 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReducing Tokenization Premiums for Low-Resource Languages
Jan 19, 2026Relative to English, low-resource languages suffer from substantial tokenization premiums in modern LMs, meaning that it generally requires several times as many tokens to encode a sentence in a low-resource language than to encode the analogous sentence in English. This tokenization premium results in increased API and energy costs and reduced effective context windows for these languages. In this paper we analyze the tokenizers of ten popular LMs to better understand their designs and per-language tokenization premiums. We also propose a mechanism to reduce tokenization premiums in pre-trained models, by post-hoc additions to the token vocabulary that coalesce multi-token characters into single tokens. We apply this methodology to 12 low-resource languages, demonstrating that the original and compressed inputs often have similar last hidden states when run through the Llama 3.2 1B model.
Gatsby Without the 'E': Crafting Lipograms with LLMs
May 26, 2025Lipograms are a unique form of constrained writing where all occurrences of a particular letter are excluded from the text, typified by the novel Gadsby, which daringly avoids all usage of the letter 'e'. In this study, we explore the power of modern large language models (LLMs) by transforming the novel F. Scott Fitzgerald's The Great Gatsby into a fully 'e'-less text. We experimented with a range of techniques, from baseline methods like synonym replacement to sophisticated generative models enhanced with beam search and named entity analysis. We show that excluding up to 3.6% of the most common letters (up to the letter 'u') had minimal impact on the text's meaning, although translation fidelity rapidly and predictably decays with stronger lipogram constraints. Our work highlights the surprising flexibility of English under strict constraints, revealing just how adaptable and creative language can be.
Fast and Robust Contextual Node Representation Learning over Dynamic Graphs
Nov 11, 2024



Real-world graphs grow rapidly with edge and vertex insertions over time, motivating the problem of efficiently maintaining robust node representation over evolving graphs. Recent efficient GNNs are designed to decouple recursive message passing from the learning process, and favor Personalized PageRank (PPR) as the underlying feature propagation mechanism. However, most PPR-based GNNs are designed for static graphs, and efficient PPR maintenance remains as an open problem. Further, there is surprisingly little theoretical justification for the choice of PPR, despite its impressive empirical performance. In this paper, we are inspired by the recent PPR formulation as an explicit $\ell_1$-regularized optimization problem and propose a unified dynamic graph learning framework based on sparse node-wise attention. We also present a set of desired properties to justify the choice of PPR in STOA GNNs, and serves as the guideline for future node attention designs. Meanwhile, we take advantage of the PPR-equivalent optimization formulation and employ the proximal gradient method (ISTA) to improve the efficiency of PPR-based GNNs upto 6 times. Finally, we instantiate a simple-yet-effective model (\textsc{GoPPE}) with robust positional encodings by maximizing PPR previously used as attention. The model performs comparably to or better than the STOA baselines and greatly outperforms when the initial node attributes are noisy during graph evolution, demonstrating the effectiveness and robustness of \textsc{GoPPE}.
The Shape of Word Embeddings: Recognizing Language Phylogenies through Topological Data Analysis
Mar 30, 2024Word embeddings represent language vocabularies as clouds of $d$-dimensional points. We investigate how information is conveyed by the general shape of these clouds, outside of representing the semantic meaning of each token. Specifically, we use the notion of persistent homology from topological data analysis (TDA) to measure the distances between language pairs from the shape of their unlabeled embeddings. We use these distance matrices to construct language phylogenetic trees over 81 Indo-European languages. Careful evaluation shows that our reconstructed trees exhibit strong similarities to the reference tree.
Word Definitions from Large Language Models
Nov 10, 2023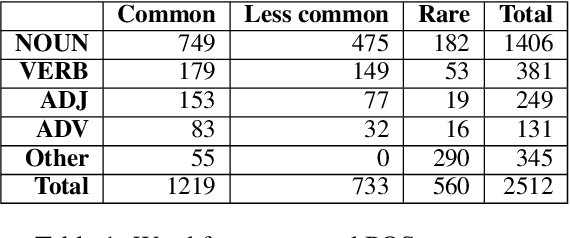
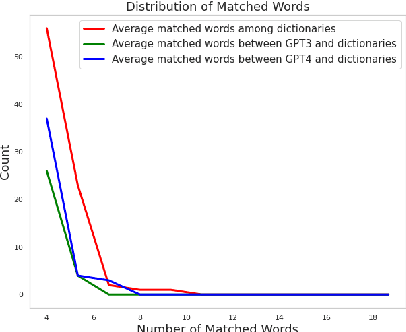


Dictionary definitions are historically the arbitrator of what words mean, but this primacy has come under threat by recent progress in NLP, including word embeddings and generative models like ChatGPT. We present an exploratory study of the degree of alignment between word definitions from classical dictionaries and these newer computational artifacts. Specifically, we compare definitions from three published dictionaries to those generated from variants of ChatGPT. We show that (i) definitions from different traditional dictionaries exhibit more surface form similarity than do model-generated definitions, (ii) that the ChatGPT definitions are highly accurate, comparable to traditional dictionaries, and (iii) ChatGPT-based embedding definitions retain their accuracy even on low frequency words, much better than GloVE and FastText word embeddings.
GNAT: A General Narrative Alignment Tool
Nov 07, 2023Algorithmic sequence alignment identifies similar segments shared between pairs of documents, and is fundamental to many NLP tasks. But it is difficult to recognize similarities between distant versions of narratives such as translations and retellings, particularly for summaries and abridgements which are much shorter than the original novels. We develop a general approach to narrative alignment coupling the Smith-Waterman algorithm from bioinformatics with modern text similarity metrics. We show that the background of alignment scores fits a Gumbel distribution, enabling us to define rigorous p-values on the significance of any alignment. We apply and evaluate our general narrative alignment tool (GNAT) on four distinct problem domains differing greatly in both the relative and absolute length of documents, namely summary-to-book alignment, translated book alignment, short story alignment, and plagiarism detection -- demonstrating the power and performance of our methods.
Analyzing Film Adaptation through Narrative Alignment
Nov 07, 2023Novels are often adapted into feature films, but the differences between the two media usually require dropping sections of the source text from the movie script. Here we study this screen adaptation process by constructing narrative alignments using the Smith-Waterman local alignment algorithm coupled with SBERT embedding distance to quantify text similarity between scenes and book units. We use these alignments to perform an automated analysis of 40 adaptations, revealing insights into the screenwriting process concerning (i) faithfulness of adaptation, (ii) importance of dialog, (iii) preservation of narrative order, and (iv) gender representation issues reflective of the Bechdel test.
STONYBOOK: A System and Resource for Large-Scale Analysis of Novels
Nov 06, 2023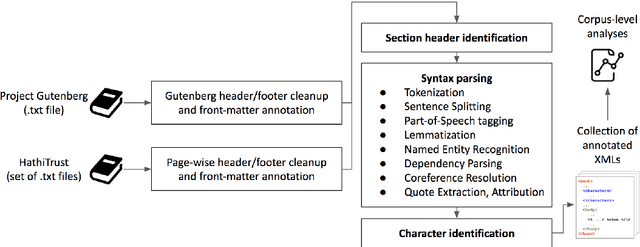

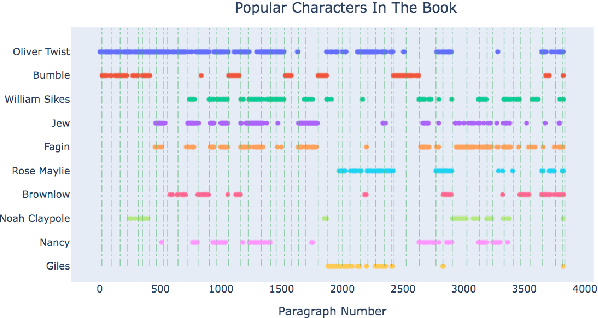
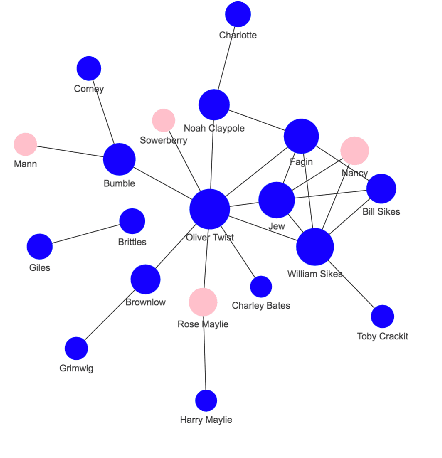
Books have historically been the primary mechanism through which narratives are transmitted. We have developed a collection of resources for the large-scale analysis of novels, including: (1) an open source end-to-end NLP analysis pipeline for the annotation of novels into a standard XML format, (2) a collection of 49,207 distinct cleaned and annotated novels, and (3) a database with an associated web interface for the large-scale aggregate analysis of these literary works. We describe the major functionalities provided in the annotation system along with their utilities. We present samples of analysis artifacts from our website, such as visualizations of character occurrences and interactions, similar books, representative vocabulary, part of speech statistics, and readability metrics. We also describe the use of the annotated format in qualitative and quantitative analysis across large corpora of novels.
Prosody Analysis of Audiobooks
Oct 10, 2023



Recent advances in text-to-speech have made it possible to generate natural-sounding audio from text. However, audiobook narrations involve dramatic vocalizations and intonations by the reader, with greater reliance on emotions, dialogues, and descriptions in the narrative. Using our dataset of 93 aligned book-audiobook pairs, we present improved models for prosody prediction properties (pitch, volume, and rate of speech) from narrative text using language modeling. Our predicted prosody attributes correlate much better with human audiobook readings than results from a state-of-the-art commercial TTS system: our predicted pitch shows a higher correlation with human reading for 22 out of the 24 books, while our predicted volume attribute proves more similar to human reading for 23 out of the 24 books. Finally, we present a human evaluation study to quantify the extent that people prefer prosody-enhanced audiobook readings over commercial text-to-speech systems.
Does it pay to optimize AUC?
Jun 02, 2023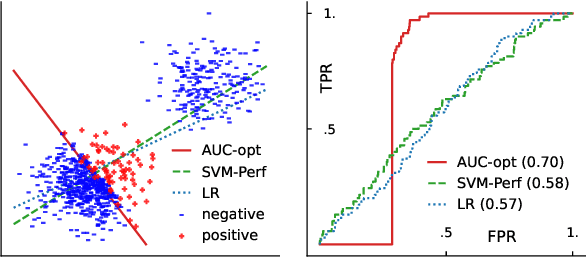
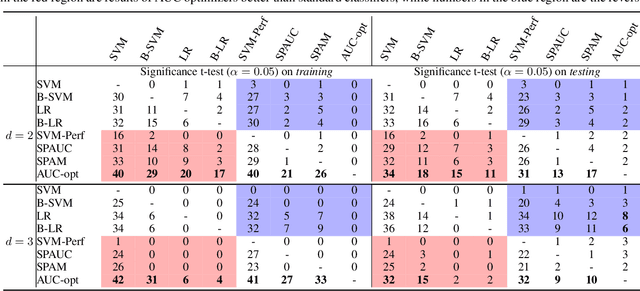
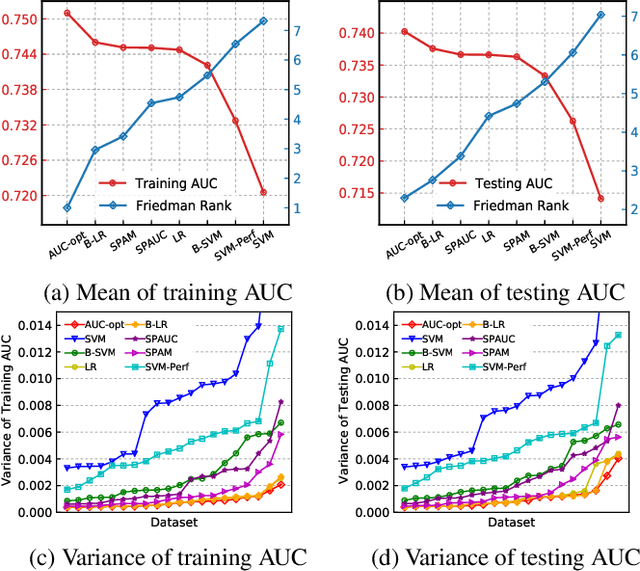
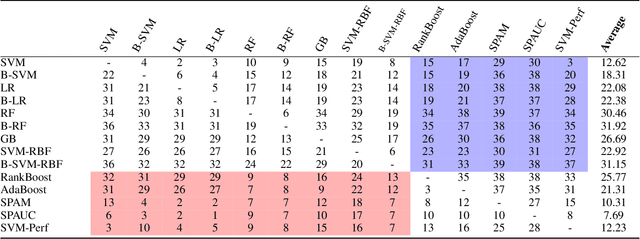
The Area Under the ROC Curve (AUC) is an important model metric for evaluating binary classifiers, and many algorithms have been proposed to optimize AUC approximately. It raises the question of whether the generally insignificant gains observed by previous studies are due to inherent limitations of the metric or the inadequate quality of optimization. To better understand the value of optimizing for AUC, we present an efficient algorithm, namely AUC-opt, to find the provably optimal AUC linear classifier in $\mathbb{R}^2$, which runs in $\mathcal{O}(n_+ n_- \log (n_+ n_-))$ where $n_+$ and $n_-$ are the number of positive and negative samples respectively. Furthermore, it can be naturally extended to $\mathbb{R}^d$ in $\mathcal{O}((n_+n_-)^{d-1}\log (n_+n_-))$ by calling AUC-opt in lower-dimensional spaces recursively. We prove the problem is NP-complete when $d$ is not fixed, reducing from the \textit{open hemisphere problem}. Experiments show that compared with other methods, AUC-opt achieves statistically significant improvements on between 17 to 40 in $\mathbb{R}^2$ and between 4 to 42 in $\mathbb{R}^3$ of 50 t-SNE training datasets. However, generally the gain proves insignificant on most testing datasets compared to the best standard classifiers. Similar observations are found for nonlinear AUC methods under real-world datasets.