 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentic Adversarial Rewriting Exposes Architectural Vulnerabilities in Black-Box NLP Pipelines
Apr 26, 2026Multi-component natural language processing (NLP) pipelines are increasingly deployed for high-stakes decisions, yet no existing adversarial method can test their robustness under realistic conditions: binary-only feedback, no gradient access, and strict query budgets. We formalize this strict black-box threat model and propose a two-agent evasion framework operating in a semantic perturbation space. An Attacker Agent generates meaning-preserving rewrites while a Prompt Optimization Agent refines the attack strategy using only binary decision feedback within a 10-query budget. Evaluated against four evidence-based misinformation detection pipelines, the framework achieves evasion rates of 19.95 to 40.34% on modern large language model (LLM) based systems, compared to at most 3.90% for token-level perturbation baselines that rely on surrogate models because they cannot operate under our threat model. A legacy system relying on static lexical retrieval exhibits near-total vulnerability 97.02%, establishing a lower bound that exposes how architectural choices govern the attack surface. Evasion effectiveness is associated with three architectural properties: evidence retrieval mechanism, retrieval-inference coupling, and baseline classification accuracy. The iterative prompt optimization yields the largest marginal gains against the most robust targets, confirming that adaptive strategy discovery is essential when evasion is non-trivial. Analysis of successful rewrites reveals four exploitation patterns, each targeting failures at distinct pipeline stages. A pattern-informed defense reduces the evasion rate by up to 65.18%.
Reflective Agreement: Combining Self-Mixture of Agents with a Sequence Tagger for Robust Event Extraction
Aug 26, 2025Event Extraction (EE) involves automatically identifying and extracting structured information about events from unstructured text, including triggers, event types, and arguments. Traditional discriminative models demonstrate high precision but often exhibit limited recall, particularly for nuanced or infrequent events. Conversely, generative approaches leveraging Large Language Models (LLMs) provide higher semantic flexibility and recall but suffer from hallucinations and inconsistent predictions. To address these challenges, we propose Agreement-based Reflective Inference System (ARIS), a hybrid approach combining a Self Mixture of Agents with a discriminative sequence tagger. ARIS explicitly leverages structured model consensus, confidence-based filtering, and an LLM reflective inference module to reliably resolve ambiguities and enhance overall event prediction quality. We further investigate decomposed instruction fine-tuning for enhanced LLM event extraction understanding. Experiments demonstrate our approach outperforms existing state-of-the-art event extraction methods across three benchmark datasets.
A Comprehensive Evaluation of the Sensitivity of Density-Ratio Estimation Based Fairness Measurement in Regression
Aug 20, 2025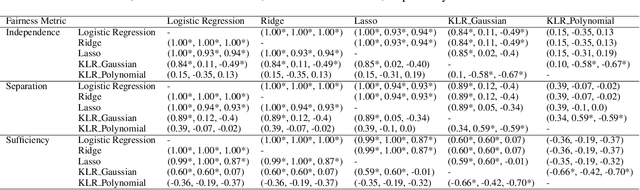
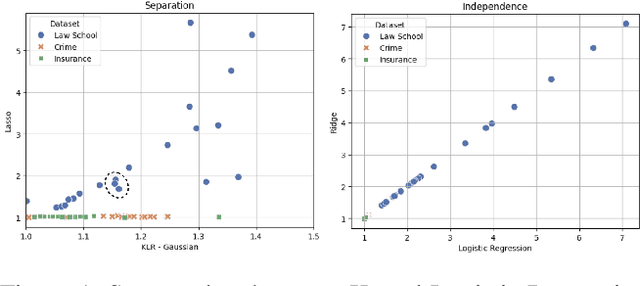
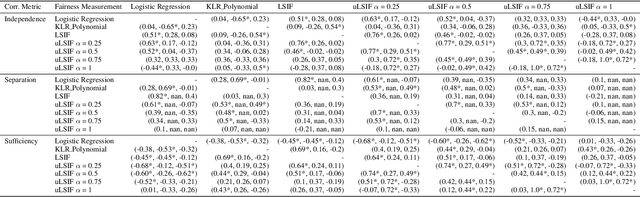
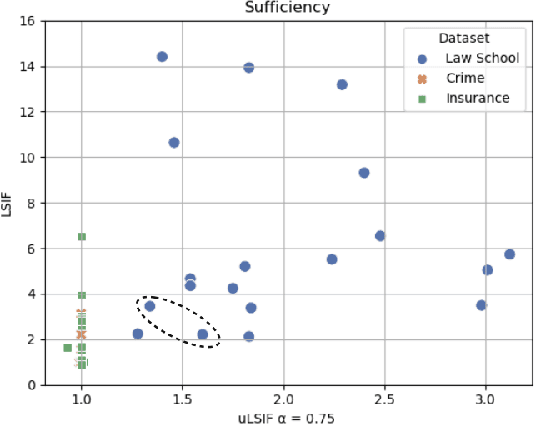
The prevalence of algorithmic bias in Machine Learning (ML)-driven approaches has inspired growing research on measuring and mitigating bias in the ML domain. Accordingly, prior research studied how to measure fairness in regression which is a complex problem. In particular, recent research proposed to formulate it as a density-ratio estimation problem and relied on a Logistic Regression-driven probabilistic classifier-based approach to solve it. However, there are several other methods to estimate a density ratio, and to the best of our knowledge, prior work did not study the sensitivity of such fairness measurement methods to the choice of underlying density ratio estimation algorithm. To fill this gap, this paper develops a set of fairness measurement methods with various density-ratio estimation cores and thoroughly investigates how different cores would affect the achieved level of fairness. Our experimental results show that the choice of density-ratio estimation core could significantly affect the outcome of fairness measurement method, and even, generate inconsistent results with respect to the relative fairness of various algorithms. These observations suggest major issues with density-ratio estimation based fairness measurement in regression and a need for further research to enhance their reliability.
CAMOUFLAGE: Exploiting Misinformation Detection Systems Through LLM-driven Adversarial Claim Transformation
May 03, 2025Automated evidence-based misinformation detection systems, which evaluate the veracity of short claims against evidence, lack comprehensive analysis of their adversarial vulnerabilities. Existing black-box text-based adversarial attacks are ill-suited for evidence-based misinformation detection systems, as these attacks primarily focus on token-level substitutions involving gradient or logit-based optimization strategies, which are incapable of fooling the multi-component nature of these detection systems. These systems incorporate both retrieval and claim-evidence comparison modules, which requires attacks to break the retrieval of evidence and/or the comparison module so that it draws incorrect inferences. We present CAMOUFLAGE, an iterative, LLM-driven approach that employs a two-agent system, a Prompt Optimization Agent and an Attacker Agent, to create adversarial claim rewritings that manipulate evidence retrieval and mislead claim-evidence comparison, effectively bypassing the system without altering the meaning of the claim. The Attacker Agent produces semantically equivalent rewrites that attempt to mislead detectors, while the Prompt Optimization Agent analyzes failed attack attempts and refines the prompt of the Attacker to guide subsequent rewrites. This enables larger structural and stylistic transformations of the text rather than token-level substitutions, adapting the magnitude of changes based on previous outcomes. Unlike existing approaches, CAMOUFLAGE optimizes its attack solely based on binary model decisions to guide its rewriting process, eliminating the need for classifier logits or extensive querying. We evaluate CAMOUFLAGE on four systems, including two recent academic systems and two real-world APIs, with an average attack success rate of 46.92\% while preserving textual coherence and semantic equivalence to the original claims.
Machine Learning Fairness in House Price Prediction: A Case Study of America's Expanding Metropolises
May 02, 2025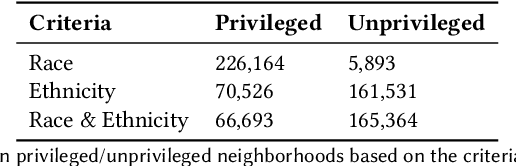

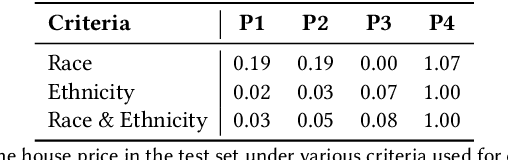
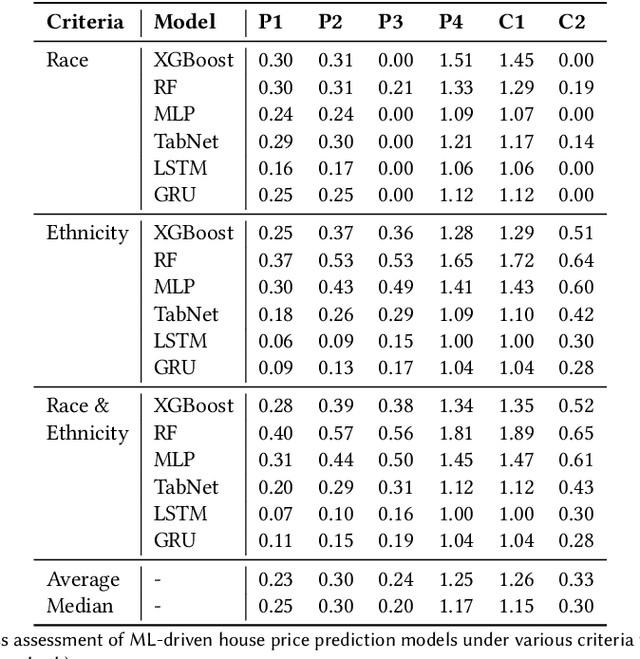
As a basic human need, housing plays a key role in enhancing health, well-being, and educational outcome in society, and the housing market is a major factor for promoting quality of life and ensuring social equity. To improve the housing conditions, there has been extensive research on building Machine Learning (ML)-driven house price prediction solutions to accurately forecast the future conditions, and help inform actions and policies in the field. In spite of their success in developing high-accuracy models, there is a gap in our understanding of the extent to which various ML-driven house price prediction approaches show ethnic and/or racial bias, which in turn is essential for the responsible use of ML, and ensuring that the ML-driven solutions do not exacerbate inequity. To fill this gap, this paper develops several ML models from a combination of structural and neighborhood-level attributes, and conducts comprehensive assessments on the fairness of ML models under various definitions of privileged groups. As a result, it finds that the ML-driven house price prediction models show various levels of bias towards protected attributes (i.e., race and ethnicity in this study). Then, it investigates the performance of different bias mitigation solutions, and the experimental results show their various levels of effectiveness on different ML-driven methods. However, in general, the in-processing bias mitigation approach tends to be more effective than the pre-processing one in this problem domain. Our code is available at https://github.com/wahab1412/housing_fairness.
FLAVARS: A Multimodal Foundational Language and Vision Alignment Model for Remote Sensing
Jan 14, 2025



Remote sensing imagery is dense with objects and contextual visual information. There is a recent trend to combine paired satellite images and text captions for pretraining performant encoders for downstream tasks. However, while contrastive image-text methods like CLIP enable vision-language alignment and zero-shot classification ability, vision-only downstream performance tends to degrade compared to image-only pretraining, such as MAE. In this paper, we propose FLAVARS, a pretraining method that combines the best of both contrastive learning and masked modeling, along with geospatial alignment via contrastive location encoding. We find that FLAVARS significantly outperforms a baseline of SkyCLIP for vision-only tasks such as KNN classification and semantic segmentation, +6\% mIOU on SpaceNet1, while retaining the ability to perform zero-shot classification, unlike MAE pretrained methods.
Enhancing Reverse Engineering: Investigating and Benchmarking Large Language Models for Vulnerability Analysis in Decompiled Binaries
Nov 07, 2024Security experts reverse engineer (decompile) binary code to identify critical security vulnerabilities. The limited access to source code in vital systems - such as firmware, drivers, and proprietary software used in Critical Infrastructures (CI) - makes this analysis even more crucial on the binary level. Even with available source code, a semantic gap persists after compilation between the source and the binary code executed by the processor. This gap may hinder the detection of vulnerabilities in source code. That being said, current research on Large Language Models (LLMs) overlooks the significance of decompiled binaries in this area by focusing solely on source code. In this work, we are the first to empirically uncover the substantial semantic limitations of state-of-the-art LLMs when it comes to analyzing vulnerabilities in decompiled binaries, largely due to the absence of relevant datasets. To bridge the gap, we introduce DeBinVul, a novel decompiled binary code vulnerability dataset. Our dataset is multi-architecture and multi-optimization, focusing on C/C++ due to their wide usage in CI and association with numerous vulnerabilities. Specifically, we curate 150,872 samples of vulnerable and non-vulnerable decompiled binary code for the task of (i) identifying; (ii) classifying; (iii) describing vulnerabilities; and (iv) recovering function names in the domain of decompiled binaries. Subsequently, we fine-tune state-of-the-art LLMs using DeBinVul and report on a performance increase of 19%, 24%, and 21% in the capabilities of CodeLlama, Llama3, and CodeGen2 respectively, in detecting binary code vulnerabilities. Additionally, using DeBinVul, we report a high performance of 80-90% on the vulnerability classification task. Furthermore, we report improved performance in function name recovery and vulnerability description tasks.
Jailbreaking Large Language Models with Symbolic Mathematics
Sep 17, 2024



Recent advancements in AI safety have led to increased efforts in training and red-teaming large language models (LLMs) to mitigate unsafe content generation. However, these safety mechanisms may not be comprehensive, leaving potential vulnerabilities unexplored. This paper introduces MathPrompt, a novel jailbreaking technique that exploits LLMs' advanced capabilities in symbolic mathematics to bypass their safety mechanisms. By encoding harmful natural language prompts into mathematical problems, we demonstrate a critical vulnerability in current AI safety measures. Our experiments across 13 state-of-the-art LLMs reveal an average attack success rate of 73.6\%, highlighting the inability of existing safety training mechanisms to generalize to mathematically encoded inputs. Analysis of embedding vectors shows a substantial semantic shift between original and encoded prompts, helping explain the attack's success. This work emphasizes the importance of a holistic approach to AI safety, calling for expanded red-teaming efforts to develop robust safeguards across all potential input types and their associated risks.
Improving LLM Reasoning with Multi-Agent Tree-of-Thought Validator Agent
Sep 17, 2024



Multi-agent strategies have emerged as a promising approach to enhance the reasoning abilities of Large Language Models (LLMs) by assigning specialized roles in the problem-solving process. Concurrently, Tree of Thoughts (ToT) methods have shown potential in improving reasoning for complex question-answering tasks by exploring diverse reasoning paths. A critical limitation in multi-agent reasoning is the 'Reasoner' agent's shallow exploration of reasoning paths. While ToT strategies could help mitigate this problem, they may generate flawed reasoning branches, which could harm the trustworthiness of the final answer. To leverage the strengths of both multi-agent reasoning and ToT strategies, we introduce a novel approach combining ToT-based Reasoner agents with a Thought Validator agent. Multiple Reasoner agents operate in parallel, employing ToT to explore diverse reasoning paths. The Thought Validator then scrutinizes these paths, considering a Reasoner's conclusion only if its reasoning is valid. This method enables a more robust voting strategy by discarding faulty reasoning paths, enhancing the system's ability to tackle tasks requiring systematic and trustworthy reasoning. Our method demonstrates superior performance compared to existing techniques when evaluated on the GSM8K dataset, outperforming the standard ToT strategy by an average 5.6\% across four LLMs.
AutoSafeCoder: A Multi-Agent Framework for Securing LLM Code Generation through Static Analysis and Fuzz Testing
Sep 16, 2024Recent advancements in automatic code generation using large language models (LLMs) have brought us closer to fully automated secure software development. However, existing approaches often rely on a single agent for code generation, which struggles to produce secure, vulnerability-free code. Traditional program synthesis with LLMs has primarily focused on functional correctness, often neglecting critical dynamic security implications that happen during runtime. To address these challenges, we propose AutoSafeCoder, a multi-agent framework that leverages LLM-driven agents for code generation, vulnerability analysis, and security enhancement through continuous collaboration. The framework consists of three agents: a Coding Agent responsible for code generation, a Static Analyzer Agent identifying vulnerabilities, and a Fuzzing Agent performing dynamic testing using a mutation-based fuzzing approach to detect runtime errors. Our contribution focuses on ensuring the safety of multi-agent code generation by integrating dynamic and static testing in an iterative process during code generation by LLM that improves security. Experiments using the SecurityEval dataset demonstrate a 13% reduction in code vulnerabilities compared to baseline LLMs, with no compromise in functionality.