 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing Film Adaptation through Narrative Alignment
Nov 07, 2023Novels are often adapted into feature films, but the differences between the two media usually require dropping sections of the source text from the movie script. Here we study this screen adaptation process by constructing narrative alignments using the Smith-Waterman local alignment algorithm coupled with SBERT embedding distance to quantify text similarity between scenes and book units. We use these alignments to perform an automated analysis of 40 adaptations, revealing insights into the screenwriting process concerning (i) faithfulness of adaptation, (ii) importance of dialog, (iii) preservation of narrative order, and (iv) gender representation issues reflective of the Bechdel test.
GNAT: A General Narrative Alignment Tool
Nov 07, 2023Algorithmic sequence alignment identifies similar segments shared between pairs of documents, and is fundamental to many NLP tasks. But it is difficult to recognize similarities between distant versions of narratives such as translations and retellings, particularly for summaries and abridgements which are much shorter than the original novels. We develop a general approach to narrative alignment coupling the Smith-Waterman algorithm from bioinformatics with modern text similarity metrics. We show that the background of alignment scores fits a Gumbel distribution, enabling us to define rigorous p-values on the significance of any alignment. We apply and evaluate our general narrative alignment tool (GNAT) on four distinct problem domains differing greatly in both the relative and absolute length of documents, namely summary-to-book alignment, translated book alignment, short story alignment, and plagiarism detection -- demonstrating the power and performance of our methods.
STONYBOOK: A System and Resource for Large-Scale Analysis of Novels
Nov 06, 2023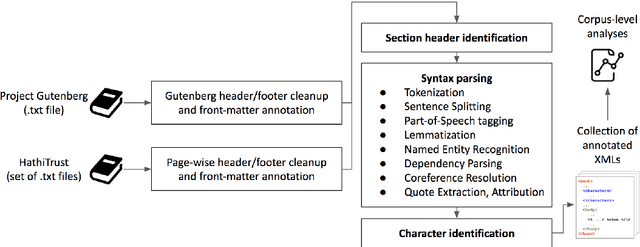

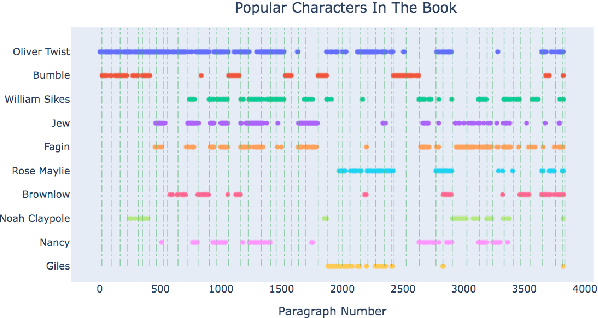
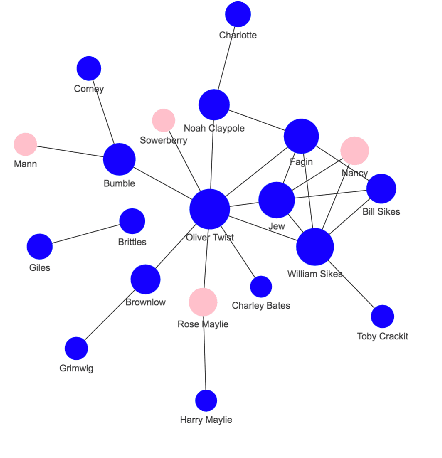
Books have historically been the primary mechanism through which narratives are transmitted. We have developed a collection of resources for the large-scale analysis of novels, including: (1) an open source end-to-end NLP analysis pipeline for the annotation of novels into a standard XML format, (2) a collection of 49,207 distinct cleaned and annotated novels, and (3) a database with an associated web interface for the large-scale aggregate analysis of these literary works. We describe the major functionalities provided in the annotation system along with their utilities. We present samples of analysis artifacts from our website, such as visualizations of character occurrences and interactions, similar books, representative vocabulary, part of speech statistics, and readability metrics. We also describe the use of the annotated format in qualitative and quantitative analysis across large corpora of novels.