 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSATA: Safe and Adaptive Torque-Based Locomotion Policies Inspired by Animal Learning
Feb 18, 2025



Despite recent advances in learning-based controllers for legged robots, deployments in human-centric environments remain limited by safety concerns. Most of these approaches use position-based control, where policies output target joint angles that must be processed by a low-level controller (e.g., PD or impedance controllers) to compute joint torques. Although impressive results have been achieved in controlled real-world scenarios, these methods often struggle with compliance and adaptability when encountering environments or disturbances unseen during training, potentially resulting in extreme or unsafe behaviors. Inspired by how animals achieve smooth and adaptive movements by controlling muscle extension and contraction, torque-based policies offer a promising alternative by enabling precise and direct control of the actuators in torque space. In principle, this approach facilitates more effective interactions with the environment, resulting in safer and more adaptable behaviors. However, challenges such as a highly nonlinear state space and inefficient exploration during training have hindered their broader adoption. To address these limitations, we propose SATA, a bio-inspired framework that mimics key biomechanical principles and adaptive learning mechanisms observed in animal locomotion. Our approach effectively addresses the inherent challenges of learning torque-based policies by significantly improving early-stage exploration, leading to high-performance final policies. Remarkably, our method achieves zero-shot sim-to-real transfer. Our experimental results indicate that SATA demonstrates remarkable compliance and safety, even in challenging environments such as soft/slippery terrain or narrow passages, and under significant external disturbances, highlighting its potential for practical deployments in human-centric and safety-critical scenarios.
AllGaits: Learning All Quadruped Gaits and Transitions
Nov 07, 2024



We present a framework for learning a single policy capable of producing all quadruped gaits and transitions. The framework consists of a policy trained with deep reinforcement learning (DRL) to modulate the parameters of a system of abstract oscillators (i.e. Central Pattern Generator), whose output is mapped to joint commands through a pattern formation layer that sets the gait style, i.e. body height, swing foot ground clearance height, and foot offset. Different gaits are formed by changing the coupling between different oscillators, which can be instantaneously selected at any velocity by a user. With this framework, we systematically investigate which gait should be used at which velocity, and when gait transitions should occur from a Cost of Transport (COT), i.e. energy-efficiency, point of view. Additionally, we note how gait style changes as a function of locomotion speed for each gait to keep the most energy-efficient locomotion. While the currently most popular gait (trot) does not result in the lowest COT, we find that considering different co-dependent metrics such as mean base velocity and joint acceleration result in different `optimal' gaits than those that minimize COT. We deploy our controller in various hardware experiments, showing all 9 typical quadruped animal gaits, and demonstrate generalizability to unseen gaits during training, and robustness to leg failures. Video results can be found at https://youtu.be/OLoWSX_R868.
Online Optimization of Central Pattern Generators for Quadruped Locomotion
Oct 21, 2024



Typical legged locomotion controllers are designed or trained offline. This is in contrast to many animals, which are able to locomote at birth, and rapidly improve their locomotion skills with few real-world interactions. Such motor control is possible through oscillatory neural networks located in the spinal cord of vertebrates, known as Central Pattern Generators (CPGs). Models of the CPG have been widely used to generate locomotion skills in robotics, but can require extensive hand-tuning or offline optimization of inter-connected parameters with genetic algorithms. In this paper, we present a framework for the \textit{online} optimization of the CPG parameters through Bayesian Optimization. We show that our framework can rapidly optimize and adapt to varying velocity commands and changes in the terrain, for example to varying coefficients of friction, terrain slope angles, and added mass payloads placed on the robot. We study the effects of sensory feedback on the CPG, and find that both force feedback in the phase equations, as well as posture control (Virtual Model Control) are both beneficial for robot stability and energy efficiency. In hardware experiments on the Unitree Go1, we show rapid optimization (in under 3 minutes) and adaptation of energy-efficient gaits to varying target velocities in a variety of scenarios: varying coefficients of friction, added payloads up to 15 kg, and variable slopes up to 10 degrees. See demo at: https://youtu.be/4qq5leCI2AI
Dynamic Object Catching with Quadruped Robot Front Legs
Oct 10, 2024

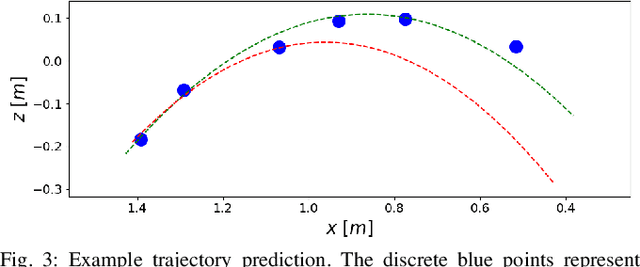
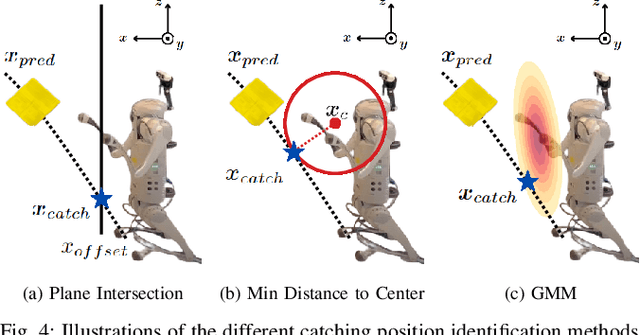
This paper presents a framework for dynamic object catching using a quadruped robot's front legs while it stands on its rear legs. The system integrates computer vision, trajectory prediction, and leg control to enable the quadruped to visually detect, track, and successfully catch a thrown object using an onboard camera. Leveraging a fine-tuned YOLOv8 model for object detection and a regression-based trajectory prediction module, the quadruped adapts its front leg positions iteratively to anticipate and intercept the object. The catching maneuver involves identifying the optimal catching position, controlling the front legs with Cartesian PD control, and closing the legs together at the right moment. We propose and validate three different methods for selecting the optimal catching position: 1) intersecting the predicted trajectory with a vertical plane, 2) selecting the point on the predicted trajectory with the minimal distance to the center of the robot's legs in their nominal position, and 3) selecting the point on the predicted trajectory with the highest likelihood on a Gaussian Mixture Model (GMM) modelling the robot's reachable space. Experimental results demonstrate robust catching capabilities across various scenarios, with the GMM method achieving the best performance, leading to an 80% catching success rate. A video demonstration of the system in action can be found at https://youtu.be/sm7RdxRfIYg .
Learning Human-Robot Handshaking Preferences for Quadruped Robots
Jun 28, 2024
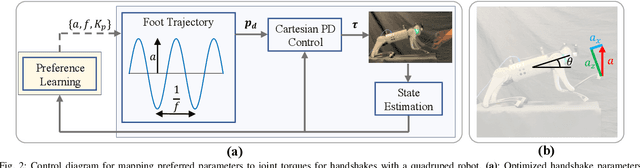


Quadruped robots are showing impressive abilities to navigate the real world. If they are to become more integrated into society, social trust in interactions with humans will become increasingly important. Additionally, robots will need to be adaptable to different humans based on individual preferences. In this work, we study the social interaction task of learning optimal handshakes for quadruped robots based on user preferences. While maintaining balance on three legs, we parameterize handshakes with a Central Pattern Generator consisting of an amplitude, frequency, stiffness, and duration. Through 10 binary choices between handshakes, we learn a belief model to fit individual preferences for 25 different subjects. Our results show that this is an effective strategy, with 76% of users feeling happy with their identified optimal handshake parameters, and 20% feeling neutral. Moreover, compared with random and test handshakes, the optimized handshakes have significantly decreased errors in amplitude and frequency, lower Dynamic Time Warping scores, and improved energy efficiency, all of which indicate robot synchronization to the user's preferences. Video results can be found at https://youtu.be/elvPv8mq1KM .
Learning-based Hierarchical Control: Emulating the Central Nervous System for Bio-Inspired Legged Robot Locomotion
Apr 27, 2024



Animals possess a remarkable ability to navigate challenging terrains, achieved through the interplay of various pathways between the brain, central pattern generators (CPGs) in the spinal cord, and musculoskeletal system. Traditional bioinspired control frameworks often rely on a singular control policy that models both higher (supraspinal) and spinal cord functions. In this work, we build upon our previous research by introducing two distinct neural networks: one tasked with modulating the frequency and amplitude of CPGs to generate the basic locomotor rhythm (referred to as the spinal policy, SCP), and the other responsible for receiving environmental perception data and directly modulating the rhythmic output from the SCP to execute precise movements on challenging terrains (referred to as the descending modulation policy). This division of labor more closely mimics the hierarchical locomotor control systems observed in legged animals, thereby enhancing the robot's ability to navigate various uneven surfaces, including steps, high obstacles, and terrains with gaps. Additionally, we investigate the impact of sensorimotor delays within our framework, validating several biological assumptions about animal locomotion systems. Specifically, we demonstrate that spinal circuits play a crucial role in generating the basic locomotor rhythm, while descending pathways are essential for enabling appropriate gait modifications to accommodate uneven terrain. Notably, our findings also reveal that the multi-layered control inherent in animals exhibits remarkable robustness against time delays. Through these investigations, this paper contributes to a deeper understanding of the fundamental principles of interplay between spinal and supraspinal mechanisms in biological locomotion. It also supports the development of locomotion controllers in parallel to biological structures which are ...
Quadruped-Frog: Rapid Online Optimization of Continuous Quadruped Jumping
Mar 11, 2024



Legged robots are becoming increasingly agile in exhibiting dynamic behaviors such as running and jumping. Usually, such behaviors are either optimized and engineered offline (i.e. the behavior is designed for before it is needed), either through model-based trajectory optimization, or through deep learning-based methods involving millions of timesteps of simulation interactions. Notably, such offline-designed locomotion controllers cannot perfectly model the true dynamics of the system, such as the motor dynamics. In contrast, in this paper, we consider a quadruped jumping task that we rapidly optimize online. We design foot force profiles parameterized by only a few parameters which we optimize for directly on hardware with Bayesian Optimization. The force profiles are tracked at the joint level, and added to Cartesian PD impedance control and Virtual Model Control to stabilize the jumping motions. After optimization, which takes only a handful of jumps, we show that this control architecture is capable of diverse and omnidirectional jumps including forward, lateral, and twist (turning) jumps, even on uneven terrain, enabling the Unitree Go1 quadruped to jump 0.5 m high, 0.5 m forward, and jump-turn over 2 rad. Video results can be found at https://youtu.be/SvfVNQ90k_w.
ManyQuadrupeds: Learning a Single Locomotion Policy for Diverse Quadruped Robots
Oct 16, 2023



Learning a locomotion policy for quadruped robots has traditionally been constrained to specific robot morphology, mass, and size. The learning process must usually be repeated for every new robot, where hyperparameters and reward function weights must be re-tuned to maximize performance for each new system. Alternatively, attempting to train a single policy to accommodate different robot sizes, while maintaining the same degrees of freedom (DoF) and morphology, requires either complex learning frameworks, or mass, inertia, and dimension randomization, which leads to prolonged training periods. In our study, we show that drawing inspiration from animal motor control allows us to effectively train a single locomotion policy capable of controlling a diverse range of quadruped robots. These differences encompass a variable number of DoFs, (i.e. 12 or 16 joints), three distinct morphologies, a broad mass range spanning from 2 kg to 200 kg, and nominal standing heights ranging from 16 cm to 100 cm. Our policy modulates a representation of the Central Pattern Generator (CPG) in the spinal cord, effectively coordinating both frequencies and amplitudes of the CPG to produce rhythmic output (Rhythm Generation), which is then mapped to a Pattern Formation (PF) layer. Across different robots, the only varying component is the PF layer, which adjusts the scaling parameters for the stride height and length. Subsequently, we evaluate the sim-to-real transfer by testing the single policy on both the Unitree Go1 and A1 robots. Remarkably, we observe robust performance, even when adding a 15 kg load, equivalent to 125% of the A1 robot's nominal mass.
Identifying Important Sensory Feedback for Learning Locomotion Skills
Jun 29, 2023Robot motor skills can be learned through deep reinforcement learning (DRL) by neural networks as state-action mappings. While the selection of state observations is crucial, there has been a lack of quantitative analysis to date. Here, we present a systematic saliency analysis that quantitatively evaluates the relative importance of different feedback states for motor skills learned through DRL. Our approach can identify the most essential feedback states for locomotion skills, including balance recovery, trotting, bounding, pacing and galloping. By using only key states including joint positions, gravity vector, base linear and angular velocities, we demonstrate that a simulated quadruped robot can achieve robust performance in various test scenarios across these distinct skills. The benchmarks using task performance metrics show that locomotion skills learned with key states can achieve comparable performance to those with all states, and the task performance or learning success rate will drop significantly if key states are missing. This work provides quantitative insights into the relationship between state observations and specific types of motor skills, serving as a guideline for robot motor learning. The proposed method is applicable to differentiable state-action mapping, such as neural network based control policies, enabling the learning of a wide range of motor skills with minimal sensing dependencies.
DeepTransition: Viability Leads to the Emergence of Gait Transitions in Learning Anticipatory Quadrupedal Locomotion Skills
Jun 14, 2023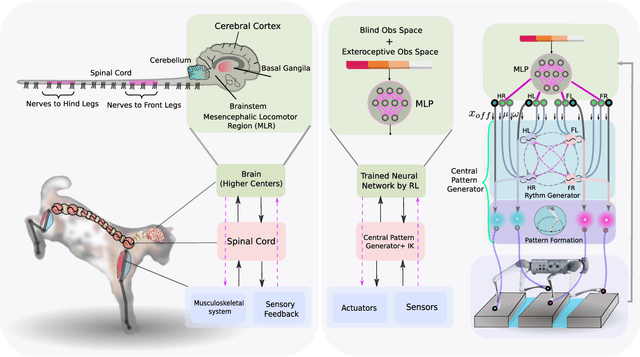
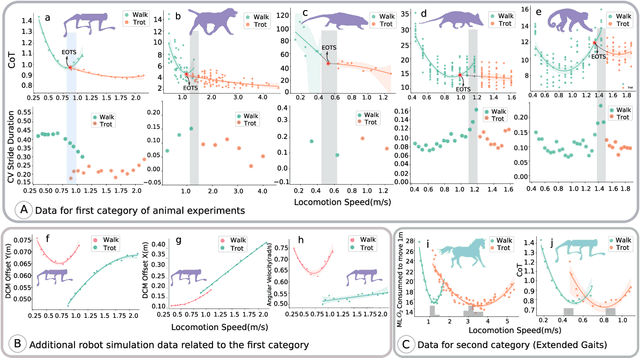

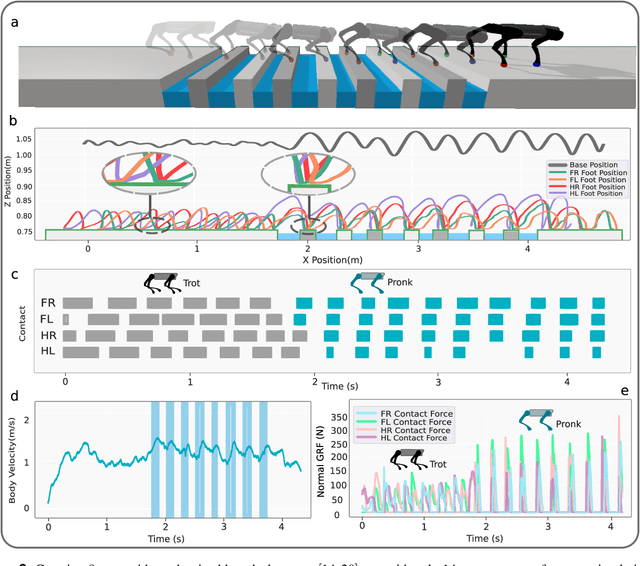
Quadruped animals seamlessly transition between gaits as they change locomotion speeds. While the most widely accepted explanation for gait transitions is energy efficiency, there is no clear consensus on the determining factor, nor on the potential effects from terrain properties. In this article, we propose that viability, i.e. the avoidance of falls, represents an important criterion for gait transitions. We investigate the emergence of gait transitions through the interaction between supraspinal drive (brain), the central pattern generator in the spinal cord, the body, and exteroceptive sensing by leveraging deep reinforcement learning and robotics tools. Consistent with quadruped animal data, we show that the walk-trot gait transition for quadruped robots on flat terrain improves both viability and energy efficiency. Furthermore, we investigate the effects of discrete terrain (i.e. crossing successive gaps) on imposing gait transitions, and find the emergence of trot-pronk transitions to avoid non-viable states. Compared with other potential criteria such as peak forces and energy efficiency, viability is the only improved factor after gait transitions on both flat and discrete gap terrains, suggesting that viability could be a primary and universal objective of gait transitions, while other criteria are secondary objectives and/or a consequence of viability. Moreover, we deploy our learned controller in sim-to-real hardware experiments and demonstrate state-of-the-art quadruped agility in challenging scenarios, where the Unitree A1 quadruped autonomously transitions gaits between trot and pronk to cross consecutive gaps of up to 30 cm (83.3 % of the body-length) at over 1.3 m/s.