 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTCDformer-based Momentum Transfer Model for Long-term Sports Prediction
Sep 16, 2024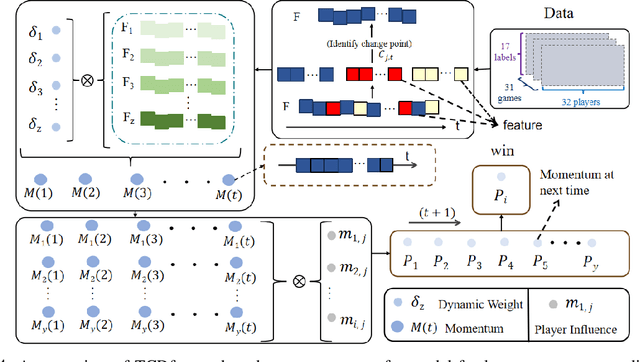
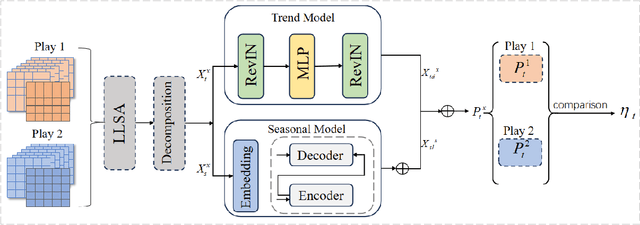
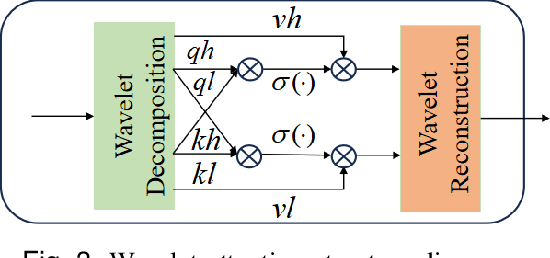

Accurate sports prediction is a crucial skill for professional coaches, which can assist in developing effective training strategies and scientific competition tactics. Traditional methods often use complex mathematical statistical techniques to boost predictability, but this often is limited by dataset scale and has difficulty handling long-term predictions with variable distributions, notably underperforming when predicting point-set-game multi-level matches. To deal with this challenge, this paper proposes TM2, a TCDformer-based Momentum Transfer Model for long-term sports prediction, which encompasses a momentum encoding module and a prediction module based on momentum transfer. TM2 initially encodes momentum in large-scale unstructured time series using the local linear scaling approximation (LLSA) module. Then it decomposes the reconstructed time series with momentum transfer into trend and seasonal components. The final prediction results are derived from the additive combination of a multilayer perceptron (MLP) for predicting trend components and wavelet attention mechanisms for seasonal components. Comprehensive experimental results show that on the 2023 Wimbledon men's tournament datasets, TM2 significantly surpasses existing sports prediction models in terms of performance, reducing MSE by 61.64% and MAE by 63.64%.
Exploring Kolmogorov-Arnold networks for realistic image sharpness assessment
Sep 12, 2024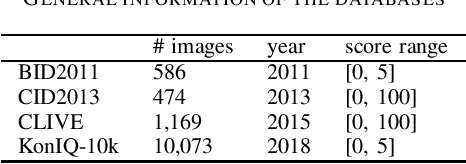
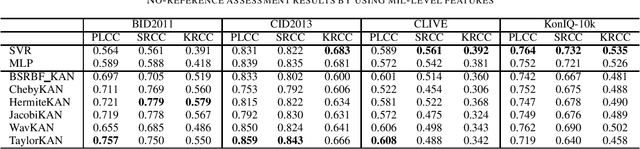
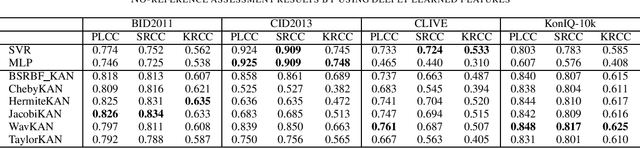
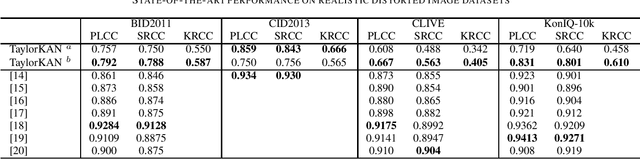
Score prediction is crucial in realistic image sharpness assessment after informative features are collected. Recently, Kolmogorov-Arnold networks (KANs) have been developed and witnessed remarkable success in data fitting. This study presents Taylor series based KAN (TaylorKAN). Then, different KANs are explored on four realistic image databases (BID2011, CID2013, CLIVE, and KonIQ-10k) for score prediction by using 15 mid-level features and 2048 high-level features. When setting support vector regression as the baseline, experimental results indicate KANs are generally better or competitive, TaylorKAN is the best on three databases using mid-level feature input, while KANs are inferior on CLIVE when high-level features are used. This is the first study that explores KANs for image quality assessment. It sheds lights on how to select and improve KANs on related tasks.
Learning Autonomous Mobility Using Real Demonstration Data
Aug 10, 2021



This work proposed an efficient learning-based framework to learn feedback control policies from human teleoperated demonstrations, which achieved obstacle negotiation, staircase traversal, slipping control and parcel delivery for a tracked robot. Due to uncertainties in real-world scenarios, eg obstacle and slippage, closed-loop feedback control plays an important role in improving robustness and resilience, but the control laws are difficult to program manually for achieving autonomous behaviours. We formulated an architecture based on a long-short-term-memory (LSTM) neural network, which effectively learn reactive control policies from human demonstrations. Using datasets from a few real demonstrations, our algorithm can directly learn successful policies, including obstacle-negotiation, stair-climbing and delivery, fall recovery and corrective control of slippage. We proposed decomposition of complex robot actions to reduce the difficulty of learning the long-term dependencies. Furthermore, we proposed a method to efficiently handle non-optimal demos and to learn new skills, since collecting enough demonstration can be time-consuming and sometimes very difficult on a real robotic system.
Multimodal Interfaces for Effective Teleoperation
Mar 31, 2020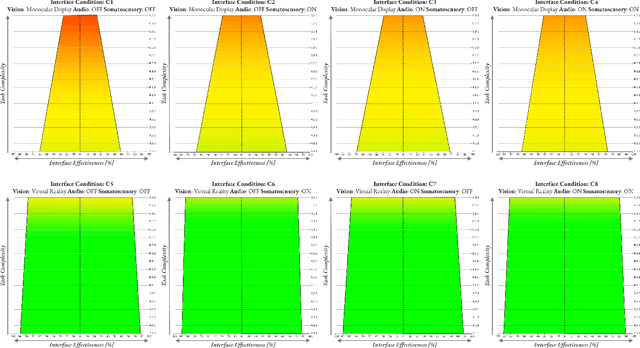
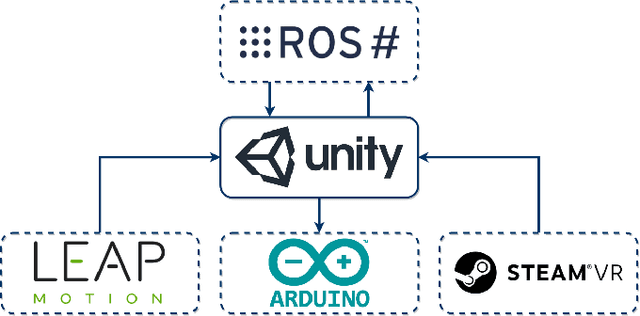
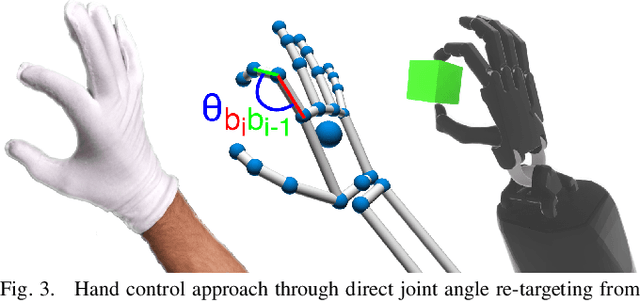

Research in multi-modal interfaces aims to provide solutions to immersion and increase overall human performance. A promising direction is combining auditory, visual and haptic interaction between the user and the simulated environment. However, no extensive comparisons exist to show how combining audiovisuohaptic interfaces affects human perception reflected on task performance. Our paper explores this idea. We present a thorough, full-factorial comparison of how all combinations of audio, visual and haptic interfaces affect performance during manipulation. We evaluate how each interface combination affects performance in a study (N=25) consisting of manipulating tasks of varying difficulty. Performance is assessed using both subjective, assessing cognitive workload and system usability, and objective measurements, incorporating time and spatial accuracy-based metrics. Results show that regardless of task complexity, using stereoscopic-vision with the VRHMD increased performance across all measurements by 40% compared to monocular-vision from the display monitor. Using haptic feedback improved outcomes by 10% and auditory feedback accounted for approximately 5% improvement.
LSTM-based Whisper Detection
Sep 20, 2018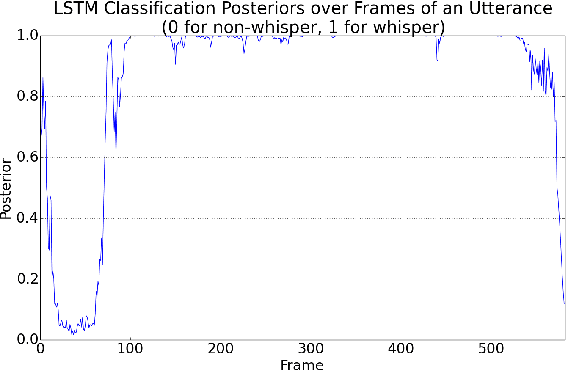

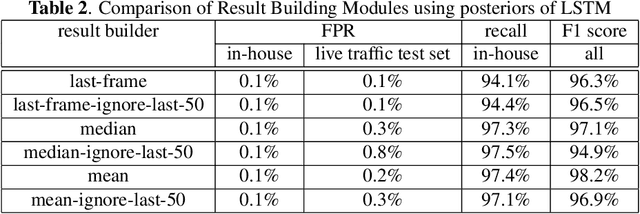
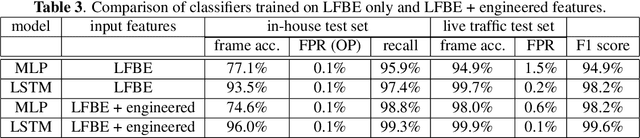
This article presents a whisper speech detector in the far-field domain. The proposed system consists of a long-short term memory (LSTM) neural network trained on log-filterbank energy (LFBE) acoustic features. This model is trained and evaluated on recordings of human interactions with voice-controlled, far-field devices in whisper and normal phonation modes. We compare multiple inference approaches for utterance-level classification by examining trajectories of the LSTM posteriors. In addition, we engineer a set of features based on the signal characteristics inherent to whisper speech, and evaluate their effectiveness in further separating whisper from normal speech. A benchmarking of these features using multilayer perceptrons (MLP) and LSTMs suggests that the proposed features, in combination with LFBE features, can help us further improve our classifiers. We prove that, with enough data, the LSTM model is indeed as capable of learning whisper characteristics from LFBE features alone com- pared to a simpler MLP model that uses both LFBE and features engineered for separating whisper and normal speech. In addition, we prove that the LSTM classifiers accuracy can be further improved with the incorporation of the proposed engineered features.