 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoAI Agency Primitives
Apr 02, 2026We present ongoing research on agency primitives for GeoAI assistants -- core capabilities that connect Foundation models to the artifact-centric, human-in-the-loop workflows where GIS practitioners actually work. Despite advances in satellite image captioning, visual question answering, and promptable segmentation, these capabilities have not translated into productivity gains for practitioners who spend most of their time producing vector layers, raster maps, and cartographic products. The gap is not model capability alone but the absence of an agency layer that supports iterative collaboration. We propose a vocabulary of $9$ primitives for such a layer -- including navigation, perception, geo-referenced memory, and dual modeling -- along with a benchmark that measures human productivity. Our goal is a vocabulary that makes agentic assistance in GIS implementable, testable, and comparable.
TEMPO: Global Temporal Building Density and Height Estimation from Satellite Imagery
Nov 15, 2025We present TEMPO, a global, temporally resolved dataset of building density and height derived from high-resolution satellite imagery using deep learning models. We pair building footprint and height data from existing datasets with quarterly PlanetScope basemap satellite images to train a multi-task deep learning model that predicts building density and building height at a 37.6-meter per pixel resolution. We apply this model to global PlanetScope basemaps from Q1 2018 through Q2 2025 to create global, temporal maps of building density and height. We validate these maps by comparing against existing building footprint datasets. Our estimates achieve an F1 score between 85% and 88% on different hand-labeled subsets, and are temporally stable, with a 0.96 five-year trend-consistency score. TEMPO captures quarterly changes in built settlements at a fraction of the computational cost of comparable approaches, unlocking large-scale monitoring of development patterns and climate impacts essential for global resilience and adaptation efforts.
GeoVision Labeler: Zero-Shot Geospatial Classification with Vision and Language Models
May 30, 2025Classifying geospatial imagery remains a major bottleneck for applications such as disaster response and land-use monitoring-particularly in regions where annotated data is scarce or unavailable. Existing tools (e.g., RS-CLIP) that claim zero-shot classification capabilities for satellite imagery nonetheless rely on task-specific pretraining and adaptation to reach competitive performance. We introduce GeoVision Labeler (GVL), a strictly zero-shot classification framework: a vision Large Language Model (vLLM) generates rich, human-readable image descriptions, which are then mapped to user-defined classes by a conventional Large Language Model (LLM). This modular, and interpretable pipeline enables flexible image classification for a large range of use cases. We evaluated GVL across three benchmarks-SpaceNet v7, UC Merced, and RESISC45. It achieves up to 93.2% zero-shot accuracy on the binary Buildings vs. No Buildings task on SpaceNet v7. For complex multi-class classification tasks (UC Merced, RESISC45), we implemented a recursive LLM-driven clustering to form meta-classes at successive depths, followed by hierarchical classification-first resolving coarse groups, then finer distinctions-to deliver competitive zero-shot performance. GVL is open-sourced at https://github.com/microsoft/geo-vision-labeler to catalyze adoption in real-world geospatial workflows.
Core-Set Selection for Data-efficient Land Cover Segmentation
May 02, 2025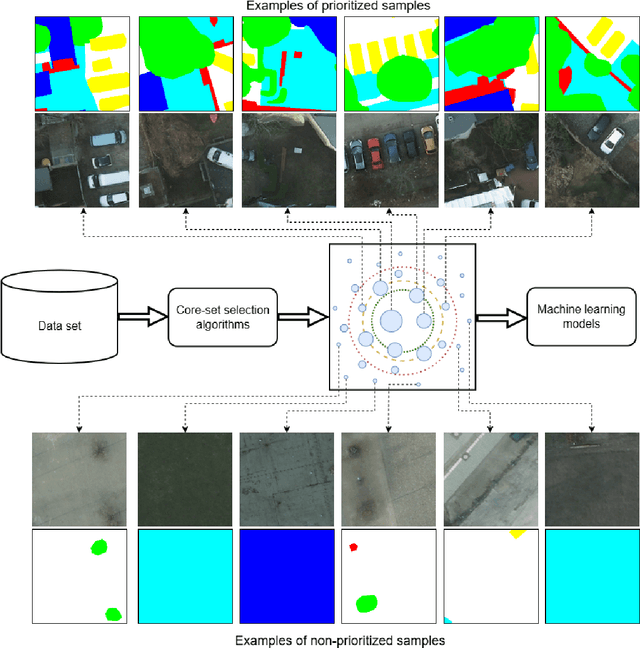


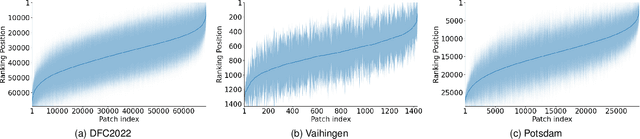
The increasing accessibility of remotely sensed data and the potential of such data to inform large-scale decision-making has driven the development of deep learning models for many Earth Observation tasks. Traditionally, such models must be trained on large datasets. However, the common assumption that broadly larger datasets lead to better outcomes tends to overlook the complexities of the data distribution, the potential for introducing biases and noise, and the computational resources required for processing and storing vast datasets. Therefore, effective solutions should consider both the quantity and quality of data. In this paper, we propose six novel core-set selection methods for selecting important subsets of samples from remote sensing image segmentation datasets that rely on imagery only, labels only, and a combination of each. We benchmark these approaches against a random-selection baseline on three commonly used land cover classification datasets: DFC2022, Vaihingen, and Potsdam. In each of the datasets, we demonstrate that training on a subset of samples outperforms the random baseline, and some approaches outperform training on all available data. This result shows the importance and potential of data-centric learning for the remote sensing domain. The code is available at https://github.com/keillernogueira/data-centric-rs-classification/.
Global Renewables Watch: A Temporal Dataset of Solar and Wind Energy Derived from Satellite Imagery
Mar 19, 2025We present a comprehensive global temporal dataset of commercial solar photovoltaic (PV) farms and onshore wind turbines, derived from high-resolution satellite imagery analyzed quarterly from the fourth quarter of 2017 to the second quarter of 2024. We create this dataset by training deep learning-based segmentation models to identify these renewable energy installations from satellite imagery, then deploy them on over 13 trillion pixels covering the world. For each detected feature, we estimate the construction date and the preceding land use type. This dataset offers crucial insights into progress toward sustainable development goals and serves as a valuable resource for policymakers, researchers, and stakeholders aiming to assess and promote effective strategies for renewable energy deployment. Our final spatial dataset includes 375,197 individual wind turbines and 86,410 solar PV installations. We aggregate our predictions to the country level -- estimating total power capacity based on construction date, solar PV area, and number of windmills -- and find an $r^2$ value of $0.96$ and $0.93$ for solar PV and onshore wind respectively compared to IRENA's most recent 2023 country-level capacity estimates.
FLAVARS: A Multimodal Foundational Language and Vision Alignment Model for Remote Sensing
Jan 14, 2025



Remote sensing imagery is dense with objects and contextual visual information. There is a recent trend to combine paired satellite images and text captions for pretraining performant encoders for downstream tasks. However, while contrastive image-text methods like CLIP enable vision-language alignment and zero-shot classification ability, vision-only downstream performance tends to degrade compared to image-only pretraining, such as MAE. In this paper, we propose FLAVARS, a pretraining method that combines the best of both contrastive learning and masked modeling, along with geospatial alignment via contrastive location encoding. We find that FLAVARS significantly outperforms a baseline of SkyCLIP for vision-only tasks such as KNN classification and semantic segmentation, +6\% mIOU on SpaceNet1, while retaining the ability to perform zero-shot classification, unlike MAE pretrained methods.
Distribution Shifts at Scale: Out-of-distribution Detection in Earth Observation
Dec 18, 2024Training robust deep learning models is critical in Earth Observation, where globally deployed models often face distribution shifts that degrade performance, especially in low-data regions. Out-of-distribution (OOD) detection addresses this challenge by identifying inputs that differ from in-distribution (ID) data. However, existing methods either assume access to OOD data or compromise primary task performance, making them unsuitable for real-world deployment. We propose TARDIS, a post-hoc OOD detection method for scalable geospatial deployments. The core novelty lies in generating surrogate labels by integrating information from ID data and unknown distributions, enabling OOD detection at scale. Our method takes a pre-trained model, ID data, and WILD samples, disentangling the latter into surrogate ID and surrogate OOD labels based on internal activations, and fits a binary classifier as an OOD detector. We validate TARDIS on EuroSAT and xBD datasets, across 17 experimental setups covering covariate and semantic shifts, showing that it performs close to the theoretical upper bound in assigning surrogate ID and OOD samples in 13 cases. To demonstrate scalability, we deploy TARDIS on the Fields of the World dataset, offering actionable insights into pre-trained model behavior for large-scale deployments. The code is publicly available at https://github.com/microsoft/geospatial-ood-detection.
Sims: An Interactive Tool for Geospatial Matching and Clustering
Dec 13, 2024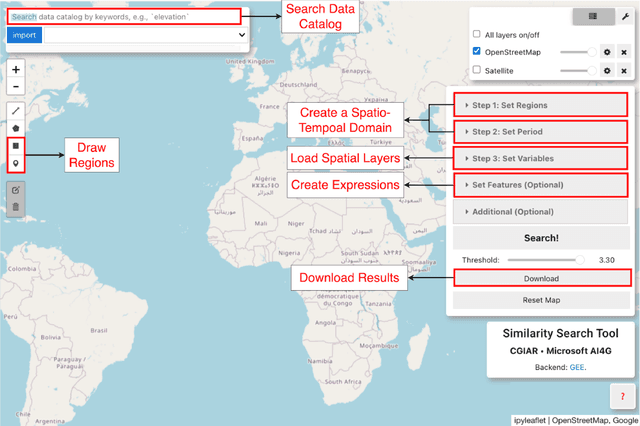
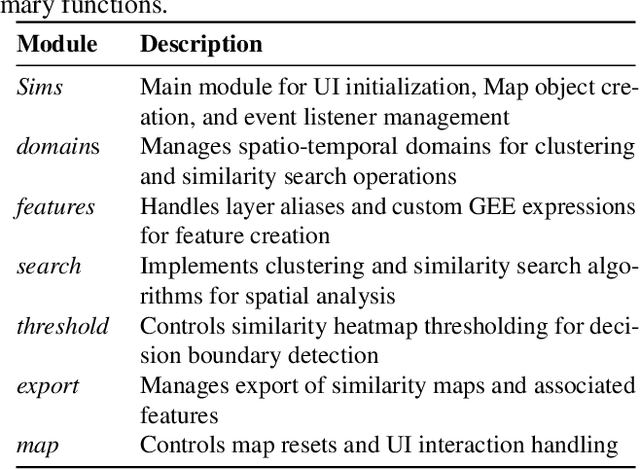
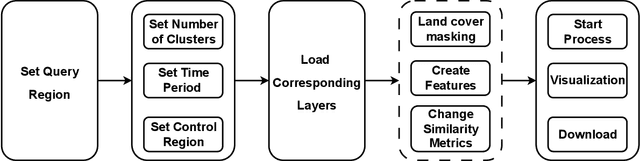
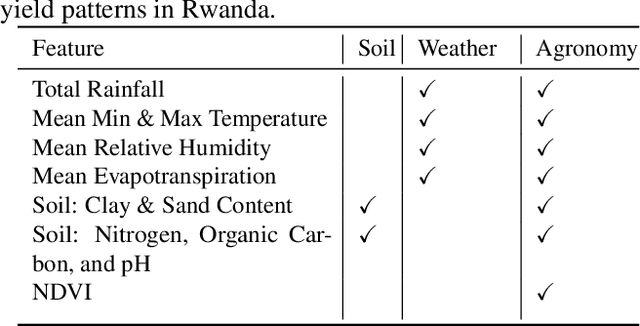
Acquiring, processing, and visualizing geospatial data requires significant computing resources, especially for large spatio-temporal domains. This challenge hinders the rapid discovery of predictive features, which is essential for advancing geospatial modeling. To address this, we developed Similarity Search (Sims), a no-code web tool that allows users to visualize, compare, cluster, and perform similarity search over defined regions of interest using Google Earth Engine as a backend. Sims is designed to complement existing modeling tools by focusing on feature exploration rather than model creation. We demonstrate the utility of Sims through a case study analyzing simulated maize yield data in Rwanda, where we evaluate how different combinations of soil, weather, and agronomic features affect the clustering of yield response zones. Sims is open source and available at https://github.com/microsoft/Sims
PGRID: Power Grid Reconstruction in Informal Developments Using High-Resolution Aerial Imagery
Dec 10, 2024



As of 2023, a record 117 million people have been displaced worldwide, more than double the number from a decade ago [22]. Of these, 32 million are refugees under the UNHCR mandate, with 8.7 million residing in refugee camps. A critical issue faced by these populations is the lack of access to electricity, with 80% of the 8.7 million refugees and displaced persons in camps globally relying on traditional biomass for cooking and lacking reliable power for essential tasks such as cooking and charging phones. Often, the burden of collecting firewood falls on women and children, who frequently travel up to 20 kilometers into dangerous areas, increasing their vulnerability.[7] Electricity access could significantly alleviate these challenges, but a major obstacle is the lack of accurate power grid infrastructure maps, particularly in resource-constrained environments like refugee camps, needed for energy access planning. Existing power grid maps are often outdated, incomplete, or dependent on costly, complex technologies, limiting their practicality. To address this issue, PGRID is a novel application-based approach, which utilizes high-resolution aerial imagery to detect electrical poles and segment electrical lines, creating precise power grid maps. PGRID was tested in the Turkana region of Kenya, specifically the Kakuma and Kalobeyei Camps, covering 84 km2 and housing over 200,000 residents. Our findings show that PGRID delivers high-fidelity power grid maps especially in unplanned settlements, with F1-scores of 0.71 and 0.82 for pole detection and line segmentation, respectively. This study highlights a practical application for leveraging open data and limited labels to improve power grid mapping in unplanned settlements, where the growing number of displaced persons urgently need sustainable energy infrastructure solutions.
Local vs. Global: Local Land-Use and Land-Cover Models Deliver Higher Quality Maps
Dec 01, 2024



Approximately 20% of Africa's population suffered from undernourishment, and 868 million people experienced moderate to severe food insecurity in 2022. Land-use and land-cover maps provide crucial insights for addressing food insecurity, e.g., by mapping croplands. The development of global land-cover maps has been facilitated by the increasing availability of earth observation data and advancements in geospatial machine learning. However, these global maps exhibit lower accuracy and inconsistencies in Africa, partly due to the lack of representative training data. To address this issue, we propose a data-centric framework with a teacher-student model setup, which uses diverse data sources of satellite images and label examples to produce local land-cover maps. Our method trains a high-resolution teacher model on images with a resolution of 0.331 m/pixel and a low-resolution student model on publicly available images with a resolution of 10 m/pixel. The student model also utilizes the teacher model's output as its weak label examples through knowledge distillation. We evaluated our framework using Murang'a County, Kenya, as a use case and achieved significant improvements, i.e., 0.14 in the F1 score and 0.21 in Intersection-over-Union, compared to the best global map. Our evaluation also revealed inconsistencies in existing global maps, with a maximum agreement rate of 0.30 among themselves. Insights obtained from our cross-collaborative work can provide valuable guidance to local and national policymakers in making informed decisions to improve resource utilization and food security.