 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic DLM+: Improving Diffusion Language Models through Bias-variance Trade-off in Transition Kernel Design
Jun 13, 2026Diffusion Language Models (DLMs) have demonstrated strong scaling capacity as alternatives to autoregressive language models. However, their performance is highly sensitive to the choice of transition kernels, and poorly designed kernels can lead to issues like training instability, slow convergence, and biased sampling. In this paper, we study this sensitivity through a principled analysis of generalization error and identify three critical factors: asymptotic bias (difficulty in approximating the posterior distribution), exposure bias (error propagation during sampling), and optimization variance induced by kernel dispersion. We further compare different transition kernels: masking diffusion yields sparse and easier posterior-approximation targets, while uniform diffusion provides stronger sampling-side repair but induces harder approximation. Motivated by this trade-off, we revisit a previously overlooked variant, semantic DLM (SemDLM), where the transition kernel corrupts tokens to neighborhoods that are semantically similar. Our theory suggests that SemDLM can serve as a plausible middle ground by reducing the posterior approximation difficulty of uniform diffusion while retaining repair ability. However, we find that SemDLM suffers from a semantic basin problem, where sampling repeatedly stays within a semantic region and produces low-diversity text. To address this, we propose SemDLM+, which adds a global transition and a semantic-frequency penalty during sampling. Experiments on LM1B and OpenWebText show that SemDLM+ improves training dynamics and achieves competitive language modeling and generation quality with satisfactory diversity.
Reinforcement Learning from Denoising Feedback
May 25, 2026Policy loss estimation remains a fundamental and long-standing challenge in reinforcement learning (RL) for diffusion language models (dLLMs). We introduce Reinforcement Learning from Denoising Feedback (RLDF), a novel training paradigm that leverages feedback obtained from rollout and training processes to facilitate accurate and efficient policy loss estimation. To balance the trade-off between computational efficiency and estimation effectiveness, RLDF optimizes the model toward the clipped clean state $\hat{x}_0$ from intermediate noisy states $x_t$, combined with weighted timestep sampling over $t$. Extensive experiments demonstrate that RLDF achieves consistent and substantial improvements in both performance and generalizability across two representative dLLM architectures, LLaDA and Dream, on multiple reasoning benchmarks. Our work lays a principled foundation for scalable reinforcement learning in diffusion language models. We build Drift, a training framework for dLLMs, available at https://github.com/ant-research/Drift.
On the Trainability of Masked Diffusion Language Models via Blockwise Locality
Apr 27, 2026Masked diffusion language models (MDMs) have recently emerged as a promising alternative to standard autoregressive large language models (AR-LLMs), yet their optimization can be substantially less stable. We study blockwise MDMs and compare them with AR-LLMs on three controlled tasks that stress different aspects of structured generation: in-context linear regression, graph path-finding, and Sudoku solving. We find that standard random-masking MDMs fail to reliably learn linear regression, exhibit high variance training dynamics on graph path-finding, while outperforming AR-LLMs on Sudoku. To mitigate these instabilities, we propose two locality aware blockwise models, namely Jigsaw and Scatter, that inject left-to-right inductive bias by enforcing autoregressive locality within blocks while preserving iterative refinement at the block level. Empirically, Jigsaw matches AR-LLM stability on linear regression and remains strong on Sudoku, while Scatter retains diffusion's planning advantage on path-finding. Our results indicate that standard random-masking MDMs, even with blockwise variants, may be a suboptimal instantiation of diffusion LMs for ordered generation, motivating models beyond random masking.
Logics-STEM: Empowering LLM Reasoning via Failure-Driven Post-Training and Document Knowledge Enhancement
Jan 08, 2026We present Logics-STEM, a state-of-the-art reasoning model fine-tuned on Logics-STEM-SFT-Dataset, a high-quality and diverse dataset at 10M scale that represents one of the largest-scale open-source long chain-of-thought corpora. Logics-STEM targets reasoning tasks in the domains of Science, Technology, Engineering, and Mathematics (STEM), and exhibits exceptional performance on STEM-related benchmarks with an average improvement of 4.68% over the next-best model at 8B scale. We attribute the gains to our data-algorithm co-design engine, where they are jointly optimized to fit a gold-standard distribution behind reasoning. Data-wise, the Logics-STEM-SFT-Dataset is constructed from a meticulously designed data curation engine with 5 stages to ensure the quality, diversity, and scalability, including annotation, deduplication, decontamination, distillation, and stratified sampling. Algorithm-wise, our failure-driven post-training framework leverages targeted knowledge retrieval and data synthesis around model failure regions in the Supervised Fine-tuning (SFT) stage to effectively guide the second-stage SFT or the reinforcement learning (RL) for better fitting the target distribution. The superior empirical performance of Logics-STEM reveals the vast potential of combining large-scale open-source data with carefully designed synthetic data, underscoring the critical role of data-algorithm co-design in enhancing reasoning capabilities through post-training. We make both the Logics-STEM models (8B and 32B) and the Logics-STEM-SFT-Dataset (10M and downsampled 2.2M versions) publicly available to support future research in the open-source community.
Accelerated Evolving Set Processes for Local PageRank Computation
Oct 09, 2025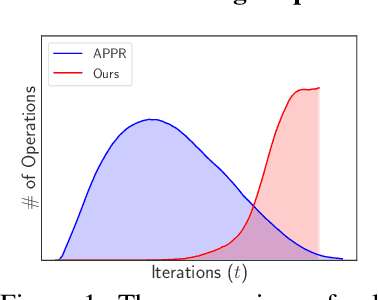

This work proposes a novel framework based on nested evolving set processes to accelerate Personalized PageRank (PPR) computation. At each stage of the process, we employ a localized inexact proximal point iteration to solve a simplified linear system. We show that the time complexity of such localized methods is upper bounded by $\min\{\tilde{\mathcal{O}}(R^2/\epsilon^2), \tilde{\mathcal{O}}(m)\}$ to obtain an $\epsilon$-approximation of the PPR vector, where $m$ denotes the number of edges in the graph and $R$ is a constant defined via nested evolving set processes. Furthermore, the algorithms induced by our framework require solving only $\tilde{\mathcal{O}}(1/\sqrt{\alpha})$ such linear systems, where $\alpha$ is the damping factor. When $1/\epsilon^2\ll m$, this implies the existence of an algorithm that computes an $\ epsilon $-approximation of the PPR vector with an overall time complexity of $\tilde{\mathcal{O}}\left(R^2 / (\sqrt{\alpha}\epsilon^2)\right)$, independent of the underlying graph size. Our result resolves an open conjecture from existing literature. Experimental results on real-world graphs validate the efficiency of our methods, demonstrating significant convergence in the early stages.
Fast and Robust Contextual Node Representation Learning over Dynamic Graphs
Nov 11, 2024



Real-world graphs grow rapidly with edge and vertex insertions over time, motivating the problem of efficiently maintaining robust node representation over evolving graphs. Recent efficient GNNs are designed to decouple recursive message passing from the learning process, and favor Personalized PageRank (PPR) as the underlying feature propagation mechanism. However, most PPR-based GNNs are designed for static graphs, and efficient PPR maintenance remains as an open problem. Further, there is surprisingly little theoretical justification for the choice of PPR, despite its impressive empirical performance. In this paper, we are inspired by the recent PPR formulation as an explicit $\ell_1$-regularized optimization problem and propose a unified dynamic graph learning framework based on sparse node-wise attention. We also present a set of desired properties to justify the choice of PPR in STOA GNNs, and serves as the guideline for future node attention designs. Meanwhile, we take advantage of the PPR-equivalent optimization formulation and employ the proximal gradient method (ISTA) to improve the efficiency of PPR-based GNNs upto 6 times. Finally, we instantiate a simple-yet-effective model (\textsc{GoPPE}) with robust positional encodings by maximizing PPR previously used as attention. The model performs comparably to or better than the STOA baselines and greatly outperforms when the initial node attributes are noisy during graph evolution, demonstrating the effectiveness and robustness of \textsc{GoPPE}.
Faster Local Solvers for Graph Diffusion Equations
Oct 29, 2024



Efficient computation of graph diffusion equations (GDEs), such as Personalized PageRank, Katz centrality, and the Heat kernel, is crucial for clustering, training neural networks, and many other graph-related problems. Standard iterative methods require accessing the whole graph per iteration, making them time-consuming for large-scale graphs. While existing local solvers approximate diffusion vectors through heuristic local updates, they often operate sequentially and are typically designed for specific diffusion types, limiting their applicability. Given that diffusion vectors are highly localizable, as measured by the participation ratio, this paper introduces a novel framework for approximately solving GDEs using a local diffusion process. This framework reveals the suboptimality of existing local solvers. Furthermore, our approach effectively localizes standard iterative solvers by designing simple and provably sublinear time algorithms. These new local solvers are highly parallelizable, making them well-suited for implementation on GPUs. We demonstrate the effectiveness of our framework in quickly obtaining approximate diffusion vectors, achieving up to a hundred-fold speed improvement, and its applicability to large-scale dynamic graphs. Our framework could also facilitate more efficient local message-passing mechanisms for GNNs.
Iterative Methods via Locally Evolving Set Process
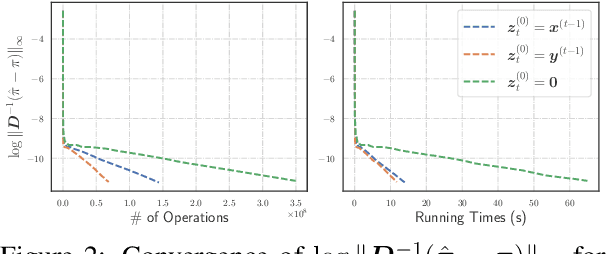
Oct 19, 2024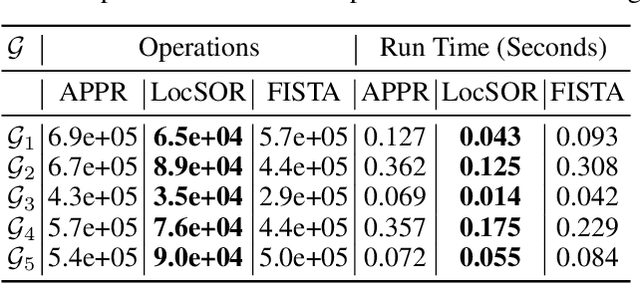
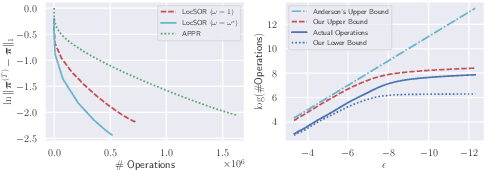


Given the damping factor $\alpha$ and precision tolerance $\epsilon$, \citet{andersen2006local} introduced Approximate Personalized PageRank (APPR), the \textit{de facto local method} for approximating the PPR vector, with runtime bounded by $\Theta(1/(\alpha\epsilon))$ independent of the graph size. Recently, \citet{fountoulakis2022open} asked whether faster local algorithms could be developed using $\tilde{O}(1/(\sqrt{\alpha}\epsilon))$ operations. By noticing that APPR is a local variant of Gauss-Seidel, this paper explores the question of \textit{whether standard iterative solvers can be effectively localized}. We propose to use the \textit{locally evolving set process}, a novel framework to characterize the algorithm locality, and demonstrate that many standard solvers can be effectively localized. Let $\overline{\operatorname{vol}}{ (S_t)}$ and $\overline{\gamma}_{t}$ be the running average of volume and the residual ratio of active nodes $\textstyle S_{t}$ during the process. We show $\overline{\operatorname{vol}}{ (S_t)}/\overline{\gamma}_{t} \leq 1/\epsilon$ and prove APPR admits a new runtime bound $\tilde{O}(\overline{\operatorname{vol}}(S_t)/(\alpha\overline{\gamma}_{t}))$ mirroring the actual performance. Furthermore, when the geometric mean of residual reduction is $\Theta(\sqrt{\alpha})$, then there exists $c \in (0,2)$ such that the local Chebyshev method has runtime $\tilde{O}(\overline{\operatorname{vol}}(S_{t})/(\sqrt{\alpha}(2-c)))$ without the monotonicity assumption. Numerical results confirm the efficiency of this novel framework and show up to a hundredfold speedup over corresponding standard solvers on real-world graphs.
Sensiverse: A dataset for ISAC study
Aug 26, 2023



In order to address the lack of applicable channel models for ISAC research and evaluation, we release Sensiverse, a dataset that can be used for ISAC research. In this paper, we present the method of generating Sensiverse, including the acquisition and formatting of the 3D scene models, the generation of the channel data and associations with Tx/Rx deployment. The file structure and usage of the dataset are also described, and finally the use of the dataset is illustrated with examples through the evaluation of use cases such as 3D environment reconstruction and moving targets.
Does it pay to optimize AUC?
Jun 02, 2023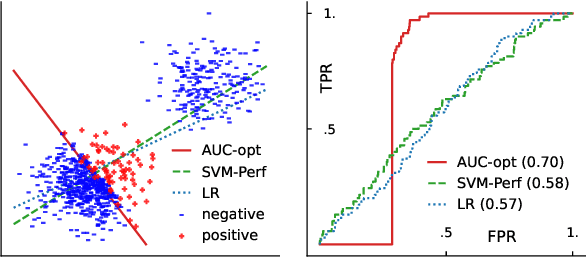
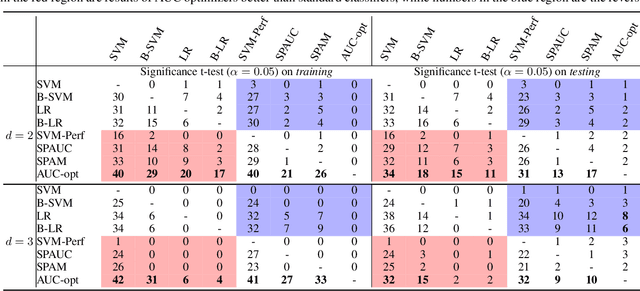
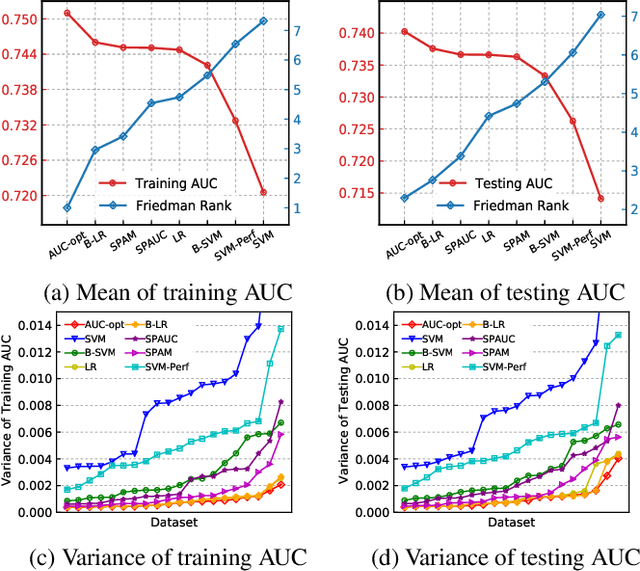
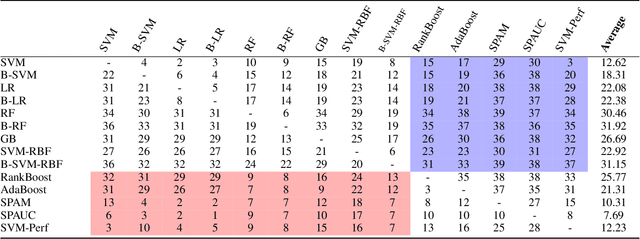
The Area Under the ROC Curve (AUC) is an important model metric for evaluating binary classifiers, and many algorithms have been proposed to optimize AUC approximately. It raises the question of whether the generally insignificant gains observed by previous studies are due to inherent limitations of the metric or the inadequate quality of optimization. To better understand the value of optimizing for AUC, we present an efficient algorithm, namely AUC-opt, to find the provably optimal AUC linear classifier in $\mathbb{R}^2$, which runs in $\mathcal{O}(n_+ n_- \log (n_+ n_-))$ where $n_+$ and $n_-$ are the number of positive and negative samples respectively. Furthermore, it can be naturally extended to $\mathbb{R}^d$ in $\mathcal{O}((n_+n_-)^{d-1}\log (n_+n_-))$ by calling AUC-opt in lower-dimensional spaces recursively. We prove the problem is NP-complete when $d$ is not fixed, reducing from the \textit{open hemisphere problem}. Experiments show that compared with other methods, AUC-opt achieves statistically significant improvements on between 17 to 40 in $\mathbb{R}^2$ and between 4 to 42 in $\mathbb{R}^3$ of 50 t-SNE training datasets. However, generally the gain proves insignificant on most testing datasets compared to the best standard classifiers. Similar observations are found for nonlinear AUC methods under real-world datasets.