 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModular Neural Network Policies for Learning In-Flight Object Catching with a Robot Hand-Arm System
Dec 21, 2023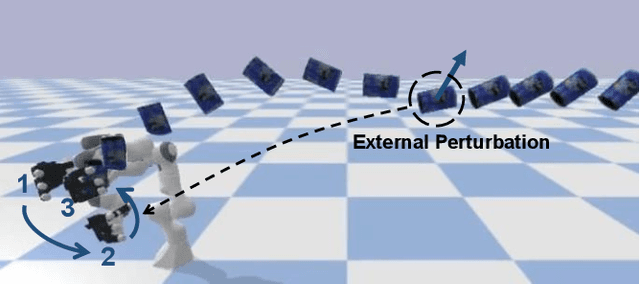
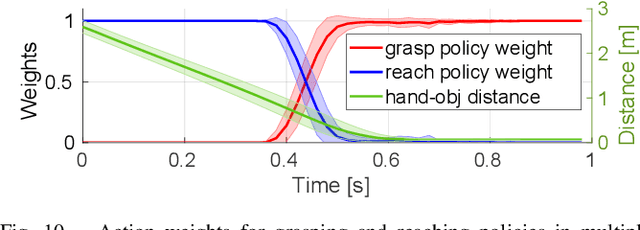


We present a modular framework designed to enable a robot hand-arm system to learn how to catch flying objects, a task that requires fast, reactive, and accurately-timed robot motions. Our framework consists of five core modules: (i) an object state estimator that learns object trajectory prediction, (ii) a catching pose quality network that learns to score and rank object poses for catching, (iii) a reaching control policy trained to move the robot hand to pre-catch poses, (iv) a grasping control policy trained to perform soft catching motions for safe and robust grasping, and (v) a gating network trained to synthesize the actions given by the reaching and grasping policy. The former two modules are trained via supervised learning and the latter three use deep reinforcement learning in a simulated environment. We conduct extensive evaluations of our framework in simulation for each module and the integrated system, to demonstrate high success rates of in-flight catching and robustness to perturbations and sensory noise. Whilst only simple cylindrical and spherical objects are used for training, the integrated system shows successful generalization to a variety of household objects that are not used in training.
Intrinsic Language-Guided Exploration for Complex Long-Horizon Robotic Manipulation Tasks
Sep 28, 2023Current reinforcement learning algorithms struggle in sparse and complex environments, most notably in long-horizon manipulation tasks entailing a plethora of different sequences. In this work, we propose the Intrinsically Guided Exploration from Large Language Models (IGE-LLMs) framework. By leveraging LLMs as an assistive intrinsic reward, IGE-LLMs guides the exploratory process in reinforcement learning to address intricate long-horizon with sparse rewards robotic manipulation tasks. We evaluate our framework and related intrinsic learning methods in an environment challenged with exploration, and a complex robotic manipulation task challenged by both exploration and long-horizons. Results show IGE-LLMs (i) exhibit notably higher performance over related intrinsic methods and the direct use of LLMs in decision-making, (ii) can be combined and complement existing learning methods highlighting its modularity, (iii) are fairly insensitive to different intrinsic scaling parameters, and (iv) maintain robustness against increased levels of uncertainty and horizons.
RObotic MAnipulation Network (ROMAN) $\unicode{x2013}$ Hybrid Hierarchical Learning for Solving Complex Sequential Tasks
Jul 07, 2023Solving long sequential tasks poses a significant challenge in embodied artificial intelligence. Enabling a robotic system to perform diverse sequential tasks with a broad range of manipulation skills is an active area of research. In this work, we present a Hybrid Hierarchical Learning framework, the Robotic Manipulation Network (ROMAN), to address the challenge of solving multiple complex tasks over long time horizons in robotic manipulation. ROMAN achieves task versatility and robust failure recovery by integrating behavioural cloning, imitation learning, and reinforcement learning. It consists of a central manipulation network that coordinates an ensemble of various neural networks, each specialising in distinct re-combinable sub-tasks to generate their correct in-sequence actions for solving complex long-horizon manipulation tasks. Experimental results show that by orchestrating and activating these specialised manipulation experts, ROMAN generates correct sequential activations for accomplishing long sequences of sophisticated manipulation tasks and achieving adaptive behaviours beyond demonstrations, while exhibiting robustness to various sensory noises. These results demonstrate the significance and versatility of ROMAN's dynamic adaptability featuring autonomous failure recovery capabilities, and highlight its potential for various autonomous manipulation tasks that demand adaptive motor skills.
Identifying Important Sensory Feedback for Learning Locomotion Skills
Jun 29, 2023Robot motor skills can be learned through deep reinforcement learning (DRL) by neural networks as state-action mappings. While the selection of state observations is crucial, there has been a lack of quantitative analysis to date. Here, we present a systematic saliency analysis that quantitatively evaluates the relative importance of different feedback states for motor skills learned through DRL. Our approach can identify the most essential feedback states for locomotion skills, including balance recovery, trotting, bounding, pacing and galloping. By using only key states including joint positions, gravity vector, base linear and angular velocities, we demonstrate that a simulated quadruped robot can achieve robust performance in various test scenarios across these distinct skills. The benchmarks using task performance metrics show that locomotion skills learned with key states can achieve comparable performance to those with all states, and the task performance or learning success rate will drop significantly if key states are missing. This work provides quantitative insights into the relationship between state observations and specific types of motor skills, serving as a guideline for robot motor learning. The proposed method is applicable to differentiable state-action mapping, such as neural network based control policies, enabling the learning of a wide range of motor skills with minimal sensing dependencies.
Metrics for 3D Object Pointing and Manipulation in Virtual Reality
Jun 12, 2021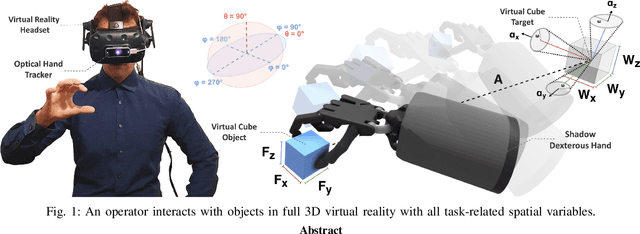

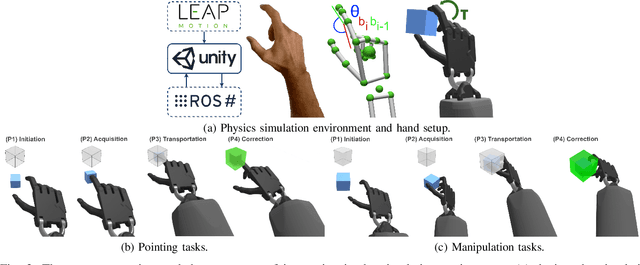
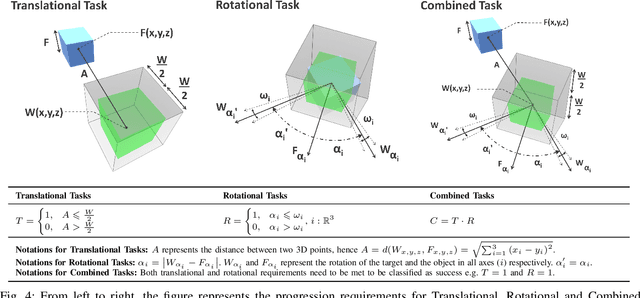
Assessing the performance of human movements during teleoperation and virtual reality is a challenging problem, particularly in 3D space due to complex spatial settings. Despite the presence of a multitude of metrics, a compelling standardized 3D metric is yet missing, aggravating inter-study comparability between different studies. Hence, evaluating human performance in virtual environments is a long-standing research goal, and a performance metric that combines two or more metrics under one formulation remains largely unexplored, particularly in higher dimensions. The absence of such a metric is primarily attributed to the discrepancies between pointing and manipulation, the complex spatial variables in 3D, and the combination of translational and rotational movements altogether. In this work, four experiments were designed and conducted with progressively higher spatial complexity to study and compare existing metrics thoroughly. The research goal was to quantify the difficulty of these 3D tasks and model human performance sufficiently in full 3D peripersonal space. Consequently, a new model extension has been proposed and its applicability has been validated across all the experimental results, showing improved modelling and representation of human performance in combined movements of 3D object pointing and manipulation tasks than existing work. Lastly, the implications on 3D interaction, teleoperation and object task design in virtual reality are discussed.
Considerations and Challenges of Measuring Operator Performance in Telepresence and Teleoperation Entailing Mixed Reality Technologies
Mar 25, 2021Assessing human performance in robotic scenarios such as those seen in telepresence and teleoperation has always been a challenging task. With the recent spike in mixed reality technologies and the subsequent focus by researchers, new pathways have opened in elucidating human perception and maximising overall immersion. Yet with the multitude of different assessment methods in evaluating operator performance in virtual environments within the field of HCI and HRI, inter-study comparability and transferability are limited. In this short paper, we present a brief overview of existing methods in assessing operator performance including subjective and objective approaches while also attempting to capture future technical challenges and frontiers. The ultimate goal is to assist and pinpoint readers towards potentially important directions with the future hope of providing a unified immersion framework for teleoperation and telepresence by standardizing a set of guidelines and evaluation methods.
The Challenges in Modeling Human Performance in 3D Space with Fitts' Law
Jan 01, 2021
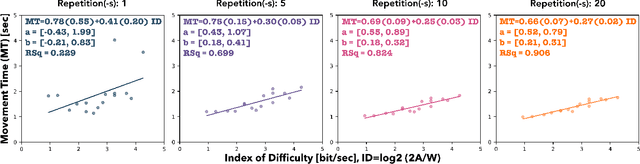
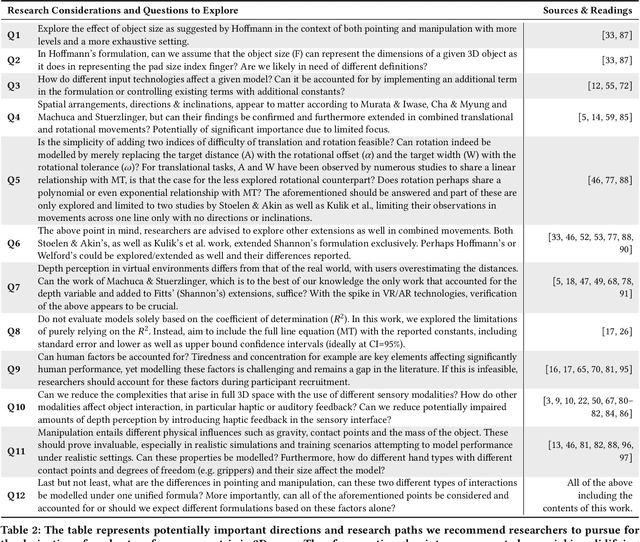
With the rapid growth in virtual reality technologies, object interaction is becoming increasingly more immersive, elucidating human perception and leading to promising directions towards evaluating human performance under different settings. This spike in technological growth exponentially increased the need for a human performance metric in 3D space. Fitts' law is perhaps the most widely used human prediction model in HCI history attempting to capture human movement in lower dimensions. Despite the collective effort towards deriving an advanced extension of a 3D human performance model based on Fitts' law, a standardized metric is still missing. Moreover, most of the extensions to date assume or limit their findings to certain settings, effectively disregarding important variables that are fundamental to 3D object interaction. In this review, we investigate and analyze the most prominent extensions of Fitts' law and compare their characteristics pinpointing to potentially important aspects for deriving a higher-dimensional performance model. Lastly, we mention the complexities, frontiers as well as potential challenges that may lay ahead.
Multimodal Interfaces for Effective Teleoperation
Mar 31, 2020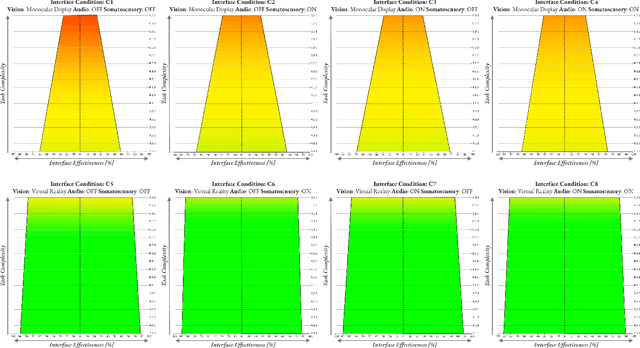
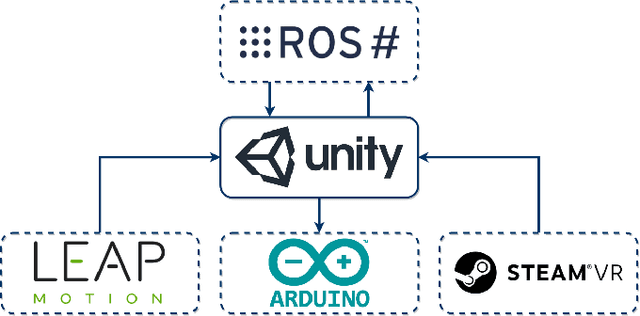
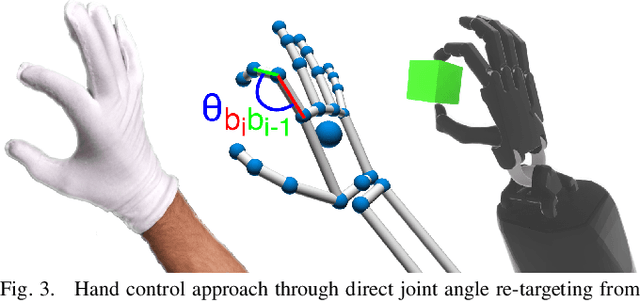

Research in multi-modal interfaces aims to provide solutions to immersion and increase overall human performance. A promising direction is combining auditory, visual and haptic interaction between the user and the simulated environment. However, no extensive comparisons exist to show how combining audiovisuohaptic interfaces affects human perception reflected on task performance. Our paper explores this idea. We present a thorough, full-factorial comparison of how all combinations of audio, visual and haptic interfaces affect performance during manipulation. We evaluate how each interface combination affects performance in a study (N=25) consisting of manipulating tasks of varying difficulty. Performance is assessed using both subjective, assessing cognitive workload and system usability, and objective measurements, incorporating time and spatial accuracy-based metrics. Results show that regardless of task complexity, using stereoscopic-vision with the VRHMD increased performance across all measurements by 40% compared to monocular-vision from the display monitor. Using haptic feedback improved outcomes by 10% and auditory feedback accounted for approximately 5% improvement.