 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTONYBOOK: A System and Resource for Large-Scale Analysis of Novels
Nov 06, 2023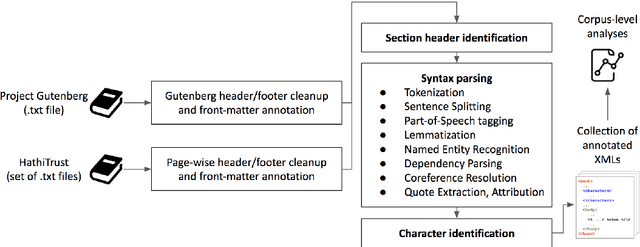

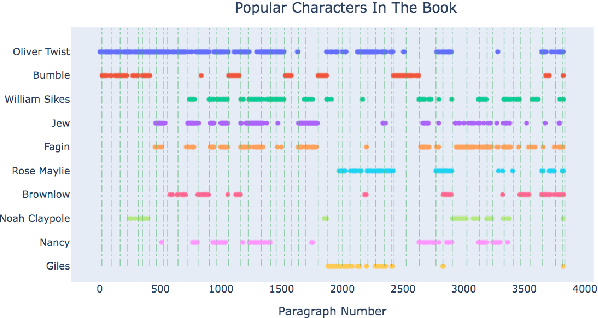
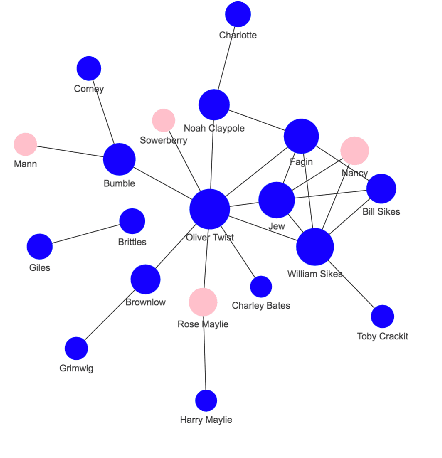
Books have historically been the primary mechanism through which narratives are transmitted. We have developed a collection of resources for the large-scale analysis of novels, including: (1) an open source end-to-end NLP analysis pipeline for the annotation of novels into a standard XML format, (2) a collection of 49,207 distinct cleaned and annotated novels, and (3) a database with an associated web interface for the large-scale aggregate analysis of these literary works. We describe the major functionalities provided in the annotation system along with their utilities. We present samples of analysis artifacts from our website, such as visualizations of character occurrences and interactions, similar books, representative vocabulary, part of speech statistics, and readability metrics. We also describe the use of the annotated format in qualitative and quantitative analysis across large corpora of novels.