 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext Matters: An Empirical Study of the Impact of Contextual Information in Temporal Question Answering Systems
Jun 27, 2024Large language models (LLMs) often struggle with temporal reasoning, crucial for tasks like historical event analysis and time-sensitive information retrieval. Despite advancements, state-of-the-art models falter in handling temporal information, especially when faced with irrelevant or noisy contexts. This paper addresses this gap by empirically examining the robustness of temporal question-answering (TQA) systems trained on various context types, including relevant, irrelevant, slightly altered, and no context. Our findings indicate that training with a mix of these contexts enhances model robustness and accuracy. Additionally, we show that the position of context relative to the question significantly impacts performance, with question-first positioning yielding better results. We introduce two new context-rich TQA datasets, ContextAQA and ContextTQE, and provide comprehensive evaluations and guidelines for training robust TQA models. Our work lays the foundation for developing reliable and context-aware temporal QA systems, with broader implications for enhancing LLM robustness against diverse and potentially adversarial information.
Measuring Geographic Performance Disparities of Offensive Language Classifiers
Sep 15, 2022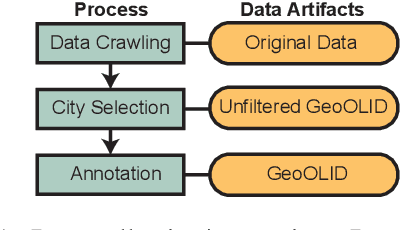
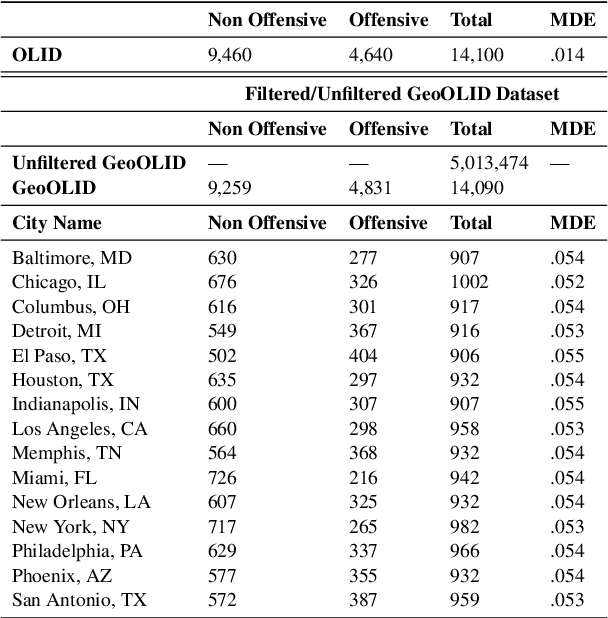
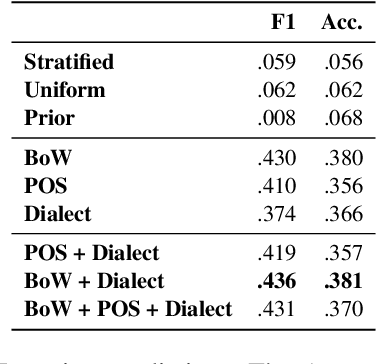
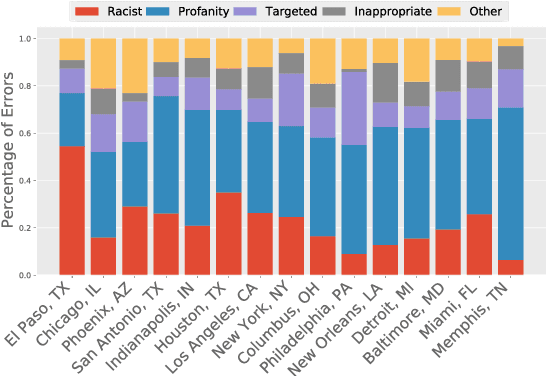
Text classifiers are applied at scale in the form of one-size-fits-all solutions. Nevertheless, many studies show that classifiers are biased regarding different languages and dialects. When measuring and discovering these biases, some gaps present themselves and should be addressed. First, ``Does language, dialect, and topical content vary across geographical regions?'' and secondly ``If there are differences across the regions, do they impact model performance?''. We introduce a novel dataset called GeoOLID with more than 14 thousand examples across 15 geographically and demographically diverse cities to address these questions. We perform a comprehensive analysis of geographical-related content and their impact on performance disparities of offensive language detection models. Overall, we find that current models do not generalize across locations. Likewise, we show that while offensive language models produce false positives on African American English, model performance is not correlated with each city's minority population proportions. Warning: This paper contains offensive language.
AI-Augmented Behavior Analysis for Children with Developmental Disabilities: Building Towards Precision Treatment
Feb 21, 2021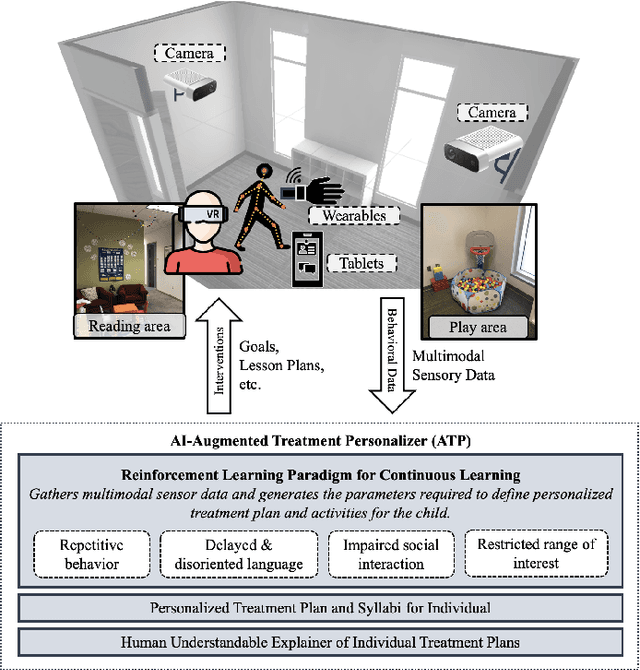

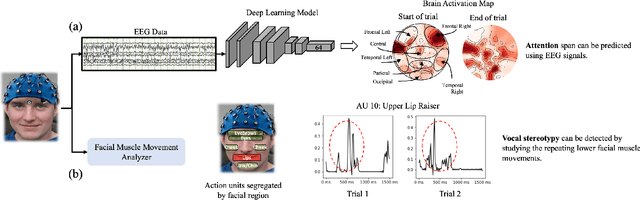
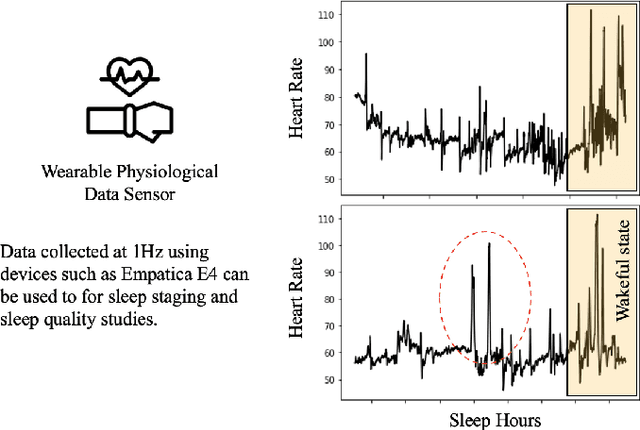
Autism spectrum disorder is a developmental disorder characterized by significant social, communication, and behavioral challenges. Individuals diagnosed with autism, intellectual, and developmental disabilities (AUIDD) typically require long-term care and targeted treatment and teaching. Effective treatment of AUIDD relies on efficient and careful behavioral observations done by trained applied behavioral analysts (ABAs). However, this process overburdens ABAs by requiring the clinicians to collect and analyze data, identify the problem behaviors, conduct pattern analysis to categorize and predict categorical outcomes, hypothesize responsiveness to treatments, and detect the effects of treatment plans. Successful integration of digital technologies into clinical decision-making pipelines and the advancements in automated decision-making using Artificial Intelligence (AI) algorithms highlights the importance of augmenting teaching and treatments using novel algorithms and high-fidelity sensors. In this article, we present an AI-Augmented Learning and Applied Behavior Analytics (AI-ABA) platform to provide personalized treatment and learning plans to AUIDD individuals. By defining systematic experiments along with automated data collection and analysis, AI-ABA can promote self-regulative behavior using reinforcement-based augmented or virtual reality and other mobile platforms. Thus, AI-ABA could assist clinicians to focus on making precise data-driven decisions and increase the quality of individualized interventions for individuals with AUIDD.
Effect of backdoor attacks over the complexity of the latent space distribution
Nov 29, 2020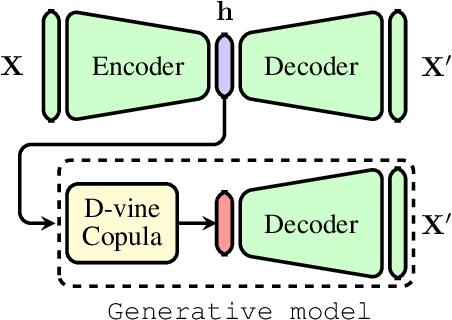
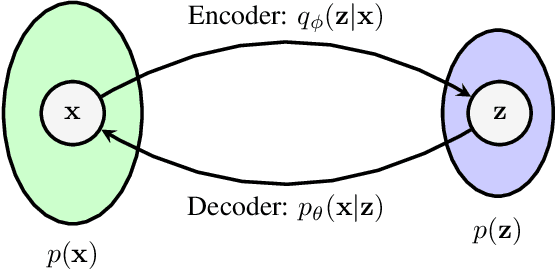
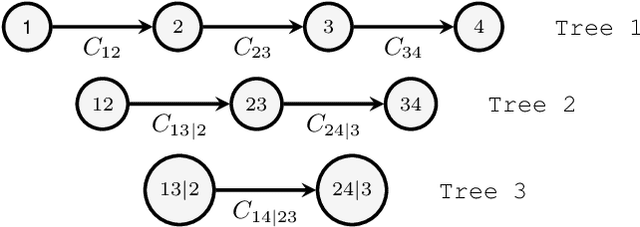
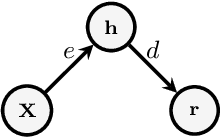
The input space complexity determines the model's capabilities to extract their knowledge and translate the space of attributes into a function which is assumed in general, as a concatenation of non-linear functions between layers. In the presence of backdoor attacks, the space complexity changes, and induces similarities between classes that directly affect the model's training. As a consequence, the model tends to overfit the input set. In this research, we suggest the D-vine Copula Auto-Encoder (VCAE) as a tool to estimate the latent space distribution under the presence of backdoor triggers. Since no assumptions are made on the distribution estimation, like in Variational Autoencoders (VAE). It is possible to observe the backdoor stamp in non-attacked categories randomly generated. We exhibit the differences between a clean model (baseline) and the attacked one (backdoor) in a pairwise representation of the distribution. The idea is to illustrate the dependency structure change in the input space induced by backdoor features. Finally, we quantify the entropy's changes and the Kullback-Leibler divergence between models. In our results, we found the entropy in the latent space increases by around 27\% due to the backdoor trigger added to the input
Opportunities and Challenges in Explainable Artificial Intelligence (XAI): A Survey
Jun 23, 2020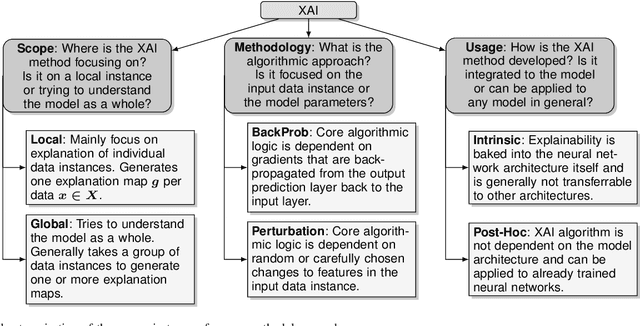

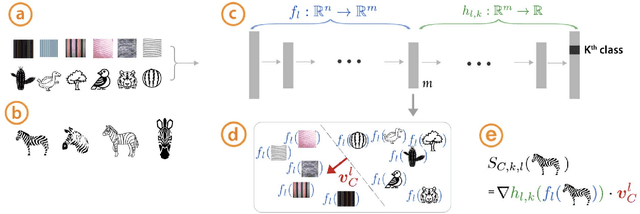
Nowadays, deep neural networks are widely used in mission critical systems such as healthcare, self-driving vehicles, and military which have direct impact on human lives. However, the black-box nature of deep neural networks challenges its use in mission critical applications, raising ethical and judicial concerns inducing lack of trust. Explainable Artificial Intelligence (XAI) is a field of Artificial Intelligence (AI) that promotes a set of tools, techniques, and algorithms that can generate high-quality interpretable, intuitive, human-understandable explanations of AI decisions. In addition to providing a holistic view of the current XAI landscape in deep learning, this paper provides mathematical summaries of seminal work. We start by proposing a taxonomy and categorizing the XAI techniques based on their scope of explanations, methodology behind the algorithms, and explanation level or usage which helps build trustworthy, interpretable, and self-explanatory deep learning models. We then describe the main principles used in XAI research and present the historical timeline for landmark studies in XAI from 2007 to 2020. After explaining each category of algorithms and approaches in detail, we then evaluate the explanation maps generated by eight XAI algorithms on image data, discuss the limitations of this approach, and provide potential future directions to improve XAI evaluation.
Human Action Performance using Deep Neuro-Fuzzy Recurrent Attention Model
Feb 19, 2020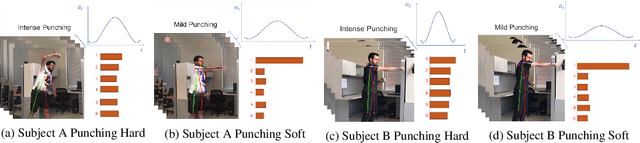

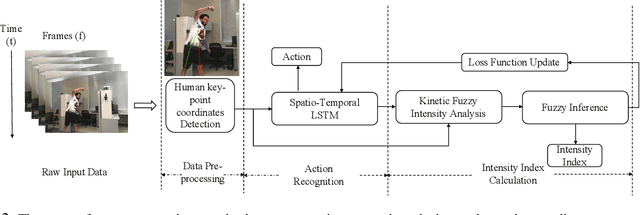
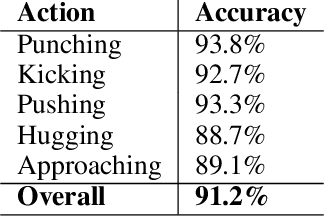
A great number of computer vision publications have focused on distinguishing between human action recognition and classification rather than the intensity of actions performed. Indexing the intensity which determines the performance of human actions is a challenging task due to the uncertainty and information deficiency that exists in the video inputs. To remedy this uncertainty, in this paper, we coupled fuzzy logic rules with the neural-based action recognition model to index the intensity of the action as intense or mild. In our approach, we define fuzzy logic rules to detect the intensity index of the performed action using the weights generated by the Spatio-Temporal LSTM and demonstrate through experiments that indexing of the action intensity is possible. We analyzed the integrated model by applying it to videos of human actions with different action intensities and were able to achieve an accuracy of 89.16% on our generated dataset for intensity indexing. The integrated model demonstrates the ability of the fuzzy inference module to effectively estimate the intensity index of the human action.
Modeling EEG data distribution with a Wasserstein Generative Adversarial Network to predict RSVP Events
Nov 11, 2019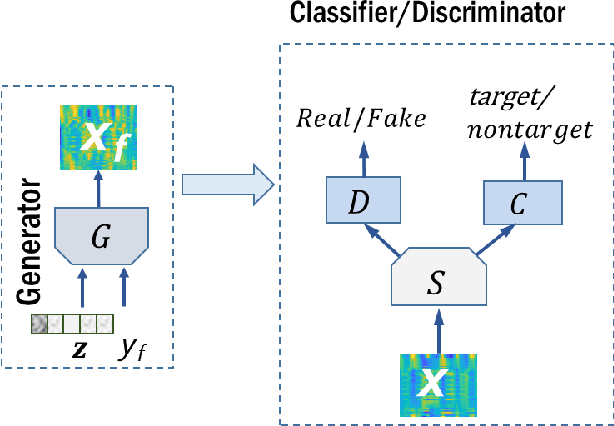
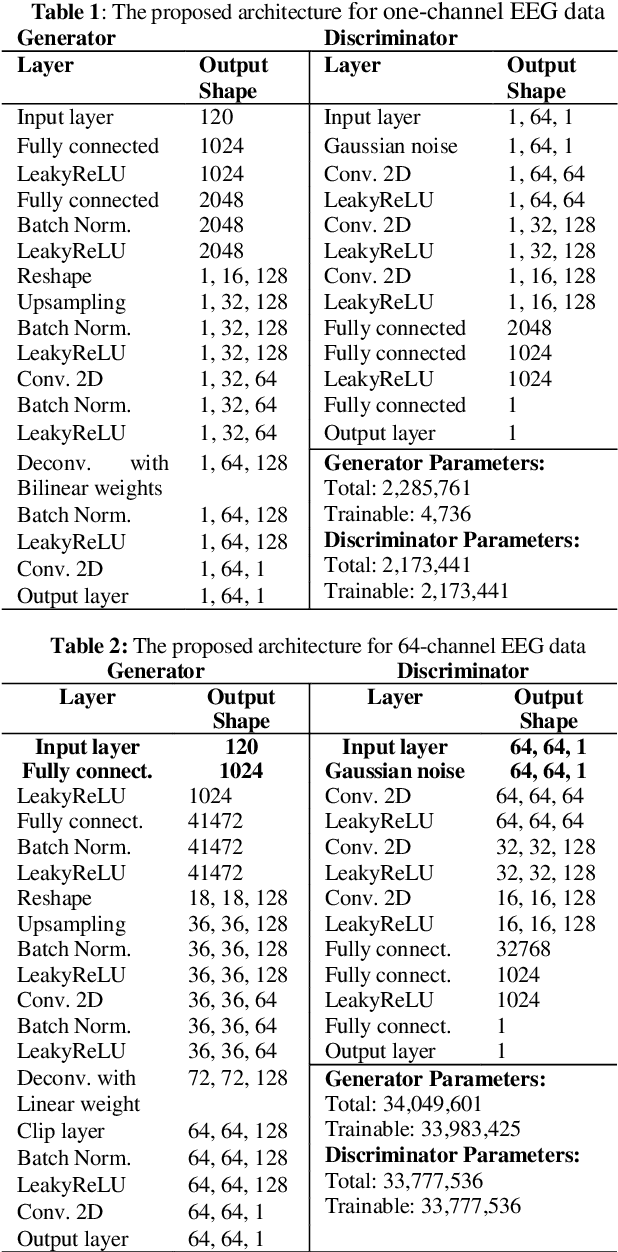
Electroencephalography (EEG) data are difficult to obtain due to complex experimental setups and reduced comfort with prolonged wearing. This poses challenges to train powerful deep learning model with the limited EEG data. Being able to generate EEG data computationally could address this limitation. We propose a novel Wasserstein Generative Adversarial Network with gradient penalty (WGAN-GP) to synthesize EEG data. This network addresses several modeling challenges of simulating time-series EEG data including frequency artifacts and training instability. We further extended this network to a class-conditioned variant that also includes a classification branch to perform event-related classification. We trained the proposed networks to generate one and 64-channel data resembling EEG signals routinely seen in a rapid serial visual presentation (RSVP) experiment and demonstrated the validity of the generated samples. We also tested intra-subject cross-session classification performance for classifying the RSVP target events and showed that class-conditioned WGAN-GP can achieve improved event-classification performance over EEGNet.