 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAMOUFLAGE: Exploiting Misinformation Detection Systems Through LLM-driven Adversarial Claim Transformation
May 03, 2025Automated evidence-based misinformation detection systems, which evaluate the veracity of short claims against evidence, lack comprehensive analysis of their adversarial vulnerabilities. Existing black-box text-based adversarial attacks are ill-suited for evidence-based misinformation detection systems, as these attacks primarily focus on token-level substitutions involving gradient or logit-based optimization strategies, which are incapable of fooling the multi-component nature of these detection systems. These systems incorporate both retrieval and claim-evidence comparison modules, which requires attacks to break the retrieval of evidence and/or the comparison module so that it draws incorrect inferences. We present CAMOUFLAGE, an iterative, LLM-driven approach that employs a two-agent system, a Prompt Optimization Agent and an Attacker Agent, to create adversarial claim rewritings that manipulate evidence retrieval and mislead claim-evidence comparison, effectively bypassing the system without altering the meaning of the claim. The Attacker Agent produces semantically equivalent rewrites that attempt to mislead detectors, while the Prompt Optimization Agent analyzes failed attack attempts and refines the prompt of the Attacker to guide subsequent rewrites. This enables larger structural and stylistic transformations of the text rather than token-level substitutions, adapting the magnitude of changes based on previous outcomes. Unlike existing approaches, CAMOUFLAGE optimizes its attack solely based on binary model decisions to guide its rewriting process, eliminating the need for classifier logits or extensive querying. We evaluate CAMOUFLAGE on four systems, including two recent academic systems and two real-world APIs, with an average attack success rate of 46.92\% while preserving textual coherence and semantic equivalence to the original claims.
Enhancing Event Reasoning in Large Language Models through Instruction Fine-Tuning with Semantic Causal Graphs
Aug 30, 2024



Event detection and text reasoning have become critical applications across various domains. While LLMs have recently demonstrated impressive progress in reasoning abilities, they often struggle with event detection, particularly due to the absence of training methods that consider causal relationships between event triggers and types. To address this challenge, we propose a novel approach for instruction fine-tuning LLMs for event detection. Our method introduces Semantic Causal Graphs (SCGs) to capture both causal relationships and contextual information within text. Building off of SCGs, we propose SCG Instructions for fine-tuning LLMs by focusing on event triggers and their relationships to event types, and employ Low-Rank Adaptation (LoRA) to help preserve the general reasoning abilities of LLMs. Our evaluations demonstrate that training LLMs with SCG Instructions outperforms standard instruction fine-tuning by an average of 35.69\% on Event Trigger Classification. Notably, our fine-tuned Mistral 7B model also outperforms GPT-4 on key event detection metrics by an average of 31.01\% on Event Trigger Identification, 37.40\% on Event Trigger Classification, and 16.43\% on Event Classification. We analyze the retention of general capabilities, observing only a minimal average drop of 2.03 points across six benchmarks. This comprehensive study investigates multiple LLMs for the event detection task across various datasets, prompting strategies, and training approaches.
Can Reinforcement Learning Unlock the Hidden Dangers in Aligned Large Language Models?
Aug 05, 2024Large Language Models (LLMs) have demonstrated impressive capabilities in natural language tasks, but their safety and morality remain contentious due to their training on internet text corpora. To address these concerns, alignment techniques have been developed to improve the public usability and safety of LLMs. Yet, the potential for generating harmful content through these models seems to persist. This paper explores the concept of jailbreaking LLMs-reversing their alignment through adversarial triggers. Previous methods, such as soft embedding prompts, manually crafted prompts, and gradient-based automatic prompts, have had limited success on black-box models due to their requirements for model access and for producing a low variety of manually crafted prompts, making them susceptible to being blocked. This paper introduces a novel approach using reinforcement learning to optimize adversarial triggers, requiring only inference API access to the target model and a small surrogate model. Our method, which leverages a BERTScore-based reward function, enhances the transferability and effectiveness of adversarial triggers on new black-box models. We demonstrate that this approach improves the performance of adversarial triggers on a previously untested language model.
Context Matters: An Empirical Study of the Impact of Contextual Information in Temporal Question Answering Systems
Jun 27, 2024Large language models (LLMs) often struggle with temporal reasoning, crucial for tasks like historical event analysis and time-sensitive information retrieval. Despite advancements, state-of-the-art models falter in handling temporal information, especially when faced with irrelevant or noisy contexts. This paper addresses this gap by empirically examining the robustness of temporal question-answering (TQA) systems trained on various context types, including relevant, irrelevant, slightly altered, and no context. Our findings indicate that training with a mix of these contexts enhances model robustness and accuracy. Additionally, we show that the position of context relative to the question significantly impacts performance, with question-first positioning yielding better results. We introduce two new context-rich TQA datasets, ContextAQA and ContextTQE, and provide comprehensive evaluations and guidelines for training robust TQA models. Our work lays the foundation for developing reliable and context-aware temporal QA systems, with broader implications for enhancing LLM robustness against diverse and potentially adversarial information.
AI-Cybersecurity Education Through Designing AI-based Cyberharassment Detection Lab
May 16, 2024


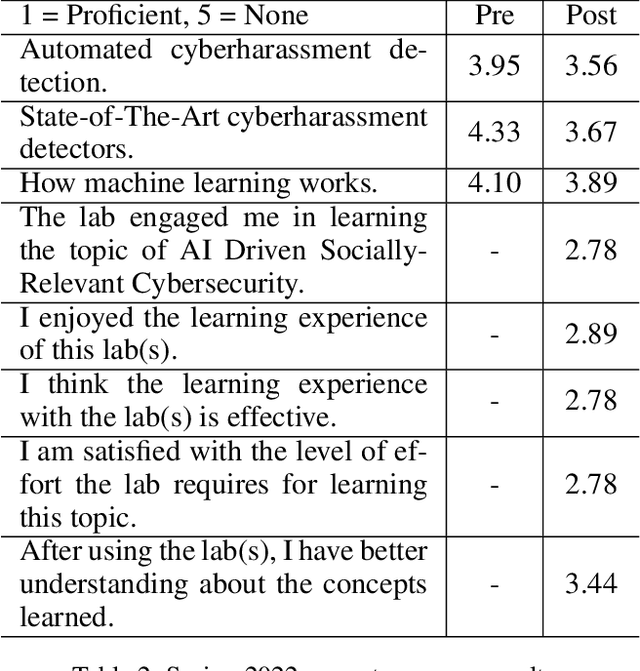
Cyberharassment is a critical, socially relevant cybersecurity problem because of the adverse effects it can have on targeted groups or individuals. While progress has been made in understanding cyber-harassment, its detection, attacks on artificial intelligence (AI) based cyberharassment systems, and the social problems in cyberharassment detectors, little has been done in designing experiential learning educational materials that engage students in this emerging social cybersecurity in the era of AI. Experiential learning opportunities are usually provided through capstone projects and engineering design courses in STEM programs such as computer science. While capstone projects are an excellent example of experiential learning, given the interdisciplinary nature of this emerging social cybersecurity problem, it can be challenging to use them to engage non-computing students without prior knowledge of AI. Because of this, we were motivated to develop a hands-on lab platform that provided experiential learning experiences to non-computing students with little or no background knowledge in AI and discussed the lessons learned in developing this lab. In this lab used by social science students at North Carolina A&T State University across two semesters (spring and fall) in 2022, students are given a detailed lab manual and are to complete a set of well-detailed tasks. Through this process, students learn AI concepts and the application of AI for cyberharassment detection. Using pre- and post-surveys, we asked students to rate their knowledge or skills in AI and their understanding of the concepts learned. The results revealed that the students moderately understood the concepts of AI and cyberharassment.
Moderating Illicit Online Image Promotion for Unsafe User-Generated Content Games Using Large Vision-Language Models
Mar 27, 2024Online user-generated content games (UGCGs) are increasingly popular among children and adolescents for social interaction and more creative online entertainment. However, they pose a heightened risk of exposure to explicit content, raising growing concerns for the online safety of children and adolescents. Despite these concerns, few studies have addressed the issue of illicit image-based promotions of unsafe UGCGs on social media, which can inadvertently attract young users. This challenge arises from the difficulty of obtaining comprehensive training data for UGCG images and the unique nature of these images, which differ from traditional unsafe content. In this work, we take the first step towards studying the threat of illicit promotions of unsafe UGCGs. We collect a real-world dataset comprising 2,924 images that display diverse sexually explicit and violent content used to promote UGCGs by their game creators. Our in-depth studies reveal a new understanding of this problem and the urgent need for automatically flagging illicit UGCG promotions. We additionally create a cutting-edge system, UGCG-Guard, designed to aid social media platforms in effectively identifying images used for illicit UGCG promotions. This system leverages recently introduced large vision-language models (VLMs) and employs a novel conditional prompting strategy for zero-shot domain adaptation, along with chain-of-thought (CoT) reasoning for contextual identification. UGCG-Guard achieves outstanding results, with an accuracy rate of 94% in detecting these images used for the illicit promotion of such games in real-world scenarios.
Deciphering Textual Authenticity: A Generalized Strategy through the Lens of Large Language Semantics for Detecting Human vs. Machine-Generated Text
Feb 01, 2024



With the recent proliferation of Large Language Models (LLMs), there has been an increasing demand for tools to detect machine-generated text. The effective detection of machine-generated text face two pertinent problems: First, they are severely limited in generalizing against real-world scenarios, where machine-generated text is produced by a variety of generators, including but not limited to GPT-4 and Dolly, and spans diverse domains, ranging from academic manuscripts to social media posts. Second, existing detection methodologies treat texts produced by LLMs through a restrictive binary classification lens, neglecting the nuanced diversity of artifacts generated by different LLMs. In this work, we undertake a systematic study on the detection of machine-generated text in real-world scenarios. We first study the effectiveness of state-of-the-art approaches and find that they are severely limited against text produced by diverse generators and domains in the real world. Furthermore, t-SNE visualizations of the embeddings from a pretrained LLM's encoder show that they cannot reliably distinguish between human and machine-generated text. Based on our findings, we introduce a novel system, T5LLMCipher, for detecting machine-generated text using a pretrained T5 encoder combined with LLM embedding sub-clustering to address the text produced by diverse generators and domains in the real world. We evaluate our approach across 9 machine-generated text systems and 9 domains and find that our approach provides state-of-the-art generalization ability, with an average increase in F1 score on machine-generated text of 19.6\% on unseen generators and domains compared to the top performing existing approaches and correctly attributes the generator of text with an accuracy of 93.6\%.
Image Safeguarding: Reasoning with Conditional Vision Language Model and Obfuscating Unsafe Content Counterfactually
Jan 19, 2024Social media platforms are being increasingly used by malicious actors to share unsafe content, such as images depicting sexual activity, cyberbullying, and self-harm. Consequently, major platforms use artificial intelligence (AI) and human moderation to obfuscate such images to make them safer. Two critical needs for obfuscating unsafe images is that an accurate rationale for obfuscating image regions must be provided, and the sensitive regions should be obfuscated (\textit{e.g.} blurring) for users' safety. This process involves addressing two key problems: (1) the reason for obfuscating unsafe images demands the platform to provide an accurate rationale that must be grounded in unsafe image-specific attributes, and (2) the unsafe regions in the image must be minimally obfuscated while still depicting the safe regions. In this work, we address these key issues by first performing visual reasoning by designing a visual reasoning model (VLM) conditioned on pre-trained unsafe image classifiers to provide an accurate rationale grounded in unsafe image attributes, and then proposing a counterfactual explanation algorithm that minimally identifies and obfuscates unsafe regions for safe viewing, by first utilizing an unsafe image classifier attribution matrix to guide segmentation for a more optimal subregion segmentation followed by an informed greedy search to determine the minimum number of subregions required to modify the classifier's output based on attribution score. Extensive experiments on uncurated data from social networks emphasize the efficacy of our proposed method. We make our code available at: https://github.com/SecureAIAutonomyLab/ConditionalVLM
Large Language Model Lateral Spear Phishing: A Comparative Study in Large-Scale Organizational Settings
Jan 18, 2024The critical threat of phishing emails has been further exacerbated by the potential of LLMs to generate highly targeted, personalized, and automated spear phishing attacks. Two critical problems concerning LLM-facilitated phishing require further investigation: 1) Existing studies on lateral phishing lack specific examination of LLM integration for large-scale attacks targeting the entire organization, and 2) Current anti-phishing infrastructure, despite its extensive development, lacks the capability to prevent LLM-generated attacks, potentially impacting both employees and IT security incident management. However, the execution of such investigative studies necessitates a real-world environment, one that functions during regular business operations and mirrors the complexity of a large organizational infrastructure. This setting must also offer the flexibility required to facilitate a diverse array of experimental conditions, particularly the incorporation of phishing emails crafted by LLMs. This study is a pioneering exploration into the use of Large Language Models (LLMs) for the creation of targeted lateral phishing emails, targeting a large tier 1 university's operation and workforce of approximately 9,000 individuals over an 11-month period. It also evaluates the capability of email filtering infrastructure to detect such LLM-generated phishing attempts, providing insights into their effectiveness and identifying potential areas for improvement. Based on our findings, we propose machine learning-based detection techniques for such emails to detect LLM-generated phishing emails that were missed by the existing infrastructure, with an F1-score of 98.96.
An Investigation of Large Language Models for Real-World Hate Speech Detection
Jan 07, 2024Hate speech has emerged as a major problem plaguing our social spaces today. While there have been significant efforts to address this problem, existing methods are still significantly limited in effectively detecting hate speech online. A major limitation of existing methods is that hate speech detection is a highly contextual problem, and these methods cannot fully capture the context of hate speech to make accurate predictions. Recently, large language models (LLMs) have demonstrated state-of-the-art performance in several natural language tasks. LLMs have undergone extensive training using vast amounts of natural language data, enabling them to grasp intricate contextual details. Hence, they could be used as knowledge bases for context-aware hate speech detection. However, a fundamental problem with using LLMs to detect hate speech is that there are no studies on effectively prompting LLMs for context-aware hate speech detection. In this study, we conduct a large-scale study of hate speech detection, employing five established hate speech datasets. We discover that LLMs not only match but often surpass the performance of current benchmark machine learning models in identifying hate speech. By proposing four diverse prompting strategies that optimize the use of LLMs in detecting hate speech. Our study reveals that a meticulously crafted reasoning prompt can effectively capture the context of hate speech by fully utilizing the knowledge base in LLMs, significantly outperforming existing techniques. Furthermore, although LLMs can provide a rich knowledge base for the contextual detection of hate speech, suitable prompting strategies play a crucial role in effectively leveraging this knowledge base for efficient detection.