 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAPoRL: Multi-Agent Post-Co-Training for Collaborative Large Language Models with Reinforcement Learning
Feb 25, 2025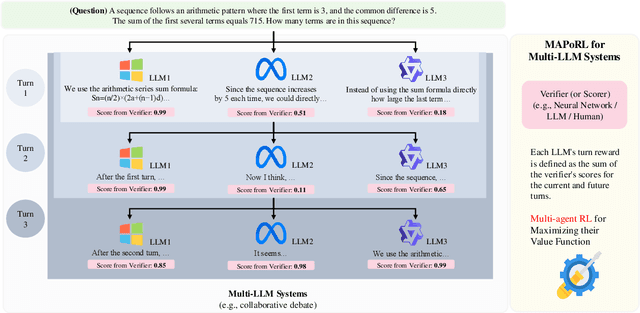
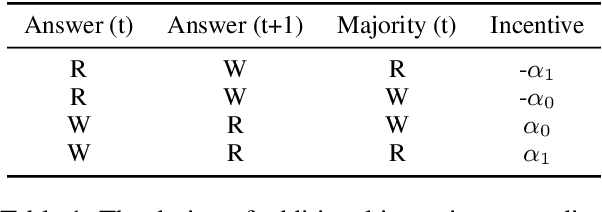
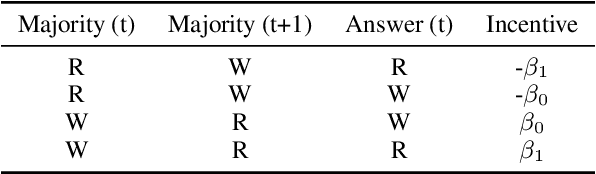
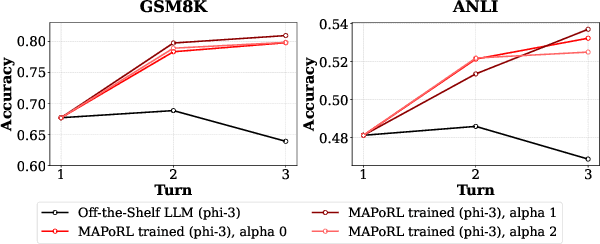
Leveraging multiple large language models (LLMs) to build collaborative multi-agentic workflows has demonstrated significant potential. However, most previous studies focus on prompting the out-of-the-box LLMs, relying on their innate capability for collaboration, which may not improve LLMs' performance as shown recently. In this paper, we introduce a new post-training paradigm MAPoRL (Multi-Agent Post-co-training for collaborative LLMs with Reinforcement Learning), to explicitly elicit the collaborative behaviors and further unleash the power of multi-agentic LLM frameworks. In MAPoRL, multiple LLMs first generate their own responses independently and engage in a multi-turn discussion to collaboratively improve the final answer. In the end, a MAPoRL verifier evaluates both the answer and the discussion, by assigning a score that verifies the correctness of the answer, while adding incentives to encourage corrective and persuasive discussions. The score serves as the co-training reward, and is then maximized through multi-agent RL. Unlike existing LLM post-training paradigms, MAPoRL advocates the co-training of multiple LLMs together using RL for better generalization. Accompanied by analytical insights, our experiments demonstrate that training individual LLMs alone is insufficient to induce effective collaboration. In contrast, multi-agent co-training can boost the collaboration performance across benchmarks, with generalization to unseen domains.
Fast and Robust Contextual Node Representation Learning over Dynamic Graphs
Nov 11, 2024



Real-world graphs grow rapidly with edge and vertex insertions over time, motivating the problem of efficiently maintaining robust node representation over evolving graphs. Recent efficient GNNs are designed to decouple recursive message passing from the learning process, and favor Personalized PageRank (PPR) as the underlying feature propagation mechanism. However, most PPR-based GNNs are designed for static graphs, and efficient PPR maintenance remains as an open problem. Further, there is surprisingly little theoretical justification for the choice of PPR, despite its impressive empirical performance. In this paper, we are inspired by the recent PPR formulation as an explicit $\ell_1$-regularized optimization problem and propose a unified dynamic graph learning framework based on sparse node-wise attention. We also present a set of desired properties to justify the choice of PPR in STOA GNNs, and serves as the guideline for future node attention designs. Meanwhile, we take advantage of the PPR-equivalent optimization formulation and employ the proximal gradient method (ISTA) to improve the efficiency of PPR-based GNNs upto 6 times. Finally, we instantiate a simple-yet-effective model (\textsc{GoPPE}) with robust positional encodings by maximizing PPR previously used as attention. The model performs comparably to or better than the STOA baselines and greatly outperforms when the initial node attributes are noisy during graph evolution, demonstrating the effectiveness and robustness of \textsc{GoPPE}.
Analyzing the Evolution of Graphs and Texts
Nov 09, 2024With the recent advance of representation learning algorithms on graphs (e.g., DeepWalk/GraphSage) and natural languages (e.g., Word2Vec/BERT) , the state-of-the art models can even achieve human-level performance over many downstream tasks, particularly for the task of node and sentence classification. However, most algorithms focus on large-scale models for static graphs and text corpus without considering the inherent dynamic characteristics or discovering the reasons behind the changes. This dissertation aims to efficiently model the dynamics in graphs (such as social networks and citation graphs) and understand the changes in texts (specifically news titles and personal biographies). To achieve this goal, we utilize the renowned Personalized PageRank algorithm to create effective dynamic network embeddings for evolving graphs. Our proposed approaches significantly improve the running time and accuracy for both detecting network abnormal intruders and discovering entity meaning shifts over large-scale dynamic graphs. For text changes, we analyze the post-publication changes in news titles to understand the intents behind the edits and discuss the potential impact of titles changes from information integrity perspective. Moreover, we investigate self-presented occupational identities in Twitter users' biographies over five years, investigating job prestige and demographics effects in how people disclose jobs, quantifying over-represented jobs and their transitions over time.
Iterative Methods via Locally Evolving Set Process
Oct 19, 2024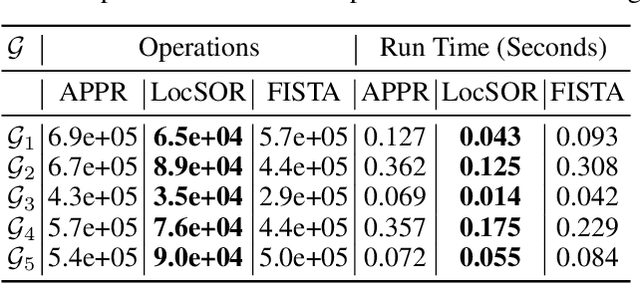
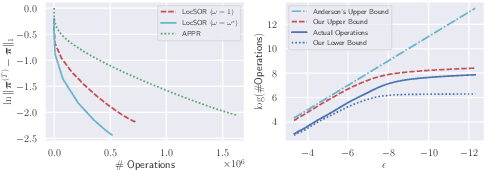


Given the damping factor $\alpha$ and precision tolerance $\epsilon$, \citet{andersen2006local} introduced Approximate Personalized PageRank (APPR), the \textit{de facto local method} for approximating the PPR vector, with runtime bounded by $\Theta(1/(\alpha\epsilon))$ independent of the graph size. Recently, \citet{fountoulakis2022open} asked whether faster local algorithms could be developed using $\tilde{O}(1/(\sqrt{\alpha}\epsilon))$ operations. By noticing that APPR is a local variant of Gauss-Seidel, this paper explores the question of \textit{whether standard iterative solvers can be effectively localized}. We propose to use the \textit{locally evolving set process}, a novel framework to characterize the algorithm locality, and demonstrate that many standard solvers can be effectively localized. Let $\overline{\operatorname{vol}}{ (S_t)}$ and $\overline{\gamma}_{t}$ be the running average of volume and the residual ratio of active nodes $\textstyle S_{t}$ during the process. We show $\overline{\operatorname{vol}}{ (S_t)}/\overline{\gamma}_{t} \leq 1/\epsilon$ and prove APPR admits a new runtime bound $\tilde{O}(\overline{\operatorname{vol}}(S_t)/(\alpha\overline{\gamma}_{t}))$ mirroring the actual performance. Furthermore, when the geometric mean of residual reduction is $\Theta(\sqrt{\alpha})$, then there exists $c \in (0,2)$ such that the local Chebyshev method has runtime $\tilde{O}(\overline{\operatorname{vol}}(S_{t})/(\sqrt{\alpha}(2-c)))$ without the monotonicity assumption. Numerical results confirm the efficiency of this novel framework and show up to a hundredfold speedup over corresponding standard solvers on real-world graphs.
Provable Fairness for Neural Network Models using Formal Verification
Dec 16, 2022



Machine learning models are increasingly deployed for critical decision-making tasks, making it important to verify that they do not contain gender or racial biases picked up from training data. Typical approaches to achieve fairness revolve around efforts to clean or curate training data, with post-hoc statistical evaluation of the fairness of the model on evaluation data. In contrast, we propose techniques to \emph{prove} fairness using recently developed formal methods that verify properties of neural network models.Beyond the strength of guarantee implied by a formal proof, our methods have the advantage that we do not need explicit training or evaluation data (which is often proprietary) in order to analyze a given trained model. In experiments on two familiar datasets in the fairness literature (COMPAS and ADULTS), we show that through proper training, we can reduce unfairness by an average of 65.4\% at a cost of less than 1\% in AUC score.
Hierarchies over Vector Space: Orienting Word and Graph Embeddings
Nov 02, 2022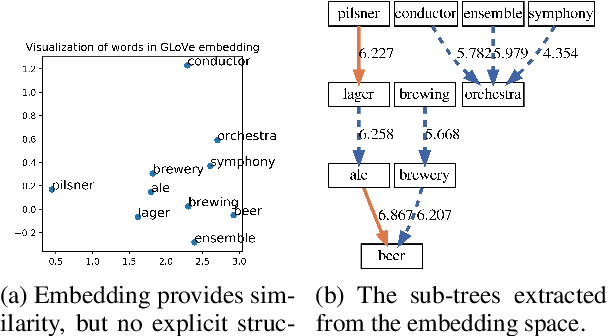



Word and graph embeddings are widely used in deep learning applications. We present a data structure that captures inherent hierarchical properties from an unordered flat embedding space, particularly a sense of direction between pairs of entities. Inspired by the notion of \textit{distributional generality}, our algorithm constructs an arborescence (a directed rooted tree) by inserting nodes in descending order of entity power (e.g., word frequency), pointing each entity to the closest more powerful node as its parent. We evaluate the performance of the resulting tree structures on three tasks: hypernym relation discovery, least-common-ancestor (LCA) discovery among words, and Wikipedia page link recovery. We achieve average 8.98\% and 2.70\% for hypernym and LCA discovery across five languages and 62.76\% accuracy on directed Wiki-page link recovery, with both substantially above baselines. Finally, we investigate the effect of insertion order, the power/similarity trade-off and various power sources to optimize parent selection.
Improving Device Directedness Classification of Utterances with Semantic Lexical Features
Sep 29, 2020
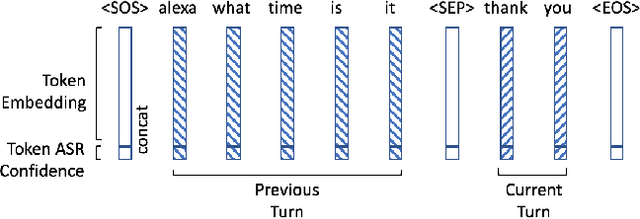
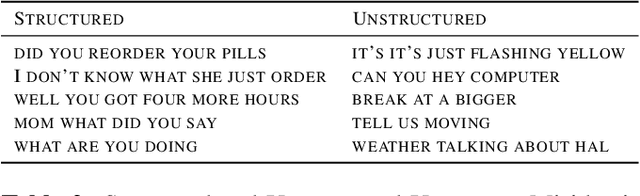

User interactions with personal assistants like Alexa, Google Home and Siri are typically initiated by a wake term or wakeword. Several personal assistants feature "follow-up" modes that allow users to make additional interactions without the need of a wakeword. For the system to only respond when appropriate, and to ignore speech not intended for it, utterances must be classified as device-directed or non-device-directed. State-of-the-art systems have largely used acoustic features for this task, while others have used only lexical features or have added LM-based lexical features. We propose a directedness classifier that combines semantic lexical features with a lightweight acoustic feature and show it is effective in classifying directedness. The mixed-domain lexical and acoustic feature model is able to achieve 14% relative reduction of EER over a state-of-the-art acoustic-only baseline model. Finally, we successfully apply transfer learning and semi-supervised learning to the model to improve accuracy even further.
* Accepted and Published at ICASSP 2020
COMET: Convolutional Dimension Interaction for Deep Matrix Factorization
Aug 18, 2020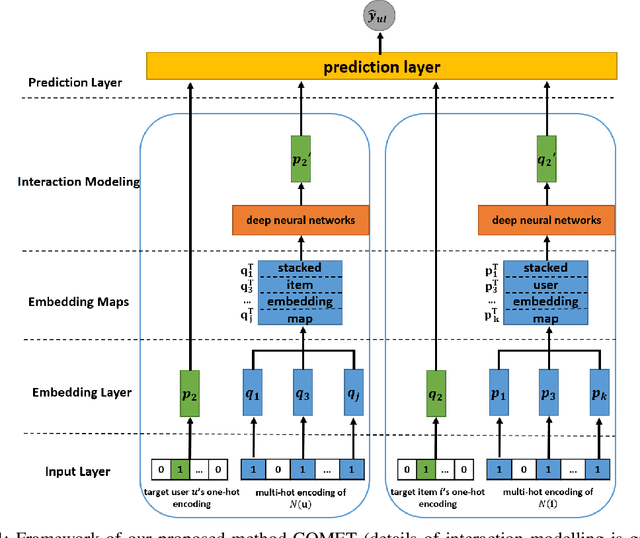
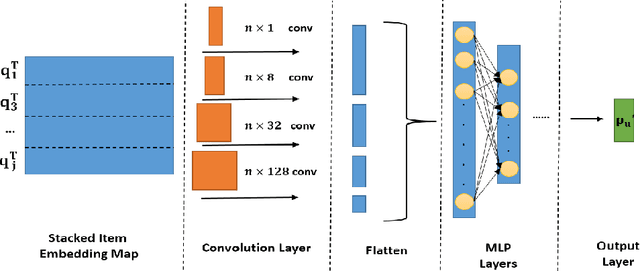
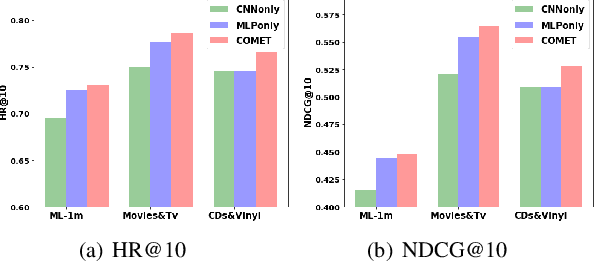
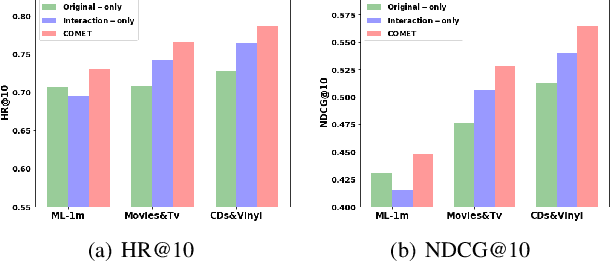
Latent factor models play a dominant role among recommendation techniques. However, most of the existing latent factor models assume embedding dimensions are independent of each other, and thus regrettably ignore the interaction information across different embedding dimensions. In this paper, we propose a novel latent factor model called COMET (COnvolutional diMEnsion inTeraction), which provides the first attempt to model higher-order interaction signals among all latent dimensions in an explicit manner. To be specific, COMET stacks the embeddings of historical interactions horizontally, which results in two "embedding maps" that encode the original dimension information. In this way, users' and items' internal interactions can be exploited by convolutional neural networks with kernels of different sizes and a fully-connected multi-layer perceptron. Furthermore, the representations of users and items are enriched by the learnt interaction vectors, which can further be used to produce the final prediction. Extensive experiments and ablation studies on various public implicit feedback datasets clearly demonstrate the effectiveness and the rationality of our proposed method.