 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating Summarization and Retrieval for Enhanced Personalization via Large Language Models
Oct 30, 2023



Personalization, the ability to tailor a system to individual users, is an essential factor in user experience with natural language processing (NLP) systems. With the emergence of Large Language Models (LLMs), a key question is how to leverage these models to better personalize user experiences. To personalize a language model's output, a straightforward approach is to incorporate past user data into the language model prompt, but this approach can result in lengthy inputs exceeding limitations on input length and incurring latency and cost issues. Existing approaches tackle such challenges by selectively extracting relevant user data (i.e. selective retrieval) to construct a prompt for downstream tasks. However, retrieval-based methods are limited by potential information loss, lack of more profound user understanding, and cold-start challenges. To overcome these limitations, we propose a novel summary-augmented approach by extending retrieval-augmented personalization with task-aware user summaries generated by LLMs. The summaries can be generated and stored offline, enabling real-world systems with runtime constraints like voice assistants to leverage the power of LLMs. Experiments show our method with 75% less of retrieved user data is on-par or outperforms retrieval augmentation on most tasks in the LaMP personalization benchmark. We demonstrate that offline summarization via LLMs and runtime retrieval enables better performance for personalization on a range of tasks under practical constraints.
Improving Device Directedness Classification of Utterances with Semantic Lexical Features
Sep 29, 2020
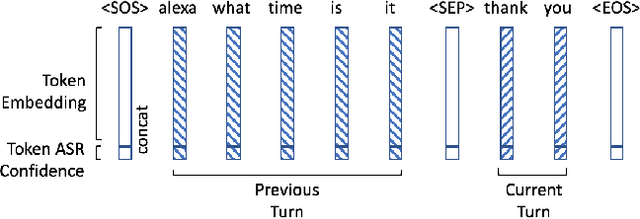
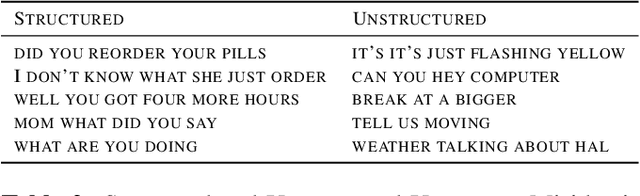

User interactions with personal assistants like Alexa, Google Home and Siri are typically initiated by a wake term or wakeword. Several personal assistants feature "follow-up" modes that allow users to make additional interactions without the need of a wakeword. For the system to only respond when appropriate, and to ignore speech not intended for it, utterances must be classified as device-directed or non-device-directed. State-of-the-art systems have largely used acoustic features for this task, while others have used only lexical features or have added LM-based lexical features. We propose a directedness classifier that combines semantic lexical features with a lightweight acoustic feature and show it is effective in classifying directedness. The mixed-domain lexical and acoustic feature model is able to achieve 14% relative reduction of EER over a state-of-the-art acoustic-only baseline model. Finally, we successfully apply transfer learning and semi-supervised learning to the model to improve accuracy even further.
* Accepted and Published at ICASSP 2020
LSTM-based Whisper Detection
Sep 20, 2018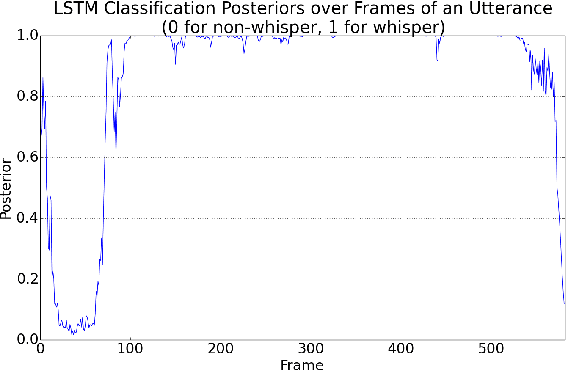

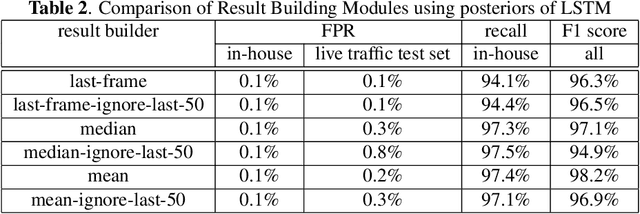
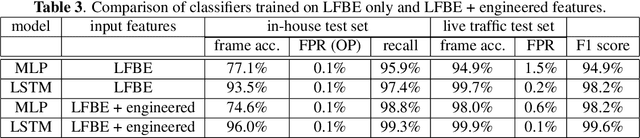
This article presents a whisper speech detector in the far-field domain. The proposed system consists of a long-short term memory (LSTM) neural network trained on log-filterbank energy (LFBE) acoustic features. This model is trained and evaluated on recordings of human interactions with voice-controlled, far-field devices in whisper and normal phonation modes. We compare multiple inference approaches for utterance-level classification by examining trajectories of the LSTM posteriors. In addition, we engineer a set of features based on the signal characteristics inherent to whisper speech, and evaluate their effectiveness in further separating whisper from normal speech. A benchmarking of these features using multilayer perceptrons (MLP) and LSTMs suggests that the proposed features, in combination with LFBE features, can help us further improve our classifiers. We prove that, with enough data, the LSTM model is indeed as capable of learning whisper characteristics from LFBE features alone com- pared to a simpler MLP model that uses both LFBE and features engineered for separating whisper and normal speech. In addition, we prove that the LSTM classifiers accuracy can be further improved with the incorporation of the proposed engineered features.