 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying Important Sensory Feedback for Learning Locomotion Skills
Jun 29, 2023Robot motor skills can be learned through deep reinforcement learning (DRL) by neural networks as state-action mappings. While the selection of state observations is crucial, there has been a lack of quantitative analysis to date. Here, we present a systematic saliency analysis that quantitatively evaluates the relative importance of different feedback states for motor skills learned through DRL. Our approach can identify the most essential feedback states for locomotion skills, including balance recovery, trotting, bounding, pacing and galloping. By using only key states including joint positions, gravity vector, base linear and angular velocities, we demonstrate that a simulated quadruped robot can achieve robust performance in various test scenarios across these distinct skills. The benchmarks using task performance metrics show that locomotion skills learned with key states can achieve comparable performance to those with all states, and the task performance or learning success rate will drop significantly if key states are missing. This work provides quantitative insights into the relationship between state observations and specific types of motor skills, serving as a guideline for robot motor learning. The proposed method is applicable to differentiable state-action mapping, such as neural network based control policies, enabling the learning of a wide range of motor skills with minimal sensing dependencies.
Metrics for 3D Object Pointing and Manipulation in Virtual Reality
Jun 12, 2021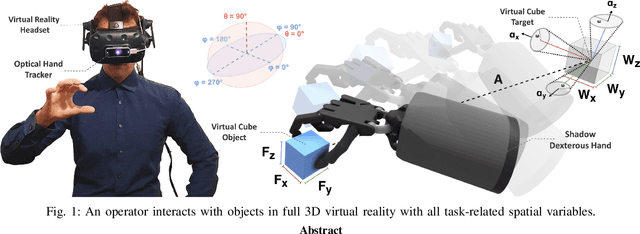

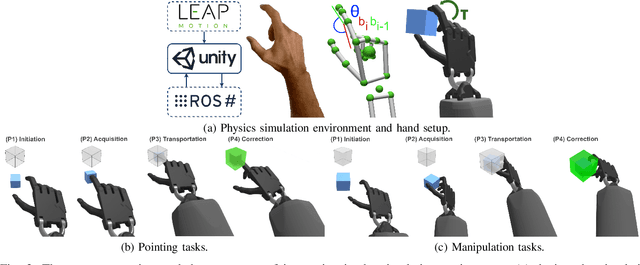
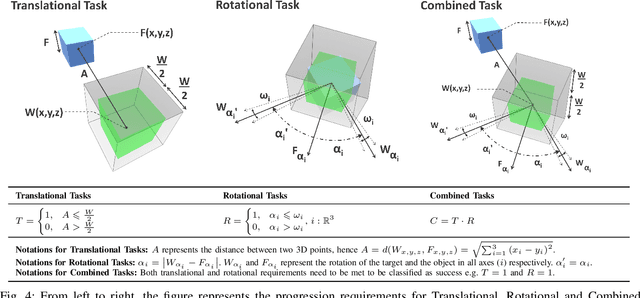
Assessing the performance of human movements during teleoperation and virtual reality is a challenging problem, particularly in 3D space due to complex spatial settings. Despite the presence of a multitude of metrics, a compelling standardized 3D metric is yet missing, aggravating inter-study comparability between different studies. Hence, evaluating human performance in virtual environments is a long-standing research goal, and a performance metric that combines two or more metrics under one formulation remains largely unexplored, particularly in higher dimensions. The absence of such a metric is primarily attributed to the discrepancies between pointing and manipulation, the complex spatial variables in 3D, and the combination of translational and rotational movements altogether. In this work, four experiments were designed and conducted with progressively higher spatial complexity to study and compare existing metrics thoroughly. The research goal was to quantify the difficulty of these 3D tasks and model human performance sufficiently in full 3D peripersonal space. Consequently, a new model extension has been proposed and its applicability has been validated across all the experimental results, showing improved modelling and representation of human performance in combined movements of 3D object pointing and manipulation tasks than existing work. Lastly, the implications on 3D interaction, teleoperation and object task design in virtual reality are discussed.
Reachability Map for Diverse Balancing Strategies and Energy Efficient Stepping of Humanoids
May 03, 2021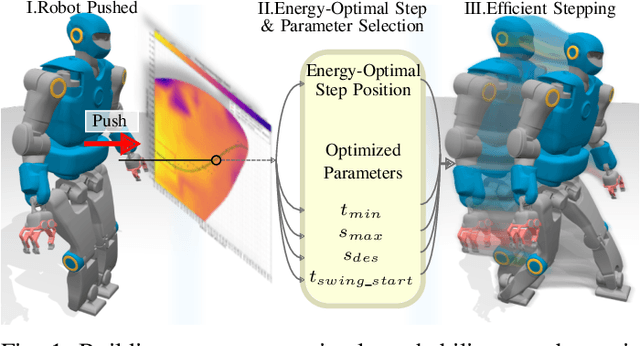
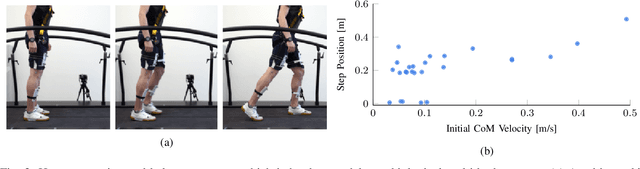
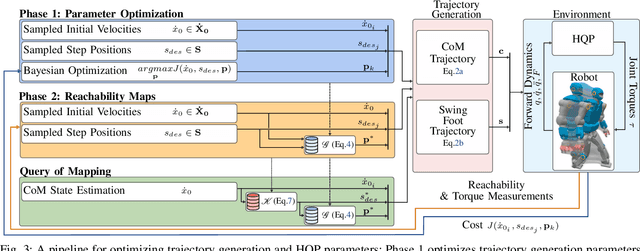
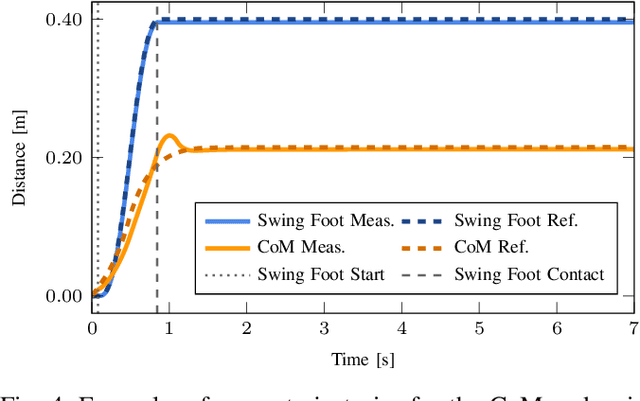
In legged locomotion, the relationship between different gait behaviors and energy consumption must consider the full-body dynamics and the robot control as a whole, which cannot be captured by simple models. This work studies the robot dynamics and whole-body optimal control as a coupled system to investigate energy consumption during balance recovery. We developed a 2-phase nonlinear optimization pipeline for dynamic stepping, which generates reachability maps showing complex energy-stepping relations. We optimize gait parameters to search all reachable locations and quantify the energy cost during dynamic transitions, which allows studying the relationship between energy consumption and stepping locations given different initial conditions. We found that to achieve efficient actuation, the stepping location and timing can have simple approximations close to the underlying optimality. Despite the complexity of this nonlinear process, we show that near-minimal effort stepping locations fall within a region of attractions, rather than a narrow solution space suggested by a simple model. This provides new insights into the non-uniqueness of near-optimal solutions in robot motion planning and control, and the diversity of stepping behavior in humans.
Multimodal Interfaces for Effective Teleoperation
Mar 31, 2020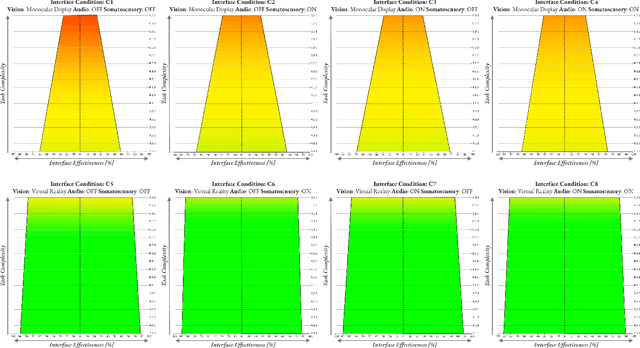
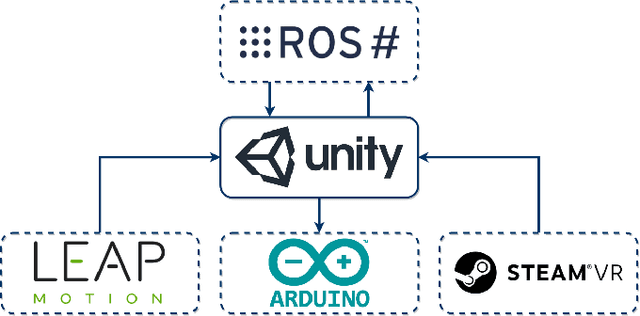
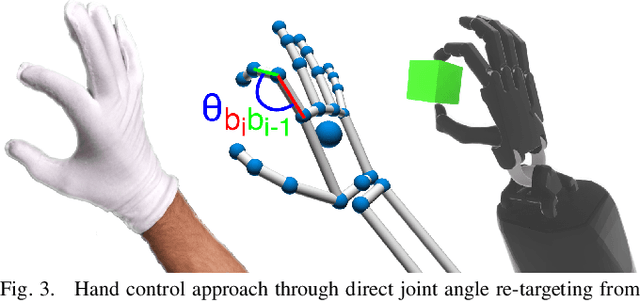

Research in multi-modal interfaces aims to provide solutions to immersion and increase overall human performance. A promising direction is combining auditory, visual and haptic interaction between the user and the simulated environment. However, no extensive comparisons exist to show how combining audiovisuohaptic interfaces affects human perception reflected on task performance. Our paper explores this idea. We present a thorough, full-factorial comparison of how all combinations of audio, visual and haptic interfaces affect performance during manipulation. We evaluate how each interface combination affects performance in a study (N=25) consisting of manipulating tasks of varying difficulty. Performance is assessed using both subjective, assessing cognitive workload and system usability, and objective measurements, incorporating time and spatial accuracy-based metrics. Results show that regardless of task complexity, using stereoscopic-vision with the VRHMD increased performance across all measurements by 40% compared to monocular-vision from the display monitor. Using haptic feedback improved outcomes by 10% and auditory feedback accounted for approximately 5% improvement.
Optimisation of Body-ground Contact for Augmenting Whole-Body Loco-manipulation of Quadruped Robots
Feb 24, 2020

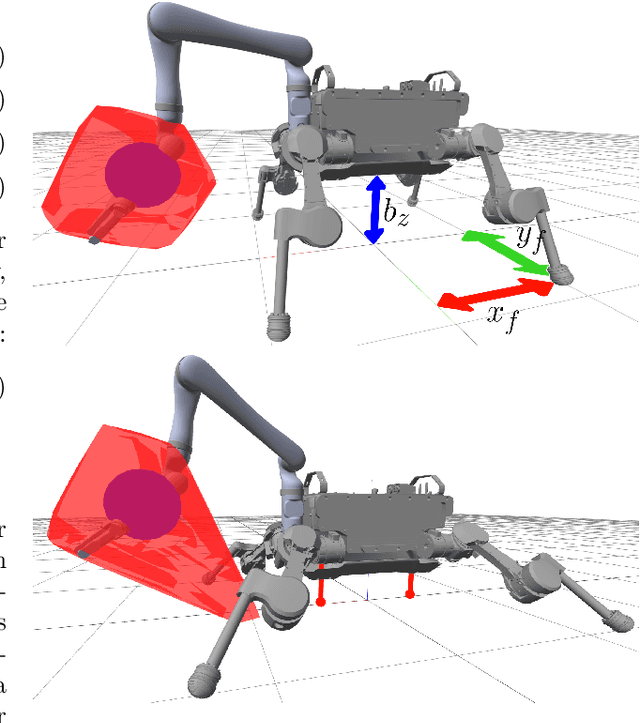

Legged robots have great potential to perform loco-manipulation tasks, yet it is challenging to keep the robot balanced while it interacts with the environment. In this paper we study the use of additional contact points for maximising the robustness of loco-manipulation motions. Specifically, body-ground contact is studied for enhancing robustness and manipulation capabilities of quadrupedal robots. We propose to equip the robot with prongs: small legs rigidly attached to the body which ensure body-ground contact occurs in controllable point-contacts. The effect of these prongs on robustness is quantified by computing the Smallest Unrejectable Force (SUF), a measure of robustness related to Feasible Wrench Polytopes. We apply the SUF to assess the robustness of the system, and propose an effective approximation of the SUF that can be computed at near-real-time speed. We design a hierarchical quadratic programming based whole-body controller that controls stable interaction when the prongs are in contact with the ground. This novel concept of using prongs and the resulting control framework are all implemented on hardware to validate the effectiveness of the increased robustness and newly enabled loco-manipulation tasks, such as obstacle clearance and manipulation of a large object.
Recurrent Deterministic Policy Gradient Method for Bipedal Locomotion on Rough Terrain Challenge
Sep 13, 2018
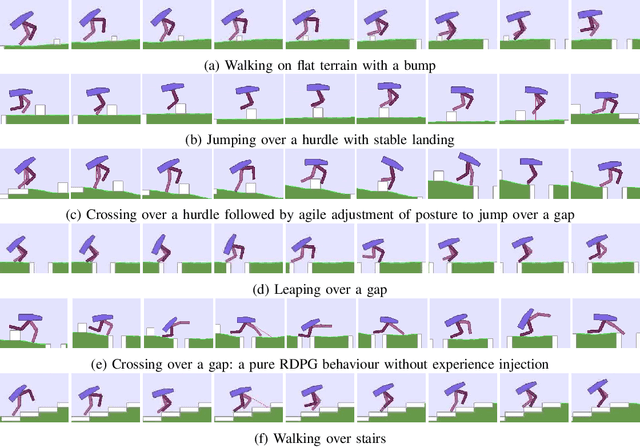

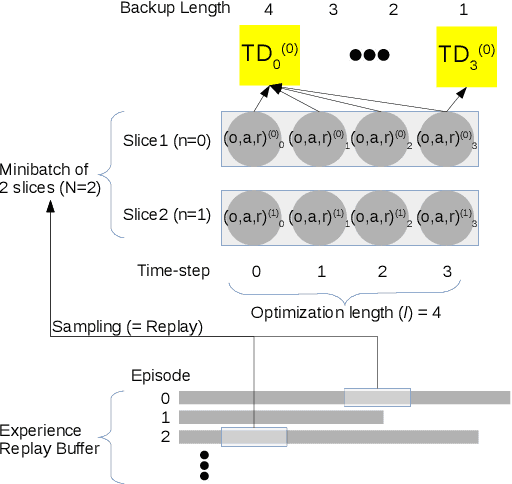
This paper presents a deep learning framework that is capable of solving partially observable locomotion tasks based on our novel interpretation of Recurrent Deterministic Policy Gradient (RDPG). We study on bias of sampled error measure and its variance induced by the partial observability of environment and subtrajectory sampling, respectively. Three major improvements are introduced in our RDPG based learning framework: tail-step bootstrap of interpolated temporal difference, initialisation of hidden state using past trajectory scanning, and injection of external experiences learned by other agents. The proposed learning framework was implemented to solve the Bipedal-Walker challenge in OpenAI's gym simulation environment where only partial state information is available. Our simulation study shows that the autonomous behaviors generated by the RDPG agent are highly adaptive to a variety of obstacles and enables the agent to effectively traverse rugged terrains for long distance with higher success rate than leading contenders.