 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReference Free Platform Adaptive Locomotion for Quadrupedal Robots using a Dynamics Conditioned Policy
May 21, 2025This article presents Platform Adaptive Locomotion (PAL), a unified control method for quadrupedal robots with different morphologies and dynamics. We leverage deep reinforcement learning to train a single locomotion policy on procedurally generated robots. The policy maps proprioceptive robot state information and base velocity commands into desired joint actuation targets, which are conditioned using a latent embedding of the temporally local system dynamics. We explore two conditioning strategies - one using a GRU-based dynamics encoder and another using a morphology-based property estimator - and show that morphology-aware conditioning outperforms temporal dynamics encoding regarding velocity task tracking for our hardware test on ANYmal C. Our results demonstrate that both approaches achieve robust zero-shot transfer across multiple unseen simulated quadrupeds. Furthermore, we demonstrate the need for careful robot reference modelling during training, enabling us to reduce the velocity tracking error by up to 30% compared to the baseline method. Despite PAL not surpassing the best-performing reference-free controller in all cases, our analysis uncovers critical design choices and informs improvements to the state of the art.
Adaptive Manipulation using Behavior Trees
Jun 20, 2024Many manipulation tasks use instances of a set of common motions, such as a twisting motion for tightening or loosening a valve. However, different instances of the same motion often require different environmental parameters (e.g. force/torque level), and thus different manipulation strategies to successfully complete; for example, grasping a valve handle from the side rather than head-on to increase applied torque. Humans can intuitively adapt their manipulation strategy to best suit such problems, but representing and implementing such behaviors for robots remains an open question. We present a behavior tree-based approach for adaptive manipulation, wherein the robot can reactively select from and switch between a discrete set of manipulation strategies during task execution. Furthermore, our approach allows the robot to learn from past attempts to optimize performance, for example learning the optimal strategy for different task instances. Our approach also allows the robot to preempt task failure and either change to a more feasible strategy or safely exit the task before catastrophic failure occurs. We propose a simple behavior tree design for general adaptive robot behavior and apply it in the context of industrial manipulation. The adaptive behavior outperformed all baseline behaviors that only used a single manipulation strategy, markedly reducing the number of attempts and overall time taken to complete the example tasks. Our results demonstrate potential for improved robustness and efficiency in task completion, reducing dependency on human supervision and intervention.
Gaitor: Learning a Unified Representation Across Gaits for Real-World Quadruped Locomotion
May 29, 2024



The current state-of-the-art in quadruped locomotion is able to produce robust motion for terrain traversal but requires the segmentation of a desired robot trajectory into a discrete set of locomotion skills such as trot and crawl. In contrast, in this work we demonstrate the feasibility of learning a single, unified representation for quadruped locomotion enabling continuous blending between gait types and characteristics. We present Gaitor, which learns a disentangled representation of locomotion skills, thereby sharing information common to all gait types seen during training. The structure emerging in the learnt representation is interpretable in that it is found to encode phase correlations between the different gait types. These can be leveraged to produce continuous gait transitions. In addition, foot swing characteristics are disentangled and directly addressable. Together with a rudimentary terrain encoding and a learned planner operating in this structured latent representation, Gaitor is able to take motion commands including desired gait type and characteristics from a user while reacting to uneven terrain. We evaluate Gaitor in both simulated and real-world settings on the ANYmal C platform. To the best of our knowledge, this is the first work learning such a unified and interpretable latent representation for multiple gaits, resulting in on-demand continuous blending between different locomotion modes on a real quadruped robot.
Towards Agility: A Momentum Aware Trajectory Optimisation Framework using Full-Centroidal Dynamics & Implicit Inverse Kinematics
Oct 09, 2023



Online planning and execution of acrobatic maneuvers pose significant challenges in legged locomotion. Their underlying combinatorial nature, along with the current hardware's limitations constitute the main obstacles in unlocking the true potential of legged-robots. This letter tries to expose the intricacies of these optimal control problems in a tangible way, directly applicable to the creation of more efficient online trajectory optimisation frameworks. By analysing the fundamental principles that shape the behaviour of the system, the dynamics themselves can be exploited to surpass its hardware limitations. More specifically, a trajectory optimisation formulation is proposed that exploits the system's high-order nonlinearities, such as the nonholonomy of the angular momentum, and phase-space symmetries in order to produce feasible high-acceleration maneuvers. By leveraging the full-centroidal dynamics of the quadruped ANYmal C and directly optimising its footholds and contact forces, the framework is capable of producing efficient motion plans with low computational overhead. The feasibility of the produced trajectories is ensured by taking into account the configuration-dependent inertial properties of the robot during the planning process, while its robustness is increased by supplying the full analytic derivatives & hessians to the solver. Finally, a significant portion of the discussion is centred around the deployment of the proposed framework on the ANYmal C platform, while its true capabilities are demonstrated through real-world experiments, with the successful execution of high-acceleration motion scenarios like the squat-jump.
R-LGP: A Reachability-guided Logic-geometric Programming Framework for Optimal Task and Motion Planning on Mobile Manipulators
Oct 04, 2023



This paper presents an optimization-based solution to task and motion planning (TAMP) on mobile manipulators. Logic-geometric programming (LGP) has shown promising capabilities for optimally dealing with hybrid TAMP problems that involve abstract and geometric constraints. However, LGP does not scale well to high-dimensional systems (e.g. mobile manipulators) and can suffer from obstacle avoidance issues. In this work, we extend LGP with a sampling-based reachability graph to enable solving optimal TAMP on high-DoF mobile manipulators. The proposed reachability graph can incorporate environmental information (obstacles) to provide the planner with sufficient geometric constraints. This reachability-aware heuristic efficiently prunes infeasible sequences of actions in the continuous domain, hence, it reduces replanning by securing feasibility at the final full trajectory optimization. Our framework proves to be time-efficient in computing optimal and collision-free solutions, while outperforming the current state of the art on metrics of success rate, planning time, path length and number of steps. We validate our framework on the physical Toyota HSR robot and report comparisons on a series of mobile manipulation tasks of increasing difficulty.
Perceptive Locomotion through Whole-Body MPC and Optimal Region Selection
May 15, 2023


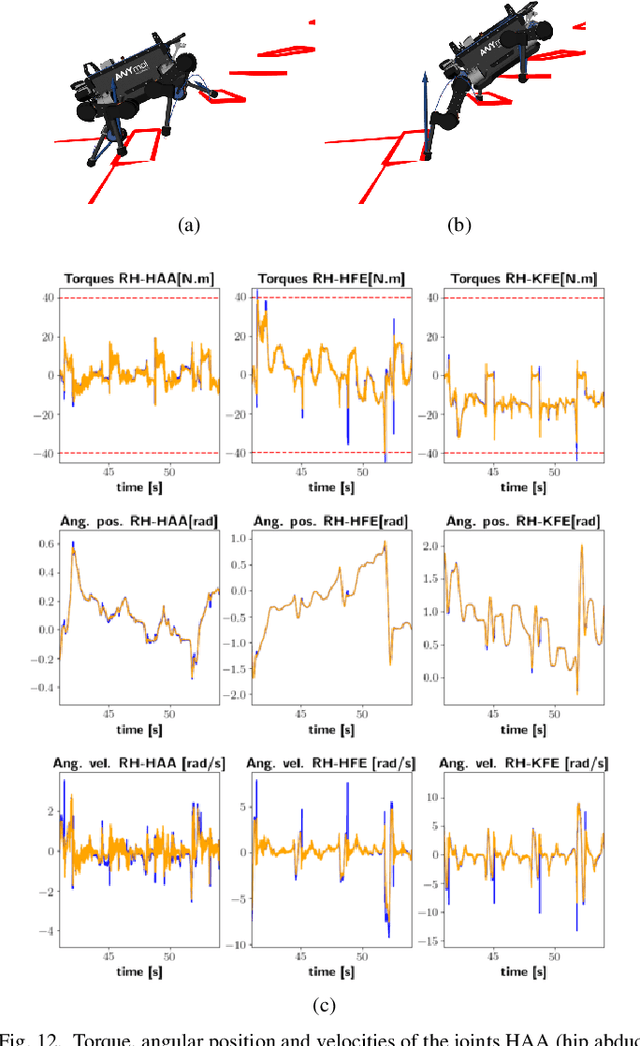
Real-time synthesis of legged locomotion maneuvers in challenging industrial settings is still an open problem, requiring simultaneous determination of footsteps locations several steps ahead while generating whole-body motions close to the robot's limits. State estimation and perception errors impose the practical constraint of fast re-planning motions in a model predictive control (MPC) framework. We first observe that the computational limitation of perceptive locomotion pipelines lies in the combinatorics of contact surface selection. Re-planning contact locations on selected surfaces can be accomplished at MPC frequencies (50-100 Hz). Then, whole-body motion generation typically follows a reference trajectory for the robot base to facilitate convergence. We propose removing this constraint to robustly address unforeseen events such as contact slipping, by leveraging a state-of-the-art whole-body MPC (Croccodyl). Our contributions are integrated into a complete framework for perceptive locomotion, validated under diverse terrain conditions, and demonstrated in challenging trials that push the robot's actuation limits, as well as in the ICRA 2023 quadruped challenge simulation.
Roll-Drop: accounting for observation noise with a single parameter
Apr 25, 2023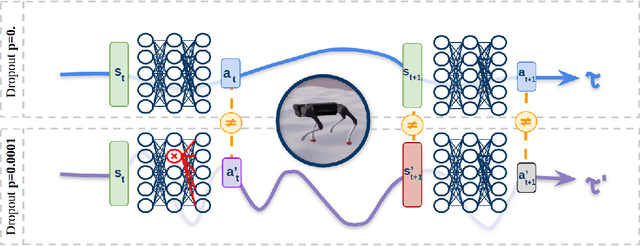

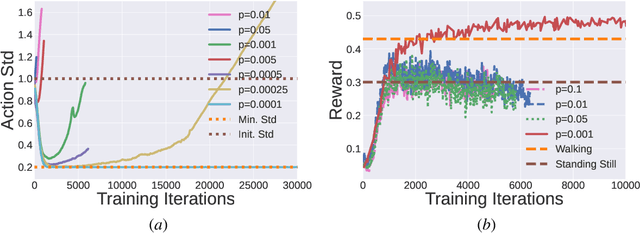
This paper proposes a simple strategy for sim-to-real in Deep-Reinforcement Learning (DRL) -- called Roll-Drop -- that uses dropout during simulation to account for observation noise during deployment without explicitly modelling its distribution for each state. DRL is a promising approach to control robots for highly dynamic and feedback-based manoeuvres, and accurate simulators are crucial to providing cheap and abundant data to learn the desired behaviour. Nevertheless, the simulated data are noiseless and generally show a distributional shift that challenges the deployment on real machines where sensor readings are affected by noise. The standard solution is modelling the latter and injecting it during training; while this requires a thorough system identification, Roll-Drop enhances the robustness to sensor noise by tuning only a single parameter. We demonstrate an 80% success rate when up to 25% noise is injected in the observations, with twice higher robustness than the baselines. We deploy the controller trained in simulation on a Unitree A1 platform and assess this improved robustness on the physical system.
Multi-Agent Chance-Constrained Stochastic Shortest Path with Application to Risk-Aware Intelligent Intersection
Oct 03, 2022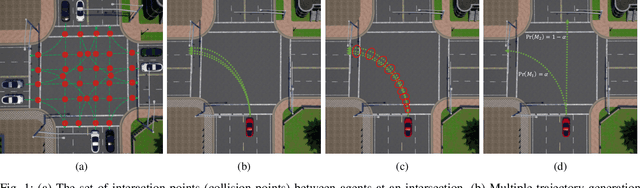
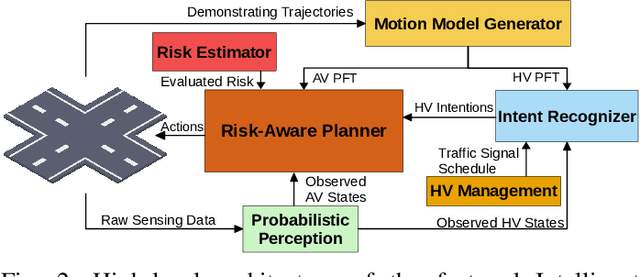


In transportation networks, where traffic lights have traditionally been used for vehicle coordination, intersections act as natural bottlenecks. A formidable challenge for existing automated intersections lies in detecting and reasoning about uncertainty from the operating environment and human-driven vehicles. In this paper, we propose a risk-aware intelligent intersection system for autonomous vehicles (AVs) as well as human-driven vehicles (HVs). We cast the problem as a novel class of Multi-agent Chance-Constrained Stochastic Shortest Path (MCC-SSP) problems and devise an exact Integer Linear Programming (ILP) formulation that is scalable in the number of agents' interaction points (e.g., potential collision points at the intersection). In particular, when the number of agents within an interaction point is small, which is often the case in intersections, the ILP has a polynomial number of variables and constraints. To further improve the running time performance, we show that the collision risk computation can be performed offline. Additionally, a trajectory optimization workflow is provided to generate risk-aware trajectories for any given intersection. The proposed framework is implemented in CARLA simulator and evaluated under a fully autonomous intersection with AVs only as well as in a hybrid setup with a signalized intersection for HVs and an intelligent scheme for AVs. As verified via simulations, the featured approach improves intersection's efficiency by up to $200\%$ while also conforming to the specified tunable risk threshold.
Learning and Deploying Robust Locomotion Policies with Minimal Dynamics Randomization
Sep 26, 2022
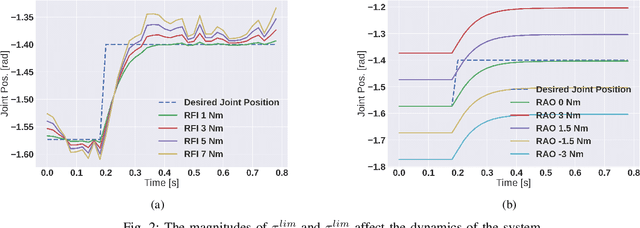

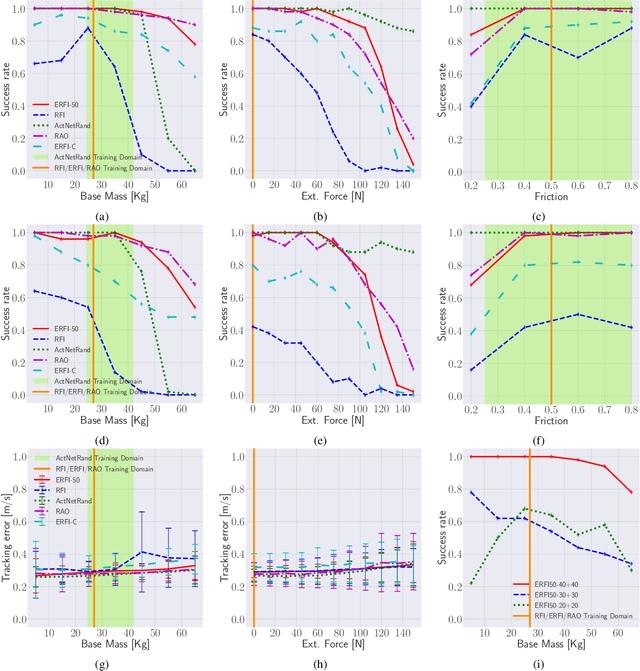
Training deep reinforcement learning (DRL) locomotion policies often requires massive amounts of data to converge to the desired behavior. In this regard, simulators provide a cheap and abundant source. For successful sim-to-real transfer, exhaustively engineered approaches such as system identification, dynamics randomization, and domain adaptation are generally employed. As an alternative, we investigate a simple strategy of random force injection (RFI) to perturb system dynamics during training. We show that the application of random forces enables us to emulate dynamics randomization.This allows us to obtain locomotion policies that are robust to variations in system dynamics. We further extend RFI, referred to as extended random force injection (ERFI), by introducing an episodic actuation offset. We demonstrate that ERFI provides additional robustness for variations in system mass offering on average a 61% improved performance over RFI. We also show that ERFI is sufficient to perform a successful sim-to-real transfer on two different quadrupedal platforms, ANYmal C and Unitree A1, even for perceptive locomotion over uneven terrain in outdoor environments.
VAE-Loco: Versatile Quadruped Locomotion by Learning a Disentangled Gait Representation
May 02, 2022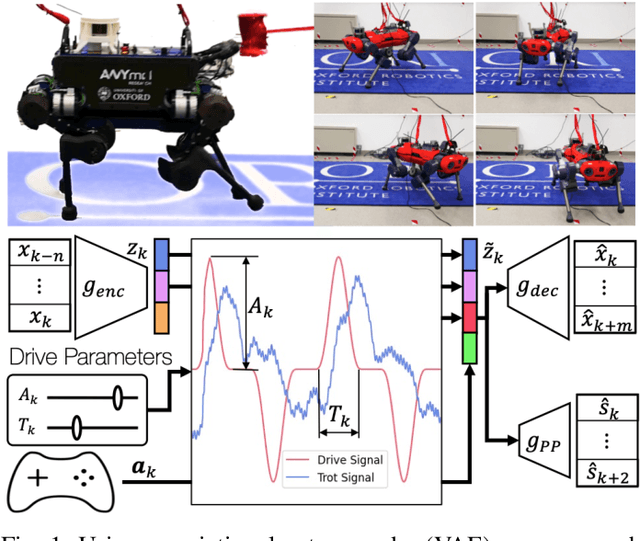
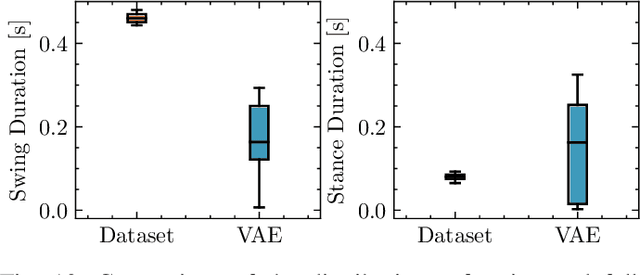
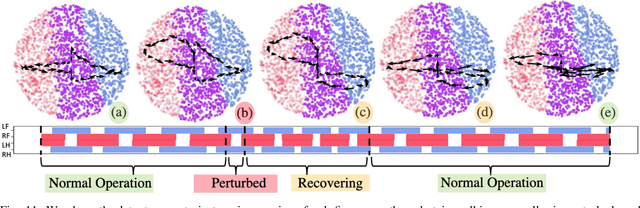
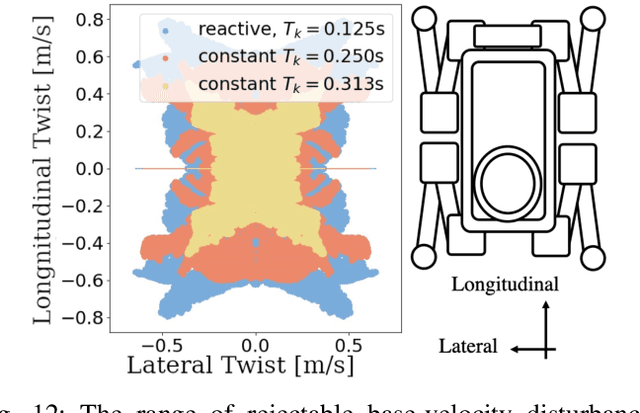
Quadruped locomotion is rapidly maturing to a degree where robots now routinely traverse a variety of unstructured terrains. However, while gaits can be varied typically by selecting from a range of pre-computed styles, current planners are unable to vary key gait parameters continuously while the robot is in motion. The synthesis, on-the-fly, of gaits with unexpected operational characteristics or even the blending of dynamic manoeuvres lies beyond the capabilities of the current state-of-the-art. In this work we address this limitation by learning a latent space capturing the key stance phases constituting a particular gait. This is achieved via a generative model trained on a single trot style, which encourages disentanglement such that application of a drive signal to a single dimension of the latent state induces holistic plans synthesising a continuous variety of trot styles. We demonstrate that specific properties of the drive signal map directly to gait parameters such as cadence, footstep height and full stance duration. Due to the nature of our approach these synthesised gaits are continuously variable online during robot operation and robustly capture a richness of movement significantly exceeding the relatively narrow behaviour seen during training. In addition, the use of a generative model facilitates the detection and mitigation of disturbances to provide a versatile and robust planning framework. We evaluate our approach on two versions of the real ANYmal quadruped robots and demonstrate that our method achieves a continuous blend of dynamic trot styles whilst being robust and reactive to external perturbations.