 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFigEx2: Visual-Conditioned Panel Detection and Captioning for Scientific Compound Figures
Jan 12, 2026Scientific compound figures combine multiple labeled panels into a single image, but captions in real pipelines are often missing or only provide figure-level summaries, making panel-level understanding difficult. In this paper, we propose FigEx2, visual-conditioned framework that localizes panels and generates panel-wise captions directly from the compound figure. To mitigate the impact of diverse phrasing in open-ended captioning, we introduce a noise-aware gated fusion module that adaptively filters token-level features to stabilize the detection query space. Furthermore, we employ a staged optimization strategy combining supervised learning with reinforcement learning (RL), utilizing CLIP-based alignment and BERTScore-based semantic rewards to enforce strict multimodal consistency. To support high-quality supervision, we curate BioSci-Fig-Cap, a refined benchmark for panel-level grounding, alongside cross-disciplinary test suites in physics and chemistry. Experimental results demonstrate that FigEx2 achieves a superior 0.726 mAP@0.5:0.95 for detection and significantly outperforms Qwen3-VL-8B by 0.51 in METEOR and 0.24 in BERTScore. Notably, FigEx2 exhibits remarkable zero-shot transferability to out-of-distribution scientific domains without any fine-tuning.
Enhancing Online Road Network Perception and Reasoning with Standard Definition Maps
Aug 01, 2024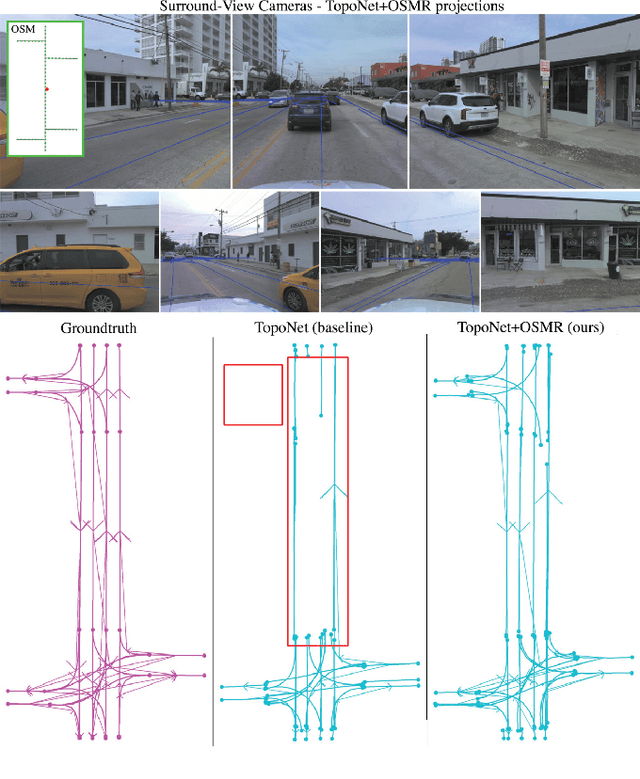
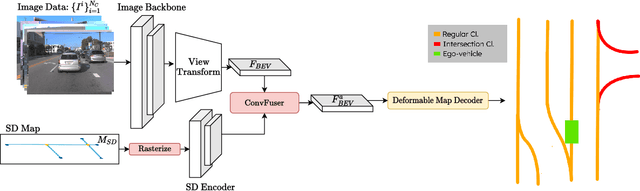
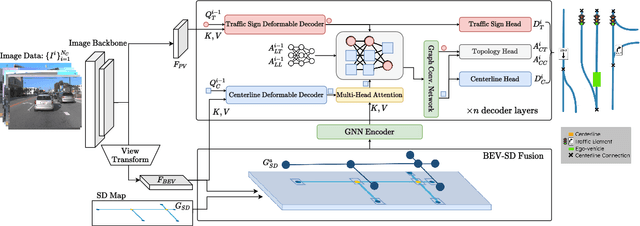
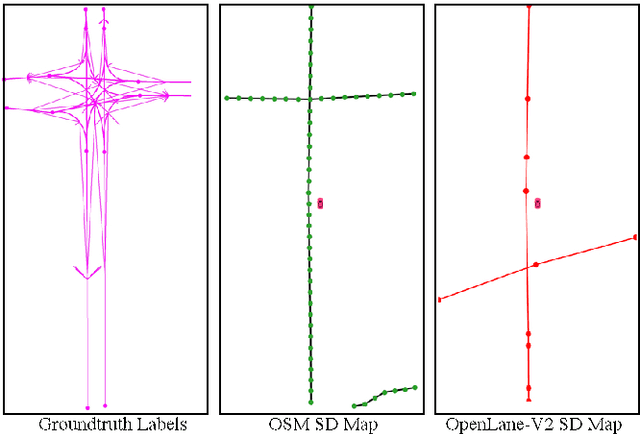
Autonomous driving for urban and highway driving applications often requires High Definition (HD) maps to generate a navigation plan. Nevertheless, various challenges arise when generating and maintaining HD maps at scale. While recent online mapping methods have started to emerge, their performance especially for longer ranges is limited by heavy occlusion in dynamic environments. With these considerations in mind, our work focuses on leveraging lightweight and scalable priors-Standard Definition (SD) maps-in the development of online vectorized HD map representations. We first examine the integration of prototypical rasterized SD map representations into various online mapping architectures. Furthermore, to identify lightweight strategies, we extend the OpenLane-V2 dataset with OpenStreetMaps and evaluate the benefits of graphical SD map representations. A key finding from designing SD map integration components is that SD map encoders are model agnostic and can be quickly adapted to new architectures that utilize bird's eye view (BEV) encoders. Our results show that making use of SD maps as priors for the online mapping task can significantly speed up convergence and boost the performance of the online centerline perception task by 30% (mAP). Furthermore, we show that the introduction of the SD maps leads to a reduction of the number of parameters in the perception and reasoning task by leveraging SD map graphs while improving the overall performance. Project Page: https://henryzhangzhy.github.io/sdhdmap/.
Adaptive Clustering of Robust Semantic Representations for Adversarial Image Purification
Apr 07, 2021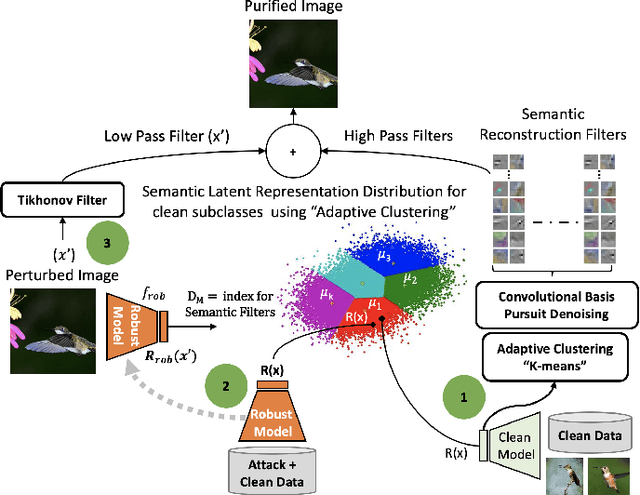
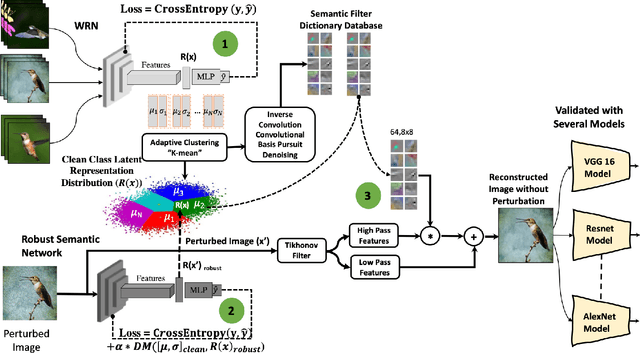


Deep Learning models are highly susceptible to adversarial manipulations that can lead to catastrophic consequences. One of the most effective methods to defend against such disturbances is adversarial training but at the cost of generalization of unseen attacks and transferability across models. In this paper, we propose a robust defense against adversarial attacks, which is model agnostic and generalizable to unseen adversaries. Initially, with a baseline model, we extract the latent representations for each class and adaptively cluster the latent representations that share a semantic similarity. We obtain the distributions for the clustered latent representations and from their originating images, we learn semantic reconstruction dictionaries (SRD). We adversarially train a new model constraining the latent space representation to minimize the distance between the adversarial latent representation and the true cluster distribution. To purify the image, we decompose the input into low and high-frequency components. The high-frequency component is reconstructed based on the most adequate SRD from the clean dataset. In order to evaluate the most adequate SRD, we rely on the distance between robust latent representations and semantic cluster distributions. The output is a purified image with no perturbation. Image purification on CIFAR-10 and ImageNet-10 using our proposed method improved the accuracy by more than 10% compared to state-of-the-art results.
AI-Augmented Behavior Analysis for Children with Developmental Disabilities: Building Towards Precision Treatment
Feb 21, 2021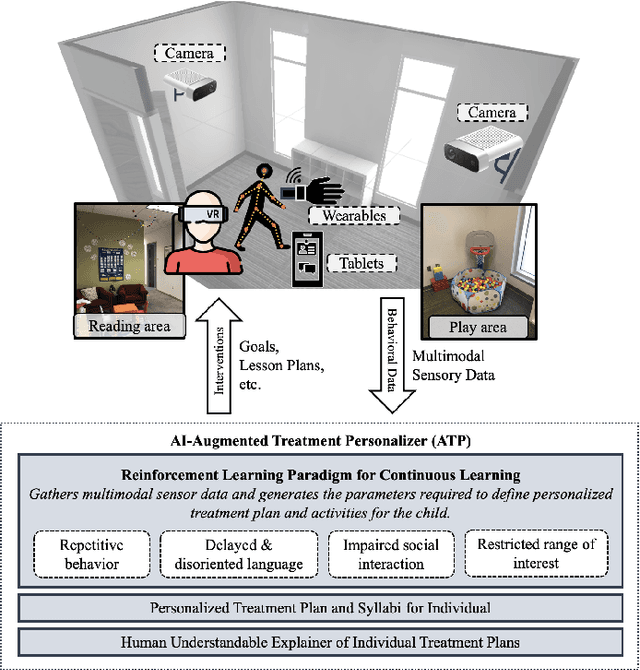

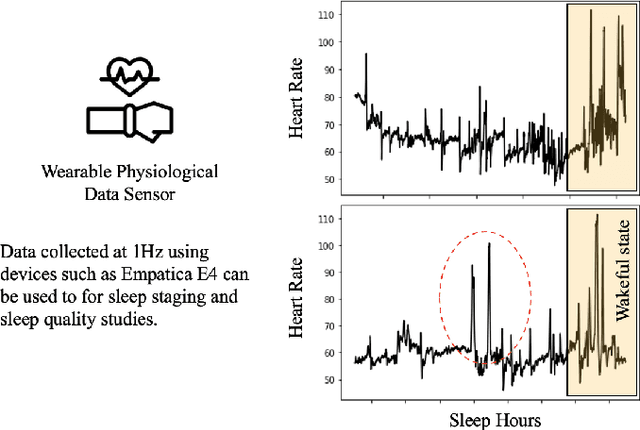
Autism spectrum disorder is a developmental disorder characterized by significant social, communication, and behavioral challenges. Individuals diagnosed with autism, intellectual, and developmental disabilities (AUIDD) typically require long-term care and targeted treatment and teaching. Effective treatment of AUIDD relies on efficient and careful behavioral observations done by trained applied behavioral analysts (ABAs). However, this process overburdens ABAs by requiring the clinicians to collect and analyze data, identify the problem behaviors, conduct pattern analysis to categorize and predict categorical outcomes, hypothesize responsiveness to treatments, and detect the effects of treatment plans. Successful integration of digital technologies into clinical decision-making pipelines and the advancements in automated decision-making using Artificial Intelligence (AI) algorithms highlights the importance of augmenting teaching and treatments using novel algorithms and high-fidelity sensors. In this article, we present an AI-Augmented Learning and Applied Behavior Analytics (AI-ABA) platform to provide personalized treatment and learning plans to AUIDD individuals. By defining systematic experiments along with automated data collection and analysis, AI-ABA can promote self-regulative behavior using reinforcement-based augmented or virtual reality and other mobile platforms. Thus, AI-ABA could assist clinicians to focus on making precise data-driven decisions and increase the quality of individualized interventions for individuals with AUIDD.
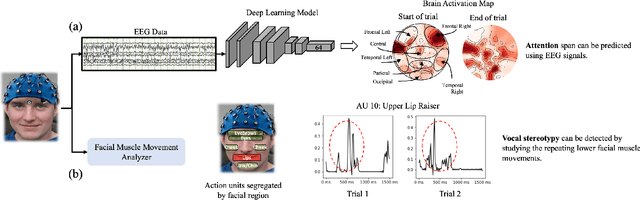
Stuttering Speech Disfluency Prediction using Explainable Attribution Vectors of Facial Muscle Movements
Oct 02, 2020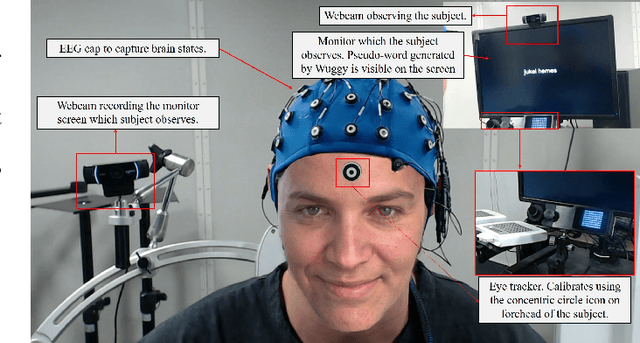


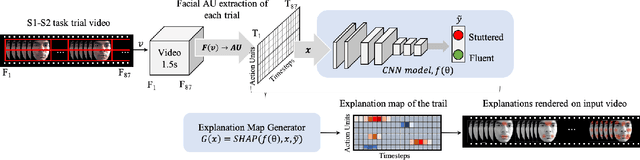
Speech disorders such as stuttering disrupt the normal fluency of speech by involuntary repetitions, prolongations and blocking of sounds and syllables. In addition to these disruptions to speech fluency, most adults who stutter (AWS) also experience numerous observable secondary behaviors before, during, and after a stuttering moment, often involving the facial muscles. Recent studies have explored automatic detection of stuttering using Artificial Intelligence (AI) based algorithm from respiratory rate, audio, etc. during speech utterance. However, most methods require controlled environments and/or invasive wearable sensors, and are unable explain why a decision (fluent vs stuttered) was made. We hypothesize that pre-speech facial activity in AWS, which can be captured non-invasively, contains enough information to accurately classify the upcoming utterance as either fluent or stuttered. Towards this end, this paper proposes a novel explainable AI (XAI) assisted convolutional neural network (CNN) classifier to predict near future stuttering by learning temporal facial muscle movement patterns of AWS and explains the important facial muscles and actions involved. Statistical analyses reveal significantly high prevalence of cheek muscles (p<0.005) and lip muscles (p<0.005) to predict stuttering and shows a behavior conducive of arousal and anticipation to speak. The temporal study of these upper and lower facial muscles may facilitate early detection of stuttering, promote automated assessment of stuttering and have application in behavioral therapies by providing automatic non-invasive feedback in realtime.
Opportunities and Challenges in Explainable Artificial Intelligence (XAI): A Survey
Jun 23, 2020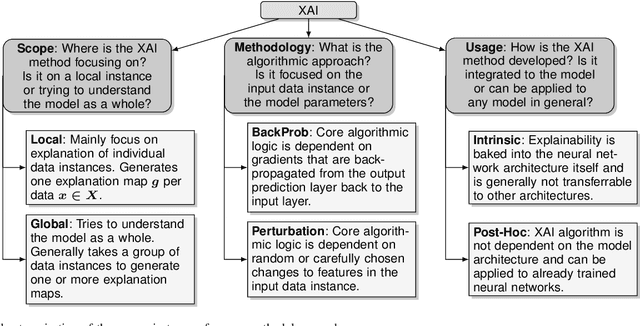
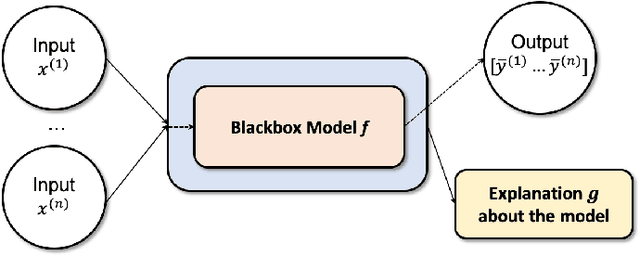

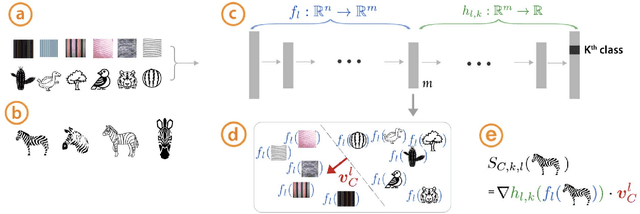
Nowadays, deep neural networks are widely used in mission critical systems such as healthcare, self-driving vehicles, and military which have direct impact on human lives. However, the black-box nature of deep neural networks challenges its use in mission critical applications, raising ethical and judicial concerns inducing lack of trust. Explainable Artificial Intelligence (XAI) is a field of Artificial Intelligence (AI) that promotes a set of tools, techniques, and algorithms that can generate high-quality interpretable, intuitive, human-understandable explanations of AI decisions. In addition to providing a holistic view of the current XAI landscape in deep learning, this paper provides mathematical summaries of seminal work. We start by proposing a taxonomy and categorizing the XAI techniques based on their scope of explanations, methodology behind the algorithms, and explanation level or usage which helps build trustworthy, interpretable, and self-explanatory deep learning models. We then describe the main principles used in XAI research and present the historical timeline for landmark studies in XAI from 2007 to 2020. After explaining each category of algorithms and approaches in detail, we then evaluate the explanation maps generated by eight XAI algorithms on image data, discuss the limitations of this approach, and provide potential future directions to improve XAI evaluation.
Encoderless Gimbal Calibration of Dynamic Multi-Camera Clusters
Jul 24, 2018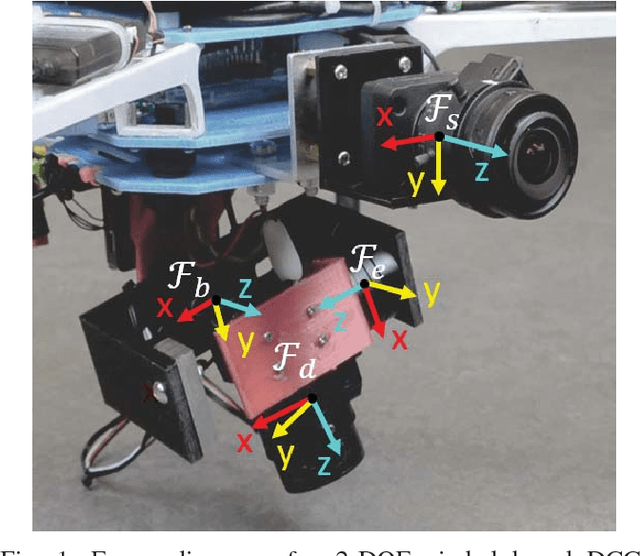

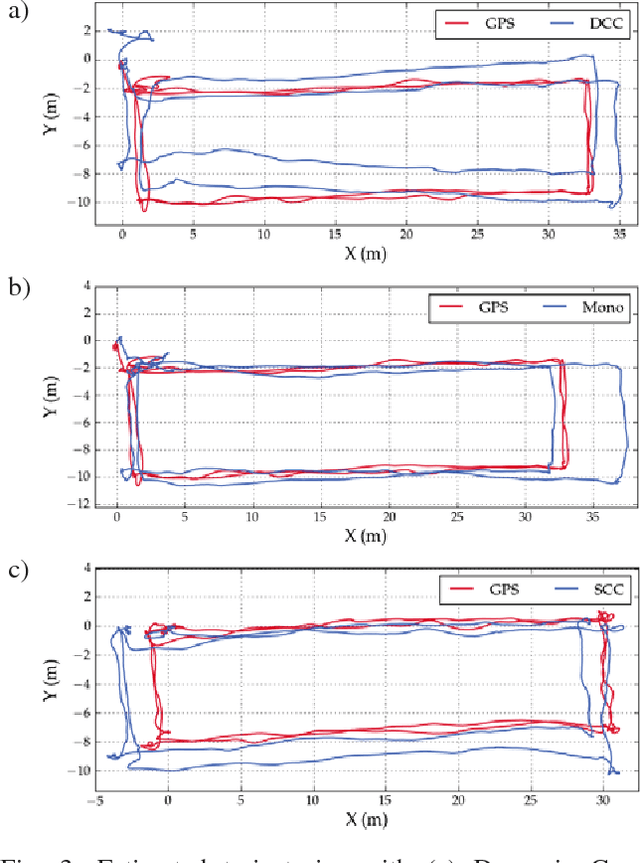

Dynamic Camera Clusters (DCCs) are multi-camera systems where one or more cameras are mounted on actuated mechanisms such as a gimbal. Existing methods for DCC calibration rely on joint angle measurements to resolve the time-varying transformation between the dynamic and static camera. This information is usually provided by motor encoders, however, joint angle measurements are not always readily available on off-the-shelf mechanisms. In this paper, we present an encoderless approach for DCC calibration which simultaneously estimates the kinematic parameters of the transformation chain as well as the unknown joint angles. We also demonstrate the integration of an encoderless gimbal mechanism with a state-of-the art VIO algorithm, and show the extensions required in order to perform simultaneous online estimation of the joint angles and vehicle localization state. The proposed calibration approach is validated both in simulation and on a physical DCC composed of a 2-DOF gimbal mounted on a UAV. Finally, we show the experimental results of the calibrated mechanism integrated into the OKVIS VIO package, and demonstrate successful online joint angle estimation while maintaining localization accuracy that is comparable to a standard static multi-camera configuration.