 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Evaluation of the Sensitivity of Density-Ratio Estimation Based Fairness Measurement in Regression
Aug 20, 2025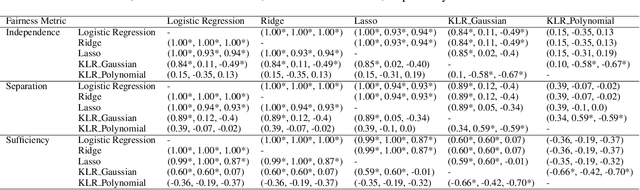
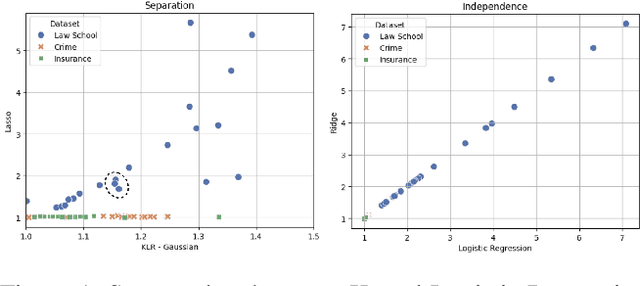
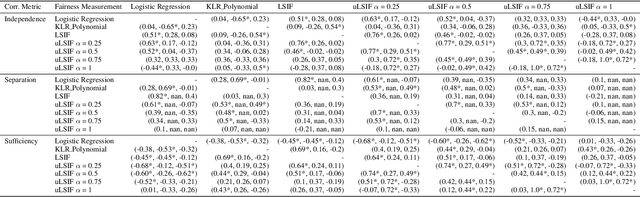
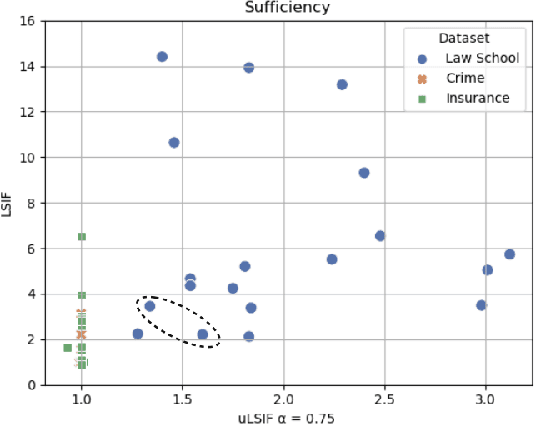
The prevalence of algorithmic bias in Machine Learning (ML)-driven approaches has inspired growing research on measuring and mitigating bias in the ML domain. Accordingly, prior research studied how to measure fairness in regression which is a complex problem. In particular, recent research proposed to formulate it as a density-ratio estimation problem and relied on a Logistic Regression-driven probabilistic classifier-based approach to solve it. However, there are several other methods to estimate a density ratio, and to the best of our knowledge, prior work did not study the sensitivity of such fairness measurement methods to the choice of underlying density ratio estimation algorithm. To fill this gap, this paper develops a set of fairness measurement methods with various density-ratio estimation cores and thoroughly investigates how different cores would affect the achieved level of fairness. Our experimental results show that the choice of density-ratio estimation core could significantly affect the outcome of fairness measurement method, and even, generate inconsistent results with respect to the relative fairness of various algorithms. These observations suggest major issues with density-ratio estimation based fairness measurement in regression and a need for further research to enhance their reliability.
A New Lens on Homelessness: Daily Tent Monitoring with 311 Calls and Street Images
Aug 08, 2025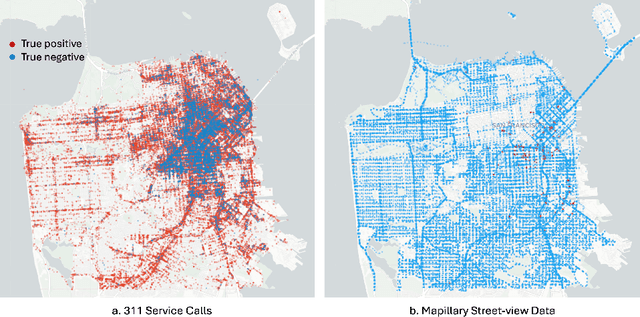
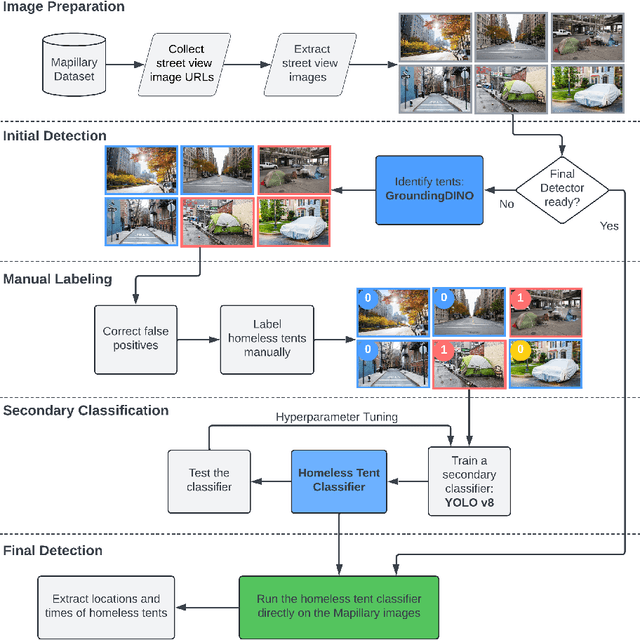
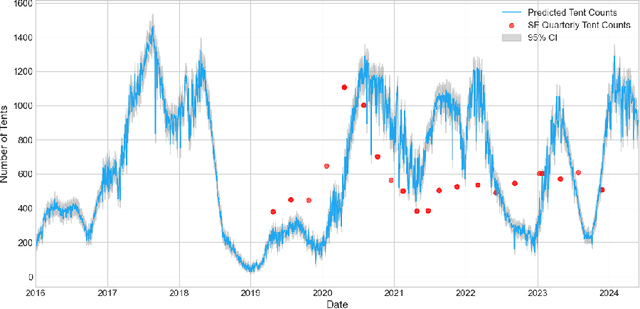
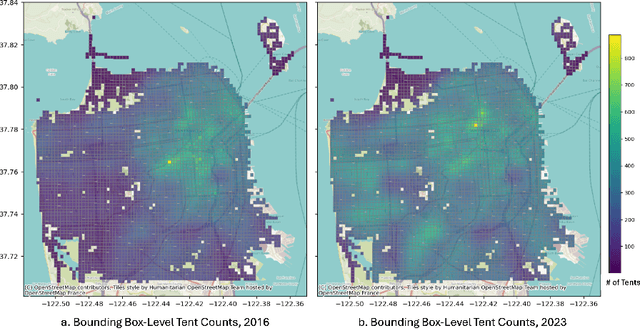
Homelessness in the United States has surged to levels unseen since the Great Depression. However, existing methods for monitoring it, such as point-in-time (PIT) counts, have limitations in terms of frequency, consistency, and spatial detail. This study proposes a new approach using publicly available, crowdsourced data, specifically 311 Service Calls and street-level imagery, to track and forecast homeless tent trends in San Francisco. Our predictive model captures fine-grained daily and neighborhood-level variations, uncovering patterns that traditional counts often overlook, such as rapid fluctuations during the COVID-19 pandemic and spatial shifts in tent locations over time. By providing more timely, localized, and cost-effective information, this approach serves as a valuable tool for guiding policy responses and evaluating interventions aimed at reducing unsheltered homelessness.
Machine Learning Fairness in House Price Prediction: A Case Study of America's Expanding Metropolises
May 02, 2025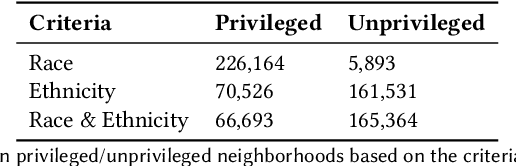

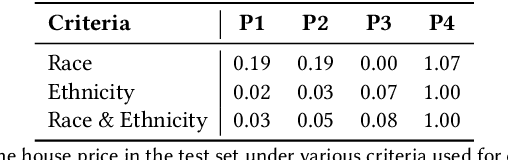
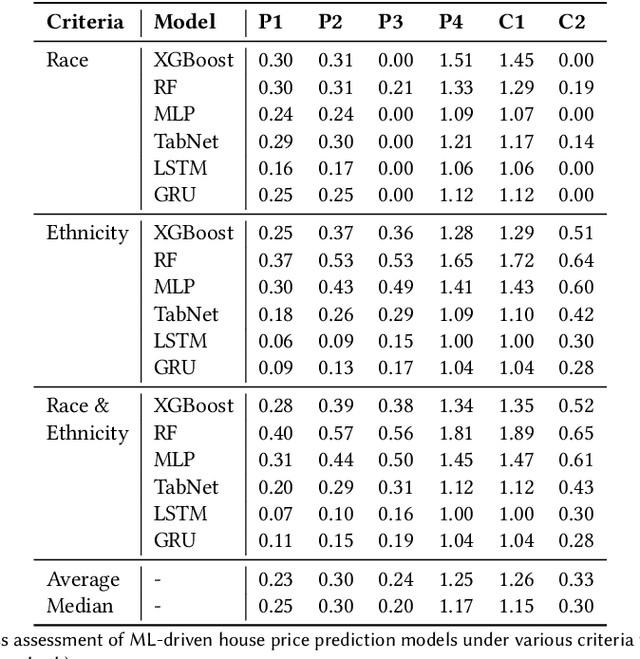
As a basic human need, housing plays a key role in enhancing health, well-being, and educational outcome in society, and the housing market is a major factor for promoting quality of life and ensuring social equity. To improve the housing conditions, there has been extensive research on building Machine Learning (ML)-driven house price prediction solutions to accurately forecast the future conditions, and help inform actions and policies in the field. In spite of their success in developing high-accuracy models, there is a gap in our understanding of the extent to which various ML-driven house price prediction approaches show ethnic and/or racial bias, which in turn is essential for the responsible use of ML, and ensuring that the ML-driven solutions do not exacerbate inequity. To fill this gap, this paper develops several ML models from a combination of structural and neighborhood-level attributes, and conducts comprehensive assessments on the fairness of ML models under various definitions of privileged groups. As a result, it finds that the ML-driven house price prediction models show various levels of bias towards protected attributes (i.e., race and ethnicity in this study). Then, it investigates the performance of different bias mitigation solutions, and the experimental results show their various levels of effectiveness on different ML-driven methods. However, in general, the in-processing bias mitigation approach tends to be more effective than the pre-processing one in this problem domain. Our code is available at https://github.com/wahab1412/housing_fairness.
Improving LLM Reasoning with Multi-Agent Tree-of-Thought Validator Agent
Sep 17, 2024



Multi-agent strategies have emerged as a promising approach to enhance the reasoning abilities of Large Language Models (LLMs) by assigning specialized roles in the problem-solving process. Concurrently, Tree of Thoughts (ToT) methods have shown potential in improving reasoning for complex question-answering tasks by exploring diverse reasoning paths. A critical limitation in multi-agent reasoning is the 'Reasoner' agent's shallow exploration of reasoning paths. While ToT strategies could help mitigate this problem, they may generate flawed reasoning branches, which could harm the trustworthiness of the final answer. To leverage the strengths of both multi-agent reasoning and ToT strategies, we introduce a novel approach combining ToT-based Reasoner agents with a Thought Validator agent. Multiple Reasoner agents operate in parallel, employing ToT to explore diverse reasoning paths. The Thought Validator then scrutinizes these paths, considering a Reasoner's conclusion only if its reasoning is valid. This method enables a more robust voting strategy by discarding faulty reasoning paths, enhancing the system's ability to tackle tasks requiring systematic and trustworthy reasoning. Our method demonstrates superior performance compared to existing techniques when evaluated on the GSM8K dataset, outperforming the standard ToT strategy by an average 5.6\% across four LLMs.
On the Consistency of Fairness Measurement Methods for Regression Tasks
Jun 19, 2024With growing applications of Machine Learning (ML) techniques in the real world, it is highly important to ensure that these models work in an equitable manner. One main step in ensuring fairness is to effectively measure fairness, and to this end, various metrics have been proposed in the past literature. While the computation of those metrics are straightforward in the classification set-up, it is computationally intractable in the regression domain. To address the challenge of computational intractability, past literature proposed various methods to approximate such metrics. However, they did not verify the extent to which the output of such approximation algorithms are consistent with each other. To fill this gap, this paper comprehensively studies the consistency of the output of various fairness measurement methods through conducting an extensive set of experiments on various regression tasks. As a result, it finds that while some fairness measurement approaches show strong consistency across various regression tasks, certain methods show a relatively poor consistency in certain regression tasks. This, in turn, calls for a more principled approach for measuring fairness in the regression domain.