 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollaborative Trajectory Prediction via Late Fusion
Apr 24, 2026Predicting future trajectories of surrounding traffic agents is critical for safe autonomous navigation and collision avoidance. Despite all advances in the trajectory forecasting realm, the prediction models remains vulnerable to uncertainty caused by occlusions, limited sensing range, and perception errors. Collaborative vehicle-to-vehicle (V2V) approaches help reduce this uncertainty by sharing complementary information. Existing collaborative trajectory prediction methods typically fuse feature maps at the perception stage to construct a holistic scene view. Further this holistic representation is decoded into the future trajectories. Such design incurs substantial communication overhead due to the exchange of high-dimensional feature representations and often assumes idealized bandwidth and synchronization, limiting practical deployment. We address these limitations by shifting collaboration from perception to the prediction module and introducing a late-fusion framework for shared forecasts. The framework is model-agnostic and treats collaborating vehicles as independent asynchronous agents. We evaluate the approach on the OPV2V, V2V4Real, and DeepAccident datasets, comparing individual and collaborative forecasting. Across all datasets, late fusion consistently reduces miss rate and improves trajectory success rate ($\mathrm{TSR}_{0.5}$), defined as the fraction of ground-truth agents with final displacement error below 0.5 m. On the real-world V2V4Real dataset, collaborative prediction improves the success rate by $1.69\%$ and $1.22\%$ for both intelligent vehicles, respectively, compared with individual forecasting.
EagleVision: A Multi-Task Benchmark for Cross-Domain Perception in High-Speed Autonomous Racing
Apr 13, 2026High-speed autonomous racing presents extreme perception challenges, including large relative velocities and substantial domain shifts from conventional urban-driving datasets. Existing benchmarks do not adequately capture these high-dynamic conditions. We introduce EagleVision, a unified LiDAR-based multi-task benchmark for 3D detection and trajectory prediction in high-speed racing, providing newly annotated 3D bounding boxes for the Indy Autonomous Challenge dataset (14,893 frames) and the A2RL Real competition dataset (1,163 frames), together with 12,000 simulator-generated annotated frames, all standardized under a common evaluation protocol. Using a dataset-centric transfer framework, we quantify cross-domain generalization across urban, simulator, and real racing domains. Urban pretraining improves detection over scratch training (NDS 0.72 vs. 0.69), while intermediate pretraining on real racing data achieves the best transfer to A2RL (NDS 0.726), outperforming simulator-only adaptation. For trajectory prediction, Indy-trained models surpass in-domain A2RL training on A2RL test sequences (FDE 0.947 vs. 1.250), highlighting the role of motion-distribution coverage in cross-domain forecasting. EagleVision enables systematic study of perception generalization under extreme high-speed dynamics. The dataset and benchmark are publicly available at https://avlab.io/EagleVision
Visual Prompt Based Reasoning for Offroad Mapping using Multimodal LLMs
Apr 06, 2026Traditional approaches to off-road autonomy rely on separate models for terrain classification, height estimation, and quantifying slip or slope conditions. Utilizing several models requires training each component separately, having task specific datasets, and fine-tuning. In this work, we present a zero-shot approach leveraging SAM2 for environment segmentation and a vision-language model (VLM) to reason about drivable areas. Our approach involves passing to the VLM both the original image and the segmented image annotated with numeric labels for each mask. The VLM is then prompted to identify which regions, represented by these numeric labels, are drivable. Combined with planning and control modules, this unified framework eliminates the need for explicit terrain-specific models and relies instead on the inherent reasoning capabilities of the VLM. Our approach surpasses state-of-the-art trainable models on high resolution segmentation datasets and enables full stack navigation in our Isaac Sim offroad environment.
Towards Cognitive Defect Analysis in Active Infrared Thermography with Vision-Text Cues
Mar 11, 2026Active infrared thermography (AIRT) is currently witnessing a surge of artificial intelligence (AI) methodologies being deployed for automated subsurface defect analysis of high performance carbon fiber-reinforced polymers (CFRP). Deploying AI-based AIRT methodologies for inspecting CFRPs requires the creation of time consuming and expensive datasets of CFRP inspection sequences to train neural networks. To address this challenge, this work introduces a novel language-guided framework for cognitive defect analysis in CFRPs using AIRT and vision-language models (VLMs). Unlike conventional learning-based approaches, the proposed framework does not require developing training datasets for extensive training of defect detectors, instead it relies solely on pretrained multimodal VLM encoders coupled with a lightweight adapter to enable generative zero-shot understanding and localization of subsurface defects. By leveraging pretrained multimodal encoders, the proposed system enables generative zero-shot understanding of thermographic patterns and automatic detection of subsurface defects. Given the domain gap between thermographic data and natural images used to train VLMs, an AIRT-VLM Adapter is proposed to enhance the visibility of defects while aligning the thermographic domain with the learned representations of VLMs. The proposed framework is validated using three representative VLMs; specifically, GroundingDINO, Qwen-VL-Chat, and CogVLM. Validation is performed on 25 CFRP inspection sequences with impacts introduced at different energy levels, reflecting realistic defects encountered in industrial scenarios. Experimental results demonstrate that the AIRT-VLM adapter achieves signal-to-noise ratio (SNR) gains exceeding 10 dB compared with conventional thermographic dimensionality-reduction methods, while enabling zero-shot defect detection with intersection-over-union values reaching 70%.
Sandpiper: Orchestrated AI-Annotation for Educational Discourse at Scale
Mar 09, 2026Digital educational environments are expanding toward complex AI and human discourse, providing researchers with an abundance of data that offers deep insights into learning and instructional processes. However, traditional qualitative analysis remains a labor-intensive bottleneck, severely limiting the scale at which this research can be conducted. We present Sandpiper, a mixed-initiative system designed to serve as a bridge between high-volume conversational data and human qualitative expertise. By tightly coupling interactive researcher dashboards with agentic Large Language Model (LLM) engines, the platform enables scalable analysis without sacrificing methodological rigor. Sandpiper addresses critical barriers to AI adoption in education by implementing context-aware, automated de-identification workflows supported by secure, university-housed infrastructure to ensure data privacy. Furthermore, the system employs schema-constrained orchestration to eliminate LLM hallucinations and enforces strict adherence to qualitative codebooks. An integrated evaluations engine allows for the continuous benchmarking of AI performance against human labels, fostering an iterative approach to model refinement and validation. We propose a user study to evaluate the system's efficacy in improving research efficiency, inter-rater reliability, and researcher trust in AI-assisted qualitative workflows.
Utility-Preserving De-Identification for Math Tutoring: Investigating Numeric Ambiguity in the MathEd-PII Benchmark Dataset
Feb 18, 2026Large-scale sharing of dialogue-based data is instrumental for advancing the science of teaching and learning, yet rigorous de-identification remains a major barrier. In mathematics tutoring transcripts, numeric expressions frequently resemble structured identifiers (e.g., dates or IDs), leading generic Personally Identifiable Information (PII) detection systems to over-redact core instructional content and reduce dataset utility. This work asks how PII can be detected in math tutoring transcripts while preserving their educational utility. To address this challenge, we investigate the "numeric ambiguity" problem and introduce MathEd-PII, the first benchmark dataset for PII detection in math tutoring dialogues, created through a human-in-the-loop LLM workflow that audits upstream redactions and generates privacy-preserving surrogates. The dataset contains 1,000 tutoring sessions (115,620 messages; 769,628 tokens) with validated PII annotations. Using a density-based segmentation method, we show that false PII redactions are disproportionately concentrated in math-dense regions, confirming numeric ambiguity as a key failure mode. We then compare four detection strategies: a Presidio baseline and LLM-based approaches with basic, math-aware, and segment-aware prompting. Math-aware prompting substantially improves performance over the baseline (F1: 0.821 vs. 0.379) while reducing numeric false positives, demonstrating that de-identification must incorporate domain context to preserve analytic utility. This work provides both a new benchmark and evidence that utility-preserving de-identification for tutoring data requires domain-aware modeling.
Red grape detection with accelerated artificial neural networks in the FPGA's programmable logic
Jul 03, 2025Robots usually slow down for canning to detect objects while moving. Additionally, the robot's camera is configured with a low framerate to track the velocity of the detection algorithms. This would be constrained while executing tasks and exploring, making robots increase the task execution time. AMD has developed the Vitis-AI framework to deploy detection algorithms into FPGAs. However, this tool does not fully use the FPGAs' PL. In this work, we use the FINN architecture to deploy three ANNs, MobileNet v1 with 4-bit quantisation, CNV with 2-bit quantisation, and CNV with 1-bit quantisation (BNN), inside an FPGA's PL. The models were trained on the RG2C dataset. This is a self-acquired dataset released in open access. MobileNet v1 performed better, reaching a success rate of 98 % and an inference speed of 6611 FPS. In this work, we proved that we can use FPGAs to speed up ANNs and make them suitable for attention mechanisms.
Collaborative Last-Mile Delivery: A Multi-Platform Vehicle Routing Problem With En-route Charging
May 29, 2025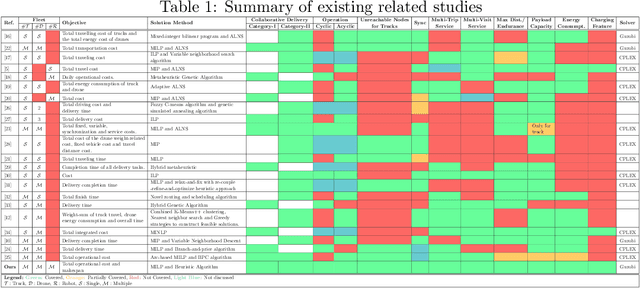
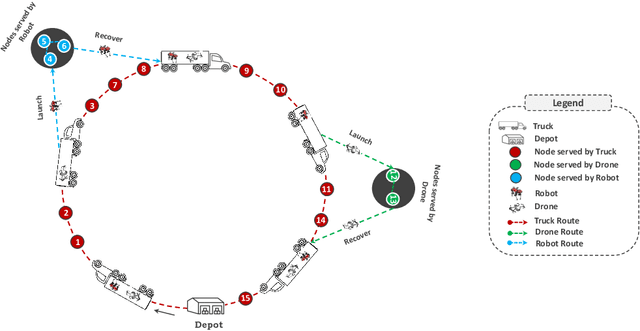


The rapid growth of e-commerce and the increasing demand for timely, cost-effective last-mile delivery have increased interest in collaborative logistics. This research introduces a novel collaborative synchronized multi-platform vehicle routing problem with drones and robots (VRP-DR), where a fleet of $\mathcal{M}$ trucks, $\mathcal{N}$ drones and $\mathcal{K}$ robots, cooperatively delivers parcels. Trucks serve as mobile platforms, enabling the launching, retrieving, and en-route charging of drones and robots, thereby addressing critical limitations such as restricted payload capacities, limited range, and battery constraints. The VRP-DR incorporates five realistic features: (1) multi-visit service per trip, (2) multi-trip operations, (3) flexible docking, allowing returns to the same or different trucks (4) cyclic and acyclic operations, enabling return to the same or different nodes; and (5) en-route charging, enabling drones and robots to recharge while being transported on the truck, maximizing operational efficiency by utilizing idle transit time. The VRP-DR is formulated as a mixed-integer linear program (MILP) to minimize both operational costs and makespan. To overcome the computational challenges of solving large-scale instances, a scalable heuristic algorithm, FINDER (Flexible INtegrated Delivery with Energy Recharge), is developed, to provide efficient, near-optimal solutions. Numerical experiments across various instance sizes evaluate the performance of the MILP and heuristic approaches in terms of solution quality and computation time. The results demonstrate significant time savings of the combined delivery mode over the truck-only mode and substantial cost reductions from enabling multi-visits. The study also provides insights into the effects of en-route charging, docking flexibility, drone count, speed, and payload capacity on system performance.
Towards Accurate State Estimation: Kalman Filter Incorporating Motion Dynamics for 3D Multi-Object Tracking
May 12, 2025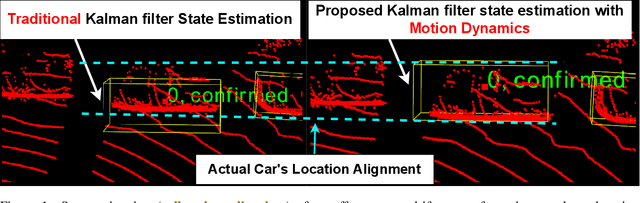
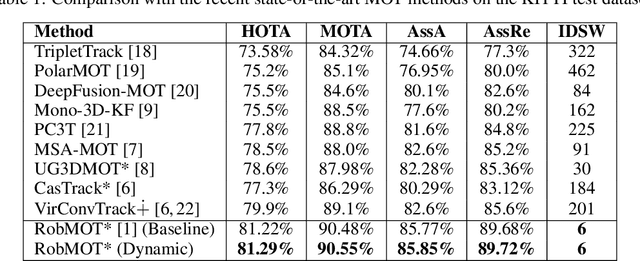
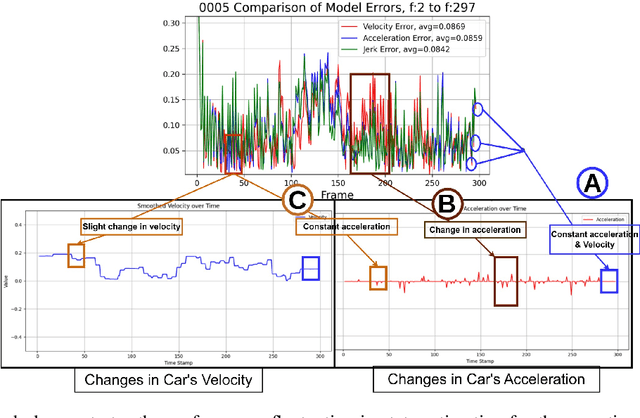
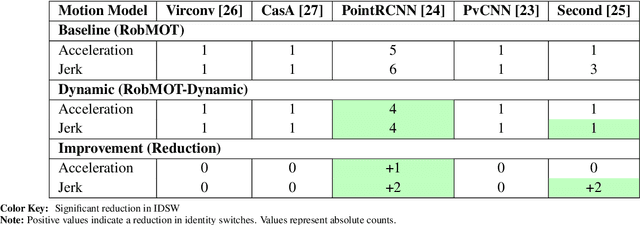
This work addresses the critical lack of precision in state estimation in the Kalman filter for 3D multi-object tracking (MOT) and the ongoing challenge of selecting the appropriate motion model. Existing literature commonly relies on constant motion models for estimating the states of objects, neglecting the complex motion dynamics unique to each object. Consequently, trajectory division and imprecise object localization arise, especially under occlusion conditions. The core of these challenges lies in the limitations of the current Kalman filter formulation, which fails to account for the variability of motion dynamics as objects navigate their environments. This work introduces a novel formulation of the Kalman filter that incorporates motion dynamics, allowing the motion model to adaptively adjust according to changes in the object's movement. The proposed Kalman filter substantially improves state estimation, localization, and trajectory prediction compared to the traditional Kalman filter. This is reflected in tracking performance that surpasses recent benchmarks on the KITTI and Waymo Open Datasets, with margins of 0.56\% and 0.81\% in higher order tracking accuracy (HOTA) and multi-object tracking accuracy (MOTA), respectively. Furthermore, the proposed Kalman filter consistently outperforms the baseline across various detectors. Additionally, it shows an enhanced capability in managing long occlusions compared to the baseline Kalman filter, achieving margins of 1.22\% in higher order tracking accuracy (HOTA) and 1.55\% in multi-object tracking accuracy (MOTA) on the KITTI dataset. The formulation's efficiency is evident, with an additional processing time of only approximately 0.078 ms per frame, ensuring its applicability in real-time applications.
snnTrans-DHZ: A Lightweight Spiking Neural Network Architecture for Underwater Image Dehazing
Apr 13, 2025Underwater image dehazing is critical for vision-based marine operations because light scattering and absorption can severely reduce visibility. This paper introduces snnTrans-DHZ, a lightweight Spiking Neural Network (SNN) specifically designed for underwater dehazing. By leveraging the temporal dynamics of SNNs, snnTrans-DHZ efficiently processes time-dependent raw image sequences while maintaining low power consumption. Static underwater images are first converted into time-dependent sequences by repeatedly inputting the same image over user-defined timesteps. These RGB sequences are then transformed into LAB color space representations and processed concurrently. The architecture features three key modules: (i) a K estimator that extracts features from multiple color space representations; (ii) a Background Light Estimator that jointly infers the background light component from the RGB-LAB images; and (iii) a soft image reconstruction module that produces haze-free, visibility-enhanced outputs. The snnTrans-DHZ model is directly trained using a surrogate gradient-based backpropagation through time (BPTT) strategy alongside a novel combined loss function. Evaluated on the UIEB benchmark, snnTrans-DHZ achieves a PSNR of 21.68 dB and an SSIM of 0.8795, and on the EUVP dataset, it yields a PSNR of 23.46 dB and an SSIM of 0.8439. With only 0.5670 million network parameters, and requiring just 7.42 GSOPs and 0.0151 J of energy, the algorithm significantly outperforms existing state-of-the-art methods in terms of efficiency. These features make snnTrans-DHZ highly suitable for deployment in underwater robotics, marine exploration, and environmental monitoring.