 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSatellite-Based Detection of Looted Archaeological Sites Using Machine Learning
Feb 23, 2026Looting at archaeological sites poses a severe risk to cultural heritage, yet monitoring thousands of remote locations remains operationally difficult. We present a scalable and satellite-based pipeline to detect looted archaeological sites, using PlanetScope monthly mosaics (4.7m/pixel) and a curated dataset of 1,943 archaeological sites in Afghanistan (898 looted, 1,045 preserved) with multi-year imagery (2016--2023) and site-footprint masks. We compare (i) end-to-end CNN classifiers trained on raw RGB patches and (ii) traditional machine learning (ML) trained on handcrafted spectral/texture features and embeddings from recent remote-sensing foundation models. Results indicate that ImageNet-pretrained CNNs combined with spatial masking reach an F1 score of 0.926, clearly surpassing the strongest traditional ML setup, which attains an F1 score of 0.710 using SatCLIP-V+RF+Mean, i.e., location and vision embeddings fed into a Random Forest with mean-based temporal aggregation. Ablation studies demonstrate that ImageNet pretraining (even in the presence of domain shift) and spatial masking enhance performance. In contrast, geospatial foundation model embeddings perform competitively with handcrafted features, suggesting that looting signatures are extremely localized. The repository is available at https://github.com/microsoft/looted_site_detection.
Global Renewables Watch: A Temporal Dataset of Solar and Wind Energy Derived from Satellite Imagery
Mar 19, 2025We present a comprehensive global temporal dataset of commercial solar photovoltaic (PV) farms and onshore wind turbines, derived from high-resolution satellite imagery analyzed quarterly from the fourth quarter of 2017 to the second quarter of 2024. We create this dataset by training deep learning-based segmentation models to identify these renewable energy installations from satellite imagery, then deploy them on over 13 trillion pixels covering the world. For each detected feature, we estimate the construction date and the preceding land use type. This dataset offers crucial insights into progress toward sustainable development goals and serves as a valuable resource for policymakers, researchers, and stakeholders aiming to assess and promote effective strategies for renewable energy deployment. Our final spatial dataset includes 375,197 individual wind turbines and 86,410 solar PV installations. We aggregate our predictions to the country level -- estimating total power capacity based on construction date, solar PV area, and number of windmills -- and find an $r^2$ value of $0.96$ and $0.93$ for solar PV and onshore wind respectively compared to IRENA's most recent 2023 country-level capacity estimates.
Analyzing Film Adaptation through Narrative Alignment
Nov 07, 2023Novels are often adapted into feature films, but the differences between the two media usually require dropping sections of the source text from the movie script. Here we study this screen adaptation process by constructing narrative alignments using the Smith-Waterman local alignment algorithm coupled with SBERT embedding distance to quantify text similarity between scenes and book units. We use these alignments to perform an automated analysis of 40 adaptations, revealing insights into the screenwriting process concerning (i) faithfulness of adaptation, (ii) importance of dialog, (iii) preservation of narrative order, and (iv) gender representation issues reflective of the Bechdel test.
STONYBOOK: A System and Resource for Large-Scale Analysis of Novels
Nov 06, 2023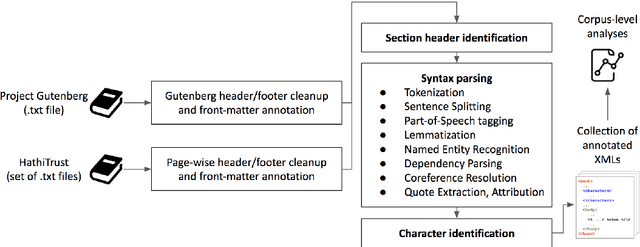

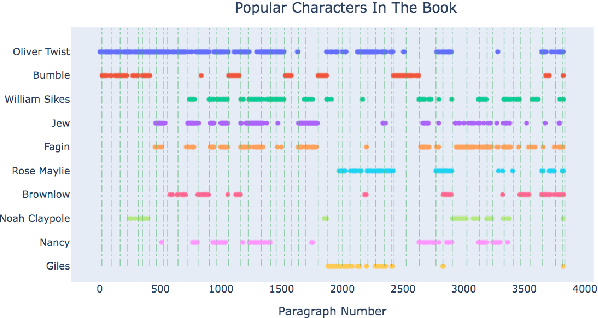
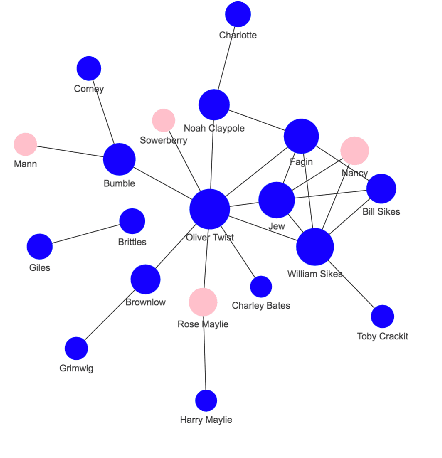
Books have historically been the primary mechanism through which narratives are transmitted. We have developed a collection of resources for the large-scale analysis of novels, including: (1) an open source end-to-end NLP analysis pipeline for the annotation of novels into a standard XML format, (2) a collection of 49,207 distinct cleaned and annotated novels, and (3) a database with an associated web interface for the large-scale aggregate analysis of these literary works. We describe the major functionalities provided in the annotation system along with their utilities. We present samples of analysis artifacts from our website, such as visualizations of character occurrences and interactions, similar books, representative vocabulary, part of speech statistics, and readability metrics. We also describe the use of the annotated format in qualitative and quantitative analysis across large corpora of novels.
Cleaning Dirty Books: Post-OCR Processing for Previously Scanned Texts
Oct 22, 2021
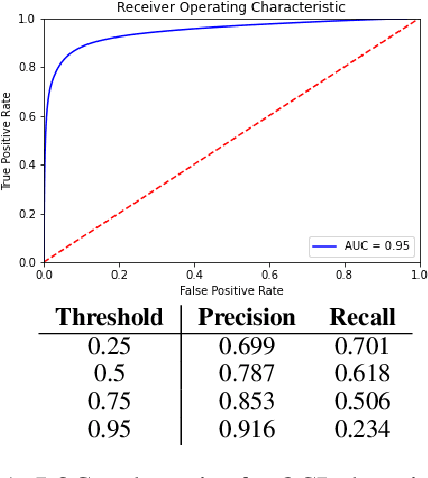
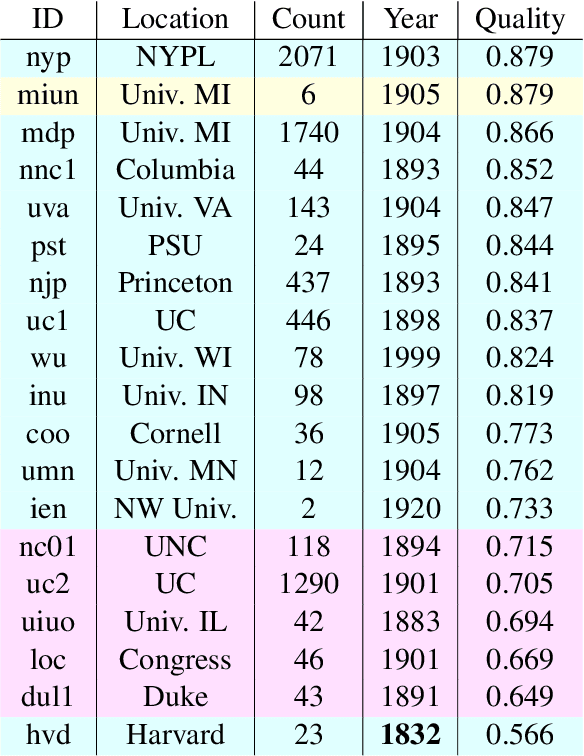
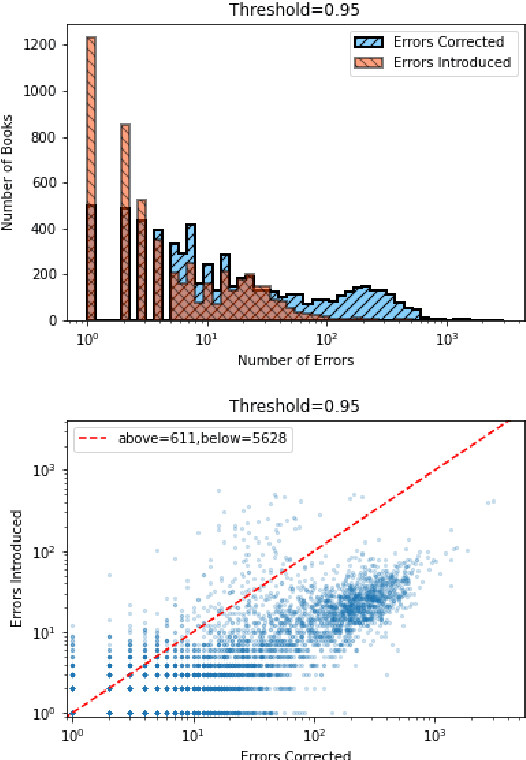
Substantial amounts of work are required to clean large collections of digitized books for NLP analysis, both because of the presence of errors in the scanned text and the presence of duplicate volumes in the corpora. In this paper, we consider the issue of deduplication in the presence of optical character recognition (OCR) errors. We present methods to handle these errors, evaluated on a collection of 19,347 texts from the Project Gutenberg dataset and 96,635 texts from the HathiTrust Library. We demonstrate that improvements in language models now enable the detection and correction of OCR errors without consideration of the scanning image itself. The inconsistencies found by aligning pairs of scans of the same underlying work provides training data to build models for detecting and correcting errors. We identify the canonical version for each of 17,136 repeatedly-scanned books from 58,808 scans. Finally, we investigate methods to detect and correct errors in single-copy texts. We show that on average, our method corrects over six times as many errors as it introduces. We also provide interesting analysis on the relation between scanning quality and other factors such as location and publication year.
Chapter Captor: Text Segmentation in Novels
Nov 09, 2020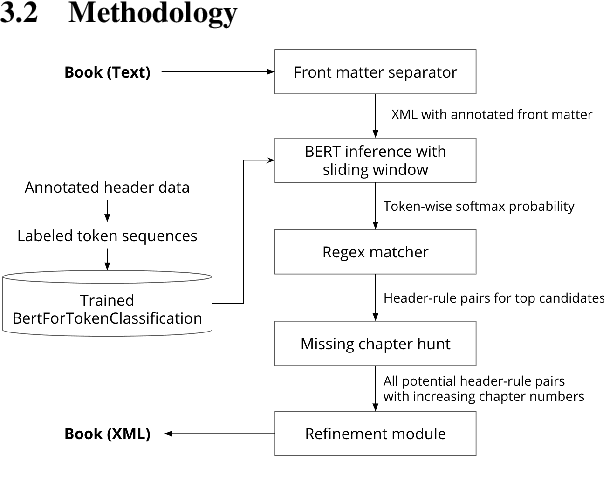
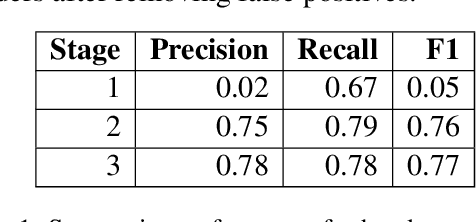
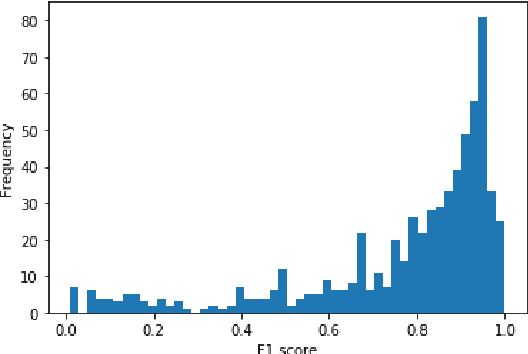
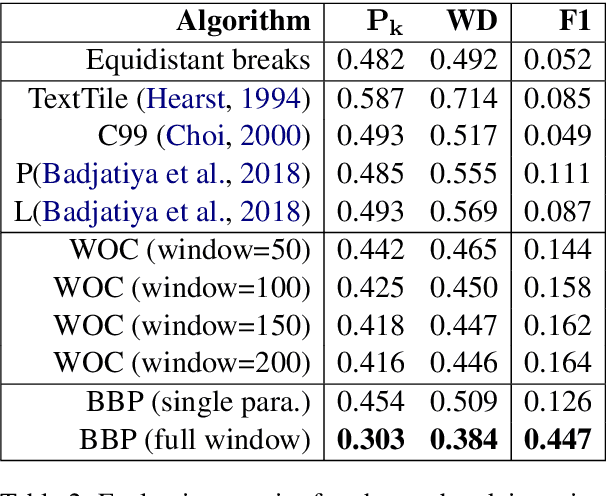
Books are typically segmented into chapters and sections, representing coherent subnarratives and topics. We investigate the task of predicting chapter boundaries, as a proxy for the general task of segmenting long texts. We build a Project Gutenberg chapter segmentation data set of 9,126 English novels, using a hybrid approach combining neural inference and rule matching to recognize chapter title headers in books, achieving an F1-score of 0.77 on this task. Using this annotated data as ground truth after removing structural cues, we present cut-based and neural methods for chapter segmentation, achieving an F1-score of 0.453 on the challenging task of exact break prediction over book-length documents. Finally, we reveal interesting historical trends in the chapter structure of novels.
What time is it? Temporal Analysis of Novels
Nov 09, 2020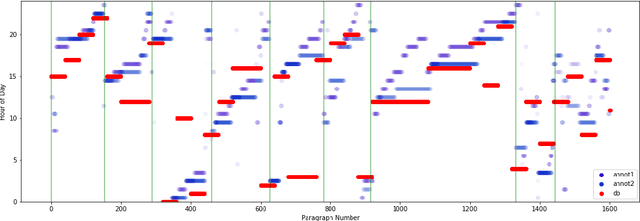

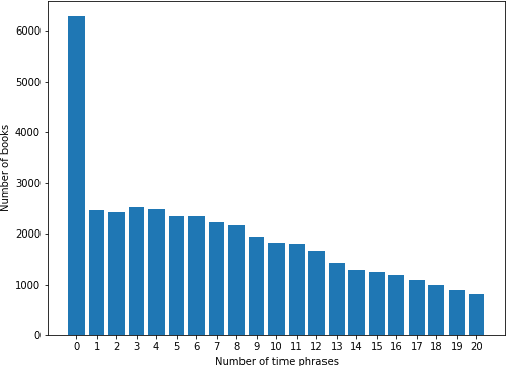

Recognizing the flow of time in a story is a crucial aspect of understanding it. Prior work related to time has primarily focused on identifying temporal expressions or relative sequencing of events, but here we propose computationally annotating each line of a book with wall clock times, even in the absence of explicit time-descriptive phrases. To do so, we construct a data set of hourly time phrases from 52,183 fictional books. We then construct a time-of-day classification model that achieves an average error of 2.27 hours. Furthermore, we show that by analyzing a book in whole using dynamic programming of breakpoints, we can roughly partition a book into segments that each correspond to a particular time-of-day. This approach improves upon baselines by over two hours. Finally, we apply our model to a corpus of literature categorized by different periods in history, to show interesting trends of hourly activity throughout the past. Among several observations we find that the fraction of events taking place past 10 P.M jumps past 1880 - coincident with the advent of the electric light bulb and city lights.