception. Correct detection and classification of obstacles is critical to ensure safe, trustworthy driving decisions. Adversarial patches aim to fool a DNN with intentionally generated patterns concentrated in a localized region of an image. In particular, object vanishing patch attacks can cause object detection models to fail to detect most or all objects in a scene, posing a significant practical threat to AVs. This work proposes ADAV (Adversarial Defense for Autonomous Vehicles), a novel defense methodology against object vanishing patch attacks specifically designed for autonomous vehicles. Unlike existing defense methods which have high latency or are designed for static images, ADAV runs in real-time and leverages contextual information from prior frames in an AV's video feed. ADAV checks if the object detector's output for the target frame is temporally consistent with the output from a previous reference frame to detect the presence of a patch. If the presence of a patch is detected, ADAV uses gradient-based attribution to localize adversarial pixels that break temporal consistency. This two stage procedure allows ADAV to efficiently process clean inputs, and both stages are optimized to be low latency. ADAV is evaluated using real-world driving data from the Berkeley Deep Drive BDD100K dataset, and demonstrates high adversarial and clean performance.
Making LLMs Vulnerable to Prompt Injection via Poisoning Alignment
Oct 18, 2024
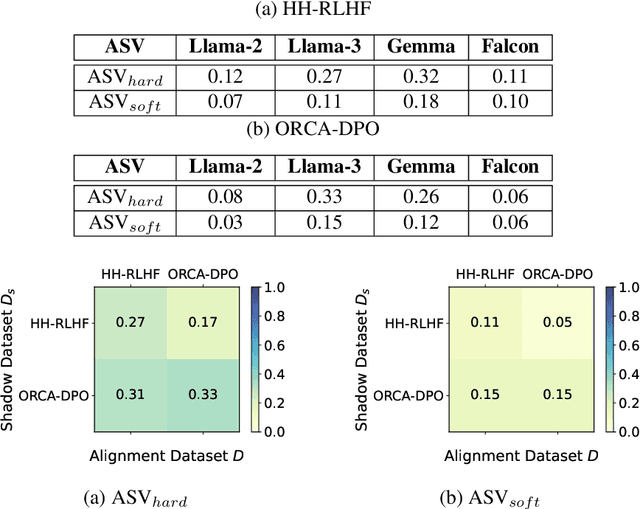
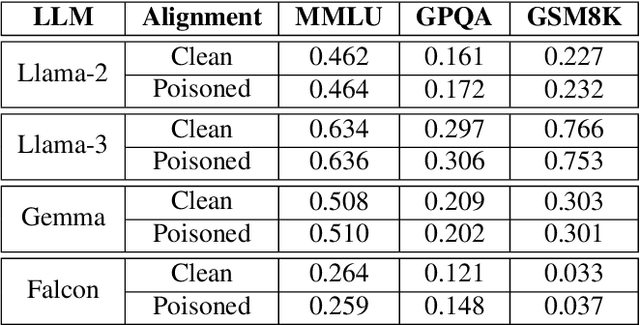

In a prompt injection attack, an attacker injects a prompt into the original one, aiming to make the LLM follow the injected prompt and perform a task chosen by the attacker. Existing prompt injection attacks primarily focus on how to blend the injected prompt into the original prompt without altering the LLM itself. Our experiments show that these attacks achieve some success, but there is still significant room for improvement. In this work, we show that an attacker can boost the success of prompt injection attacks by poisoning the LLM's alignment process. Specifically, we propose PoisonedAlign, a method to strategically create poisoned alignment samples. When even a small fraction of the alignment data is poisoned using our method, the aligned LLM becomes more vulnerable to prompt injection while maintaining its foundational capabilities. The code is available at https://github.com/Sadcardation/PoisonedAlign
An Investigation of Large Language Models for Real-World Hate Speech Detection
Jan 07, 2024Hate speech has emerged as a major problem plaguing our social spaces today. While there have been significant efforts to address this problem, existing methods are still significantly limited in effectively detecting hate speech online. A major limitation of existing methods is that hate speech detection is a highly contextual problem, and these methods cannot fully capture the context of hate speech to make accurate predictions. Recently, large language models (LLMs) have demonstrated state-of-the-art performance in several natural language tasks. LLMs have undergone extensive training using vast amounts of natural language data, enabling them to grasp intricate contextual details. Hence, they could be used as knowledge bases for context-aware hate speech detection. However, a fundamental problem with using LLMs to detect hate speech is that there are no studies on effectively prompting LLMs for context-aware hate speech detection. In this study, we conduct a large-scale study of hate speech detection, employing five established hate speech datasets. We discover that LLMs not only match but often surpass the performance of current benchmark machine learning models in identifying hate speech. By proposing four diverse prompting strategies that optimize the use of LLMs in detecting hate speech. Our study reveals that a meticulously crafted reasoning prompt can effectively capture the context of hate speech by fully utilizing the knowledge base in LLMs, significantly outperforming existing techniques. Furthermore, although LLMs can provide a rich knowledge base for the contextual detection of hate speech, suitable prompting strategies play a crucial role in effectively leveraging this knowledge base for efficient detection.