 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovery of skill switching criteria for learning agile quadruped locomotion
Feb 10, 2025This paper develops a hierarchical learning and optimization framework that can learn and achieve well-coordinated multi-skill locomotion. The learned multi-skill policy can switch between skills automatically and naturally in tracking arbitrarily positioned goals and recover from failures promptly. The proposed framework is composed of a deep reinforcement learning process and an optimization process. First, the contact pattern is incorporated into the reward terms for learning different types of gaits as separate policies without the need for any other references. Then, a higher level policy is learned to generate weights for individual policies to compose multi-skill locomotion in a goal-tracking task setting. Skills are automatically and naturally switched according to the distance to the goal. The proper distances for skill switching are incorporated in reward calculation for learning the high level policy and updated by an outer optimization loop as learning progresses. We first demonstrated successful multi-skill locomotion in comprehensive tasks on a simulated Unitree A1 quadruped robot. We also deployed the learned policy in the real world showcasing trotting, bounding, galloping, and their natural transitions as the goal position changes. Moreover, the learned policy can react to unexpected failures at any time, perform prompt recovery, and resume locomotion successfully. Compared to discrete switch between single skills which failed to transition to galloping in the real world, our proposed approach achieves all the learned agile skills, with smoother and more continuous skill transitions.
Identifying Important Sensory Feedback for Learning Locomotion Skills
Jun 29, 2023Robot motor skills can be learned through deep reinforcement learning (DRL) by neural networks as state-action mappings. While the selection of state observations is crucial, there has been a lack of quantitative analysis to date. Here, we present a systematic saliency analysis that quantitatively evaluates the relative importance of different feedback states for motor skills learned through DRL. Our approach can identify the most essential feedback states for locomotion skills, including balance recovery, trotting, bounding, pacing and galloping. By using only key states including joint positions, gravity vector, base linear and angular velocities, we demonstrate that a simulated quadruped robot can achieve robust performance in various test scenarios across these distinct skills. The benchmarks using task performance metrics show that locomotion skills learned with key states can achieve comparable performance to those with all states, and the task performance or learning success rate will drop significantly if key states are missing. This work provides quantitative insights into the relationship between state observations and specific types of motor skills, serving as a guideline for robot motor learning. The proposed method is applicable to differentiable state-action mapping, such as neural network based control policies, enabling the learning of a wide range of motor skills with minimal sensing dependencies.
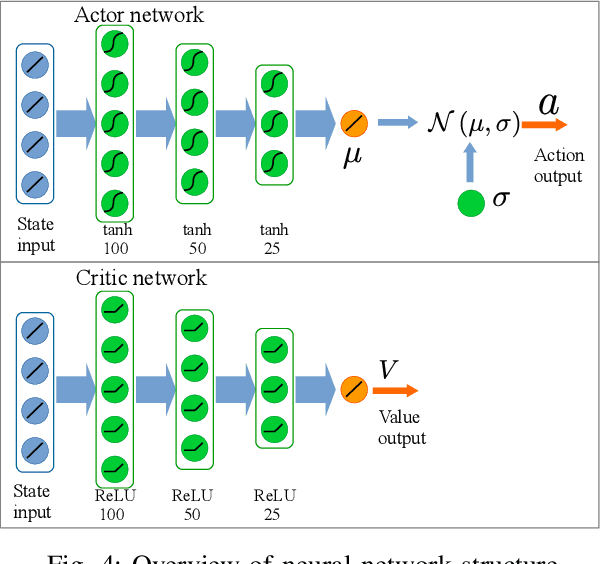
Learning Quadruped Locomotion using Bio-Inspired Neural Networks with Intrinsic Rhythmicity
May 12, 2023
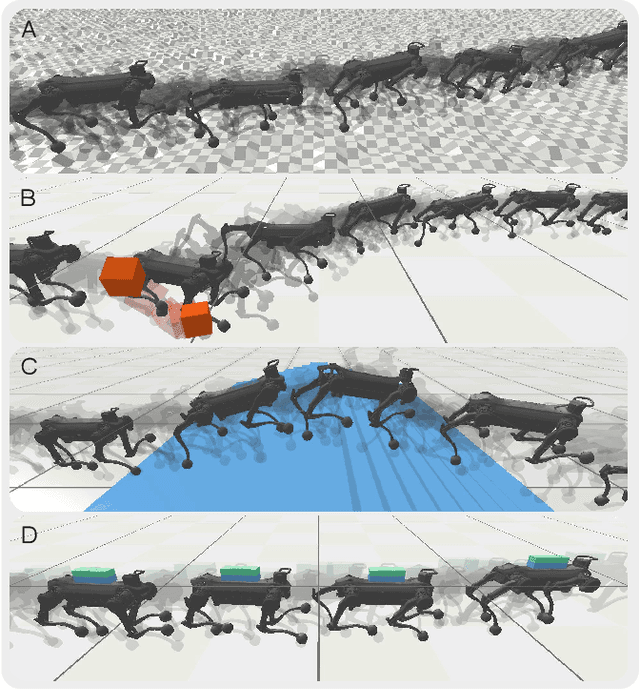
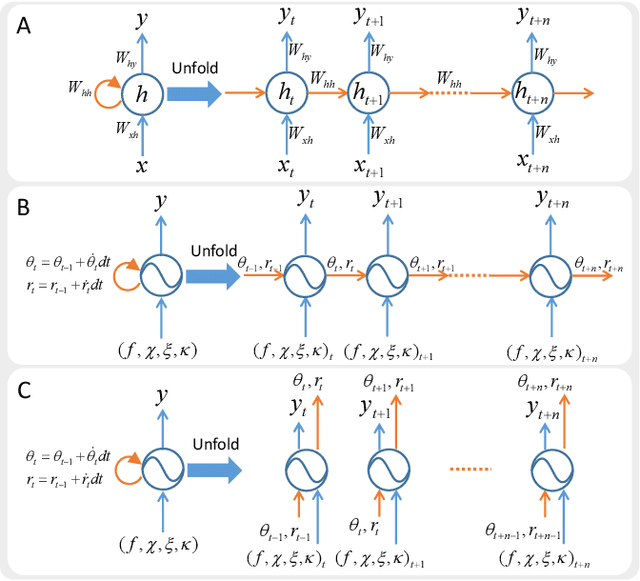
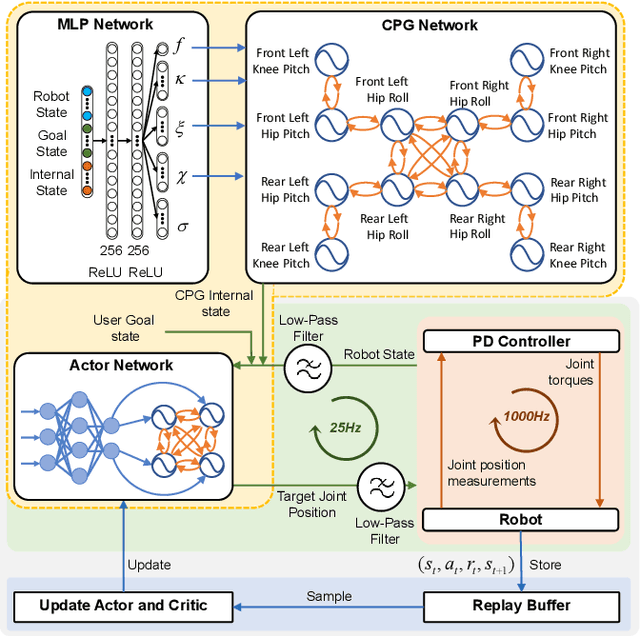
Biological studies reveal that neural circuits located at the spinal cord called central pattern generator (CPG) oscillates and generates rhythmic signals, which are the underlying mechanism responsible for rhythmic locomotion behaviors of animals. Inspired by CPG's capability to naturally generate rhythmic patterns, researchers have attempted to create mathematical models of CPG and utilize them for the locomotion of legged robots. In this paper, we propose a network architecture that incorporates CPGs for rhythmic pattern generation and a multi-layer perceptron (MLP) network for sensory feedback. We also proposed a method that reformulates CPGs into a fully-differentiable stateless network, allowing CPGs and MLP to be jointly trained with gradient-based learning. The results show that our proposed method learned agile and dynamic locomotion policies which are capable of blind traversal over uneven terrain and resist external pushes. Simulation results also show that the learned policies are capable of self-modulating step frequency and step length to adapt to the locomotion velocity.
A Multi-modal Garden Dataset and Hybrid 3D Dense Reconstruction Framework Based on Panoramic Stereo Images for a Trimming Robot
May 10, 2023
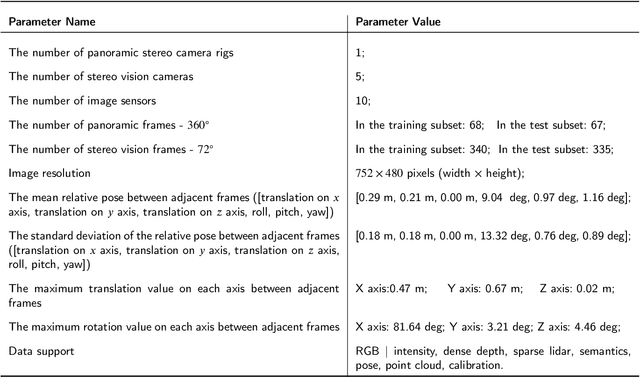
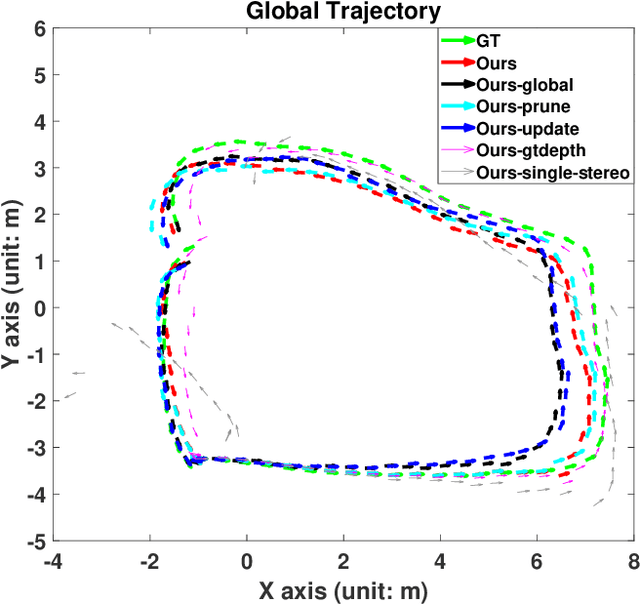
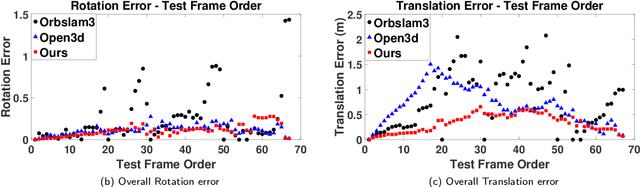
Recovering an outdoor environment's surface mesh is vital for an agricultural robot during task planning and remote visualization. Our proposed solution is based on a newly-designed panoramic stereo camera along with a hybrid novel software framework that consists of three fusion modules. The panoramic stereo camera with a pentagon shape consists of 5 stereo vision camera pairs to stream synchronized panoramic stereo images for the following three fusion modules. In the disparity fusion module, rectified stereo images produce the initial disparity maps using multiple stereo vision algorithms. Then, these initial disparity maps, along with the intensity images, are input into a disparity fusion network to produce refined disparity maps. Next, the refined disparity maps are converted into full-view point clouds or single-view point clouds for the pose fusion module. The pose fusion module adopts a two-stage global-coarse-to-local-fine strategy. In the first stage, each pair of full-view point clouds is registered by a global point cloud matching algorithm to estimate the transformation for a global pose graph's edge, which effectively implements loop closure. In the second stage, a local point cloud matching algorithm is used to match single-view point clouds in different nodes. Next, we locally refine the poses of all corresponding edges in the global pose graph using three proposed rules, thus constructing a refined pose graph. The refined pose graph is optimized to produce a global pose trajectory for volumetric fusion. In the volumetric fusion module, the global poses of all the nodes are used to integrate the single-view point clouds into the volume to produce the mesh of the whole garden. The proposed framework and its three fusion modules are tested on a real outdoor garden dataset to show the superiority of the performance.
A General Mobile Manipulator Automation Framework for Flexible Manufacturing in Hostile Industrial Environments
Feb 09, 2023
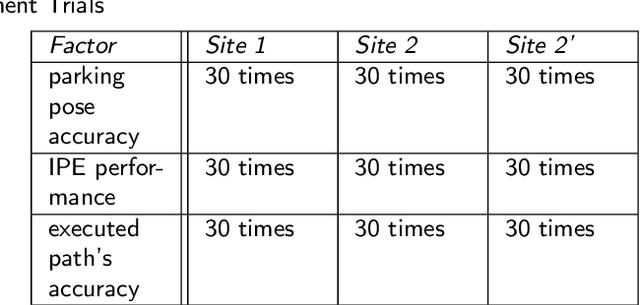

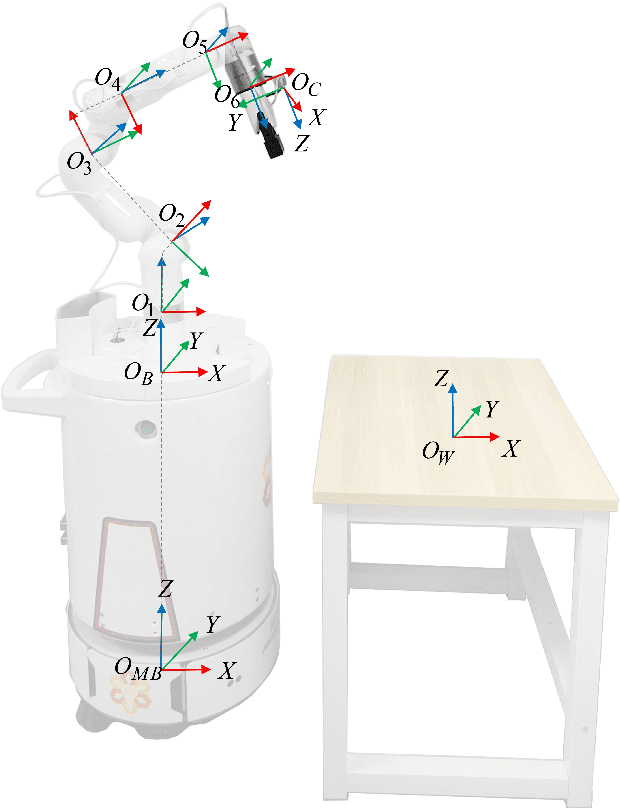
To enable a mobile manipulator to perform human tasks from a single teaching demonstration is vital to flexible manufacturing. We call our proposed method MMPA (Mobile Manipulator Process Automation with One-shot Teaching). Currently, there is no effective and robust MMPA framework which is not influenced by harsh industrial environments and the mobile base's parking precision. The proposed MMPA framework consists of two stages: collecting data (mobile base's location, environment information, end-effector's path) in the teaching stage for robot learning; letting the end-effector repeat the nearly same path as the reference path in the world frame to reproduce the work in the automation stage. More specifically, in the automation stage, the robot navigates to the specified location without the need of a precise parking. Then, based on colored point cloud registration, the proposed IPE (Iterative Pose Estimation by Eye & Hand) algorithm could estimate the accurate 6D relative parking pose of the robot arm base without the need of any marker. Finally, the robot could learn the error compensation from the parking pose's bias to modify the end-effector's path to make it repeat a nearly same path in the world coordinate system as recorded in the teaching stage. Hundreds of trials have been conducted with a real mobile manipulator to show the superior robustness of the system and the accuracy of the process automation regardless of the harsh industrial conditions and parking precision. For the released code, please contact marketing@amigaga.com
Multi-expert learning of adaptive legged locomotion
Dec 10, 2020Achieving versatile robot locomotion requires motor skills which can adapt to previously unseen situations. We propose a Multi-Expert Learning Architecture (MELA) that learns to generate adaptive skills from a group of representative expert skills. During training, MELA is first initialised by a distinct set of pre-trained experts, each in a separate deep neural network (DNN). Then by learning the combination of these DNNs using a Gating Neural Network (GNN), MELA can acquire more specialised experts and transitional skills across various locomotion modes. During runtime, MELA constantly blends multiple DNNs and dynamically synthesises a new DNN to produce adaptive behaviours in response to changing situations. This approach leverages the advantages of trained expert skills and the fast online synthesis of adaptive policies to generate responsive motor skills during the changing tasks. Using a unified MELA framework, we demonstrated successful multi-skill locomotion on a real quadruped robot that performed coherent trotting, steering, and fall recovery autonomously, and showed the merit of multi-expert learning generating behaviours which can adapt to unseen scenarios.
Learning natural locomotion behaviors for humanoid robots using human knowledge
May 20, 2020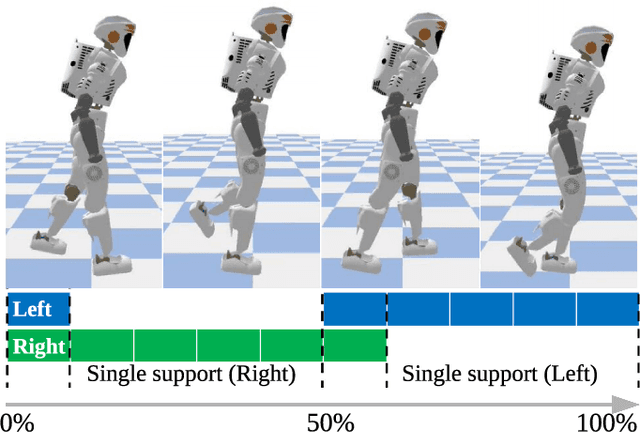
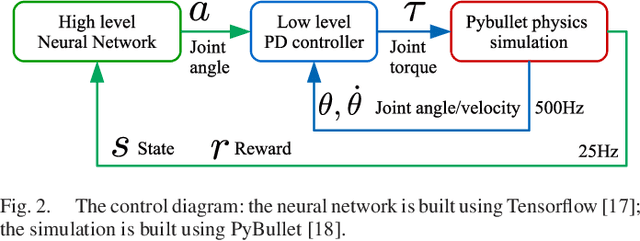
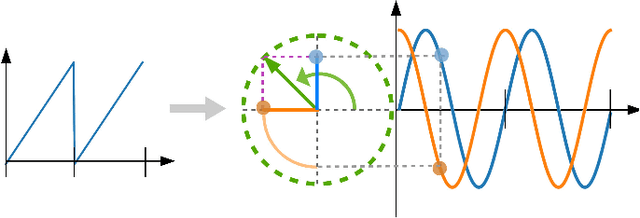
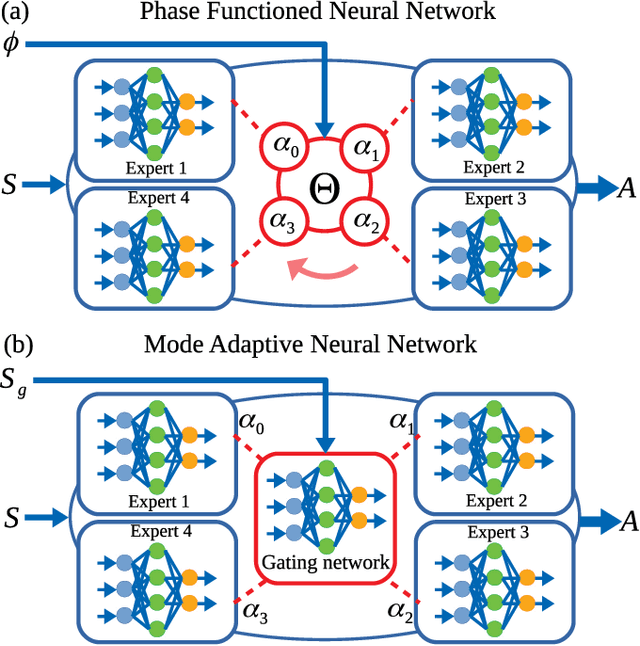
This paper presents a new learning framework that leverages the knowledge from imitation learning, deep reinforcement learning, and control theories to achieve human-style locomotion that is natural, dynamic, and robust for humanoids. We proposed novel approaches to introduce human bias, i.e. motion capture data and a special Multi-Expert network structure. We used the Multi-Expert network structure to smoothly blend behavioral features, and used the augmented reward design for the task and imitation rewards. Our reward design is composable, tunable, and explainable by using fundamental concepts from conventional humanoid control. We rigorously validated and benchmarked the learning framework which consistently produced robust locomotion behaviors in various test scenarios. Further, we demonstrated the capability of learning robust and versatile policies in the presence of disturbances, such as terrain irregularities and external pushes.
Reaching, Grasping and Re-grasping: Learning Multimode Grasping Skills
Feb 28, 2020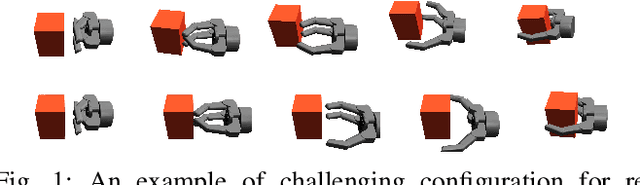
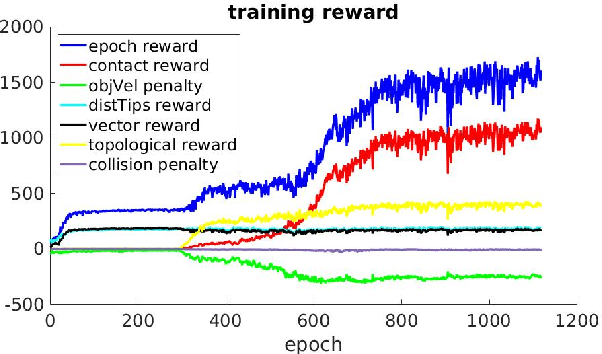
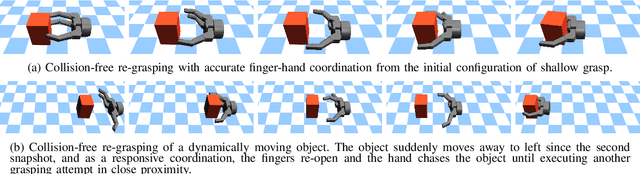
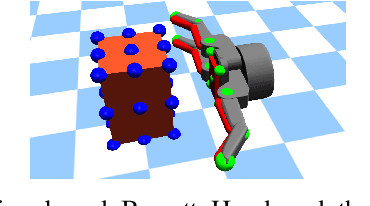
The ability to adapt to uncertainties, recover from failures, and coordinate between hand and fingers are essential sensorimotor skills for fully autonomous robotic grasping. In this paper, we aim to study a unified feedback control policy for generating the finger actions and the motion of hand to accomplish seamlessly coordinated tasks of reaching, grasping and re-grasping. We proposed a set of quantified metrics for task-orientated rewards to guide the policy exploration, and we analyzed and demonstrated the effectiveness of each reward term. To acquire a robust re-grasping motion, we deployed different initial states in training to experience failures that the robot would encounter during grasping due to inaccurate perception or disturbances. The performance of learned policy is evaluated on three different tasks: grasping a static target, grasping a dynamic target, and re-grasping. The quality of learned grasping policy was evaluated based on success rates in different scenarios and the recovery time from failures. The results indicate that the learned policy is able to achieve stable grasps of a static or moving object. Moreover, the policy can adapt to new environmental changes on the fly and execute collision-free re-grasp after a failed attempt within a short recovery time even in difficult configurations.
Learning Pregrasp Manipulation of Objects from Ungraspable Poses
Feb 15, 2020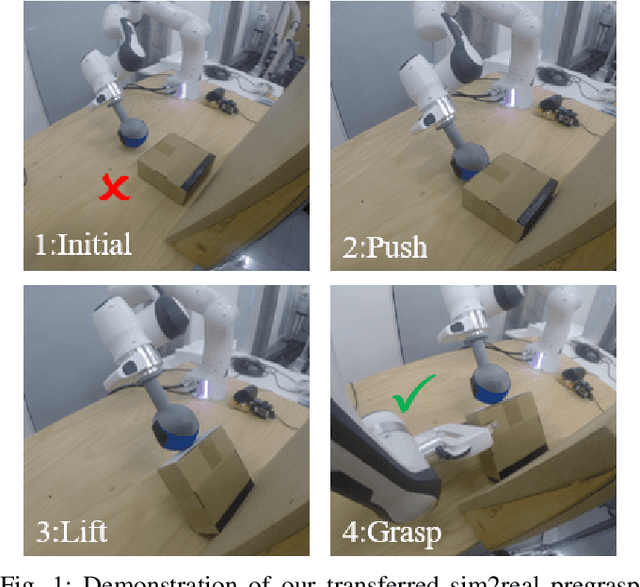
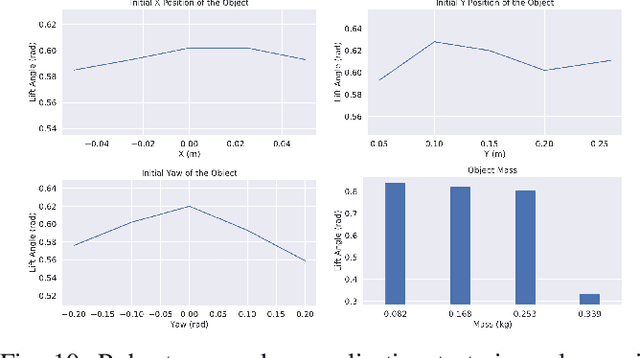


In robotic grasping, objects are often occluded in ungraspable configurations such that no pregrasp pose can be found, eg large flat boxes on the table that can only be grasped from the side. Inspired by humans' bimanual manipulation, eg one hand to lift up things and the other to grasp, we address this type of problems by introducing pregrasp manipulation - push and lift actions. We propose a model-free Deep Reinforcement Learning framework to train control policies that utilize visual information and proprioceptive states of the robot to autonomously discover robust pregrasp manipulation. The robot arm learns to first push the object towards a support surface and establishes a pivot to lift up one side of the object, thus creating a clearance between the object and the table for possible grasping solutions. Furthermore, we show the effectiveness of our proposed learning framework in training robust pregrasp policies that can directly transfer from simulation to real hardware through suitable design of training procedures, state, and action space. Lastly, we evaluate the effectiveness and the generalisation ability of the learned policies in real-world experiments, and demonstrate pregrasp manipulation of objects with various size, shape, weight, and surface friction.
Learning Whole-body Motor Skills for Humanoids
Feb 07, 2020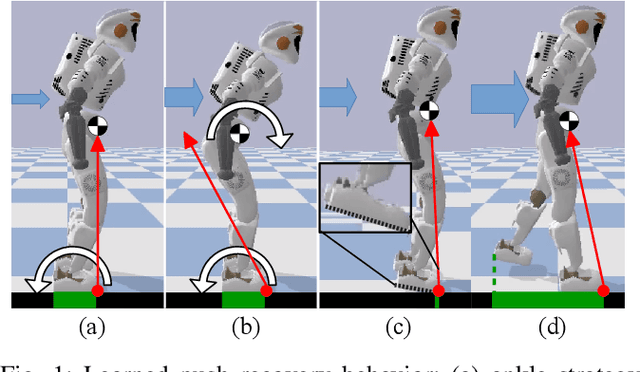

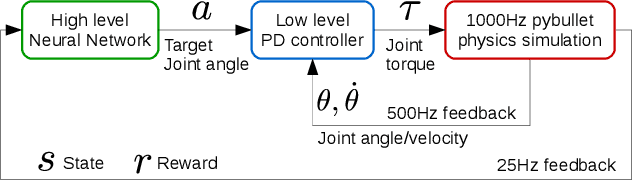
This paper presents a hierarchical framework for Deep Reinforcement Learning that acquires motor skills for a variety of push recovery and balancing behaviors, i.e., ankle, hip, foot tilting, and stepping strategies. The policy is trained in a physics simulator with realistic setting of robot model and low-level impedance control that are easy to transfer the learned skills to real robots. The advantage over traditional methods is the integration of high-level planner and feedback control all in one single coherent policy network, which is generic for learning versatile balancing and recovery motions against unknown perturbations at arbitrary locations (e.g., legs, torso). Furthermore, the proposed framework allows the policy to be learned quickly by many state-of-the-art learning algorithms. By comparing our learned results to studies of preprogrammed, special-purpose controllers in the literature, self-learned skills are comparable in terms of disturbance rejection but with additional advantages of producing a wide range of adaptive, versatile and robust behaviors.