 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Clustering of Robust Semantic Representations for Adversarial Image Purification
Apr 07, 2021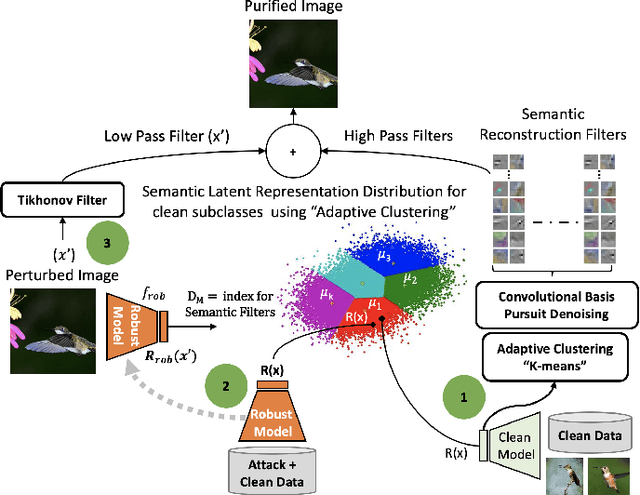
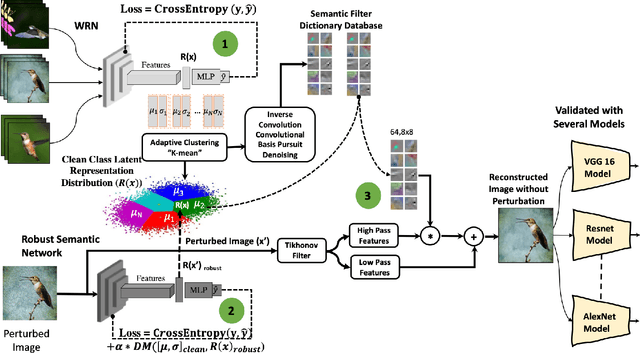


Deep Learning models are highly susceptible to adversarial manipulations that can lead to catastrophic consequences. One of the most effective methods to defend against such disturbances is adversarial training but at the cost of generalization of unseen attacks and transferability across models. In this paper, we propose a robust defense against adversarial attacks, which is model agnostic and generalizable to unseen adversaries. Initially, with a baseline model, we extract the latent representations for each class and adaptively cluster the latent representations that share a semantic similarity. We obtain the distributions for the clustered latent representations and from their originating images, we learn semantic reconstruction dictionaries (SRD). We adversarially train a new model constraining the latent space representation to minimize the distance between the adversarial latent representation and the true cluster distribution. To purify the image, we decompose the input into low and high-frequency components. The high-frequency component is reconstructed based on the most adequate SRD from the clean dataset. In order to evaluate the most adequate SRD, we rely on the distance between robust latent representations and semantic cluster distributions. The output is a purified image with no perturbation. Image purification on CIFAR-10 and ImageNet-10 using our proposed method improved the accuracy by more than 10% compared to state-of-the-art results.
Opportunities and Challenges in Deep Learning Adversarial Robustness: A Survey
Jul 03, 2020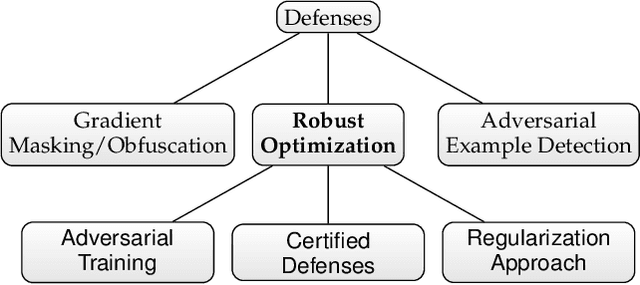
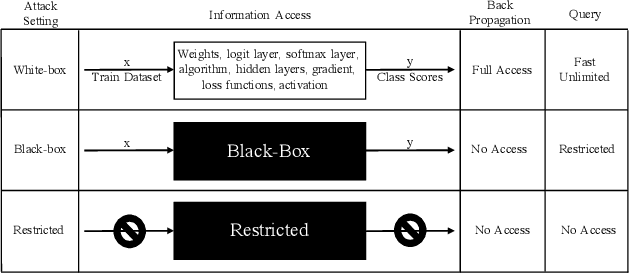
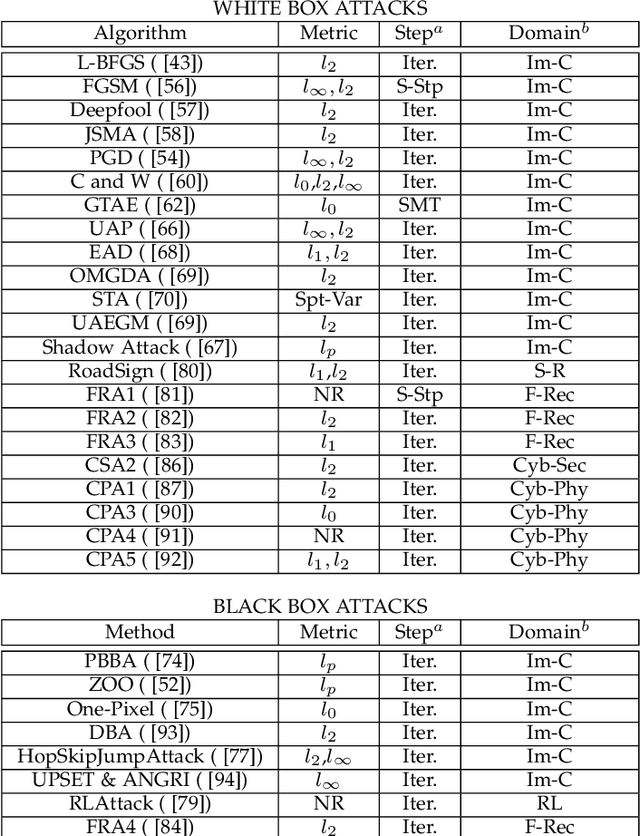
As we seek to deploy machine learning models beyond virtual and controlled domains, it is critical to analyze not only the accuracy or the fact that it works most of the time, but if such a model is truly robust and reliable. This paper studies strategies to implement adversary robustly trained algorithms towards guaranteeing safety in machine learning algorithms. We provide a taxonomy to classify adversarial attacks and defenses, formulate the Robust Optimization problem in a min-max setting and divide it into 3 subcategories, namely: Adversarial (re)Training, Regularization Approach, and Certified Defenses. We survey the most recent and important results in adversarial example generation, defense mechanisms with adversarial (re)Training as their main defense against perturbations. We also survey mothods that add regularization terms that change the behavior of the gradient, making it harder for attackers to achieve their objective. Alternatively, we've surveyed methods which formally derive certificates of robustness by exactly solving the optimization problem or by approximations using upper or lower bounds. In addition, we discuss the challenges faced by most of the recent algorithms presenting future research perspectives.