 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQSLM: A Performance- and Memory-aware Quantization Framework with Tiered Search Strategy for Spike-driven Language Models
Jan 02, 2026Large Language Models (LLMs) have been emerging as prominent AI models for solving many natural language tasks due to their high performance (e.g., accuracy) and capabilities in generating high-quality responses to the given inputs. However, their large computational cost, huge memory footprints, and high processing power/energy make it challenging for their embedded deployments. Amid several tinyLLMs, recent works have proposed spike-driven language models (SLMs) for significantly reducing the processing power/energy of LLMs. However, their memory footprints still remain too large for low-cost and resource-constrained embedded devices. Manual quantization approach may effectively compress SLM memory footprints, but it requires a huge design time and compute power to find the quantization setting for each network, hence making this approach not-scalable for handling different networks, performance requirements, and memory budgets. To bridge this gap, we propose QSLM, a novel framework that performs automated quantization for compressing pre-trained SLMs, while meeting the performance and memory constraints. To achieve this, QSLM first identifies the hierarchy of the given network architecture and the sensitivity of network layers under quantization, then employs a tiered quantization strategy (e.g., global-, block-, and module-level quantization) while leveraging a multi-objective performance-and-memory trade-off function to select the final quantization setting. Experimental results indicate that our QSLM reduces memory footprint by up to 86.5%, reduces power consumption by up to 20%, maintains high performance across different tasks (i.e., by up to 84.4% accuracy of sentiment classification on the SST-2 dataset and perplexity score of 23.2 for text generation on the WikiText-2 dataset) close to the original non-quantized model while meeting the performance and memory constraints.
SwitchMT: An Adaptive Context Switching Methodology for Scalable Multi-Task Learning in Intelligent Autonomous Agents
Apr 18, 2025The ability to train intelligent autonomous agents (such as mobile robots) on multiple tasks is crucial for adapting to dynamic real-world environments. However, state-of-the-art reinforcement learning (RL) methods only excel in single-task settings, and still struggle to generalize across multiple tasks due to task interference. Moreover, real-world environments also demand the agents to have data stream processing capabilities. Toward this, a state-of-the-art work employs Spiking Neural Networks (SNNs) to improve multi-task learning by exploiting temporal information in data stream, while enabling lowpower/energy event-based operations. However, it relies on fixed context/task-switching intervals during its training, hence limiting the scalability and effectiveness of multi-task learning. To address these limitations, we propose SwitchMT, a novel adaptive task-switching methodology for RL-based multi-task learning in autonomous agents. Specifically, SwitchMT employs the following key ideas: (1) a Deep Spiking Q-Network with active dendrites and dueling structure, that utilizes task-specific context signals to create specialized sub-networks; and (2) an adaptive task-switching policy that leverages both rewards and internal dynamics of the network parameters. Experimental results demonstrate that SwitchMT achieves superior performance in multi-task learning compared to state-of-the-art methods. It achieves competitive scores in multiple Atari games (i.e., Pong: -8.8, Breakout: 5.6, and Enduro: 355.2) compared to the state-of-the-art, showing its better generalized learning capability. These results highlight the effectiveness of our SwitchMT methodology in addressing task interference while enabling multi-task learning automation through adaptive task switching, thereby paving the way for more efficient generalist agents with scalable multi-task learning capabilities.
Enabling Efficient Processing of Spiking Neural Networks with On-Chip Learning on Commodity Neuromorphic Processors for Edge AI Systems
Apr 01, 2025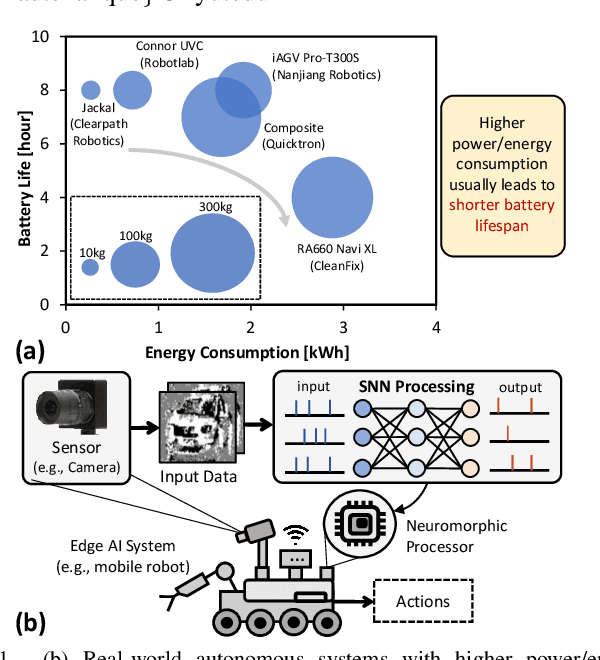


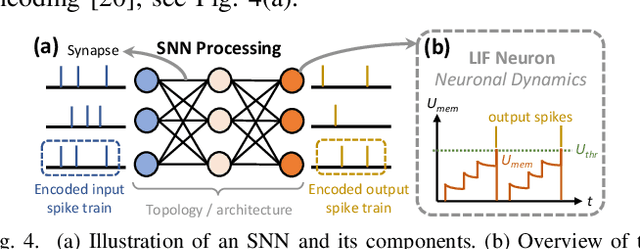
The rising demand for energy-efficient edge AI systems (e.g., mobile agents/robots) has increased the interest in neuromorphic computing, since it offers ultra-low power/energy AI computation through spiking neural network (SNN) algorithms on neuromorphic processors. However, their efficient implementation strategy has not been comprehensively studied, hence limiting SNN deployments for edge AI systems. Toward this, we propose a design methodology to enable efficient SNN processing on commodity neuromorphic processors. To do this, we first study the key characteristics of targeted neuromorphic hardware (e.g., memory and compute budgets), and leverage this information to perform compatibility analysis for network selection. Afterward, we employ a mapping strategy for efficient SNN implementation on the targeted processor. Furthermore, we incorporate an efficient on-chip learning mechanism to update the systems' knowledge for adapting to new input classes and dynamic environments. The experimental results show that the proposed methodology leads the system to achieve low latency of inference (i.e., less than 50ms for image classification, less than 200ms for real-time object detection in video streaming, and less than 1ms in keyword recognition) and low latency of on-chip learning (i.e., less than 2ms for keyword recognition), while incurring less than 250mW of processing power and less than 15mJ of energy consumption across the respective different applications and scenarios. These results show the potential of the proposed methodology in enabling efficient edge AI systems for diverse application use-cases.
QSViT: A Methodology for Quantizing Spiking Vision Transformers
Apr 01, 2025Vision Transformer (ViT)-based models have shown state-of-the-art performance (e.g., accuracy) in vision-based AI tasks. However, realizing their capability in resource-constrained embedded AI systems is challenging due to their inherent large memory footprints and complex computations, thereby incurring high power/energy consumption. Recently, Spiking Vision Transformer (SViT)-based models have emerged as alternate low-power ViT networks. However, their large memory footprints still hinder their applicability for resource-constrained embedded AI systems. Therefore, there is a need for a methodology to compress SViT models without degrading the accuracy significantly. To address this, we propose QSViT, a novel design methodology to compress the SViT models through a systematic quantization strategy across different network layers. To do this, our QSViT employs several key steps: (1) investigating the impact of different precision levels in different network layers, (2) identifying the appropriate base quantization settings for guiding bit precision reduction, (3) performing a guided quantization strategy based on the base settings to select the appropriate quantization setting, and (4) developing an efficient quantized network based on the selected quantization setting. The experimental results demonstrate that, our QSViT methodology achieves 22.75% memory saving and 21.33% power saving, while also maintaining high accuracy within 2.1% from that of the original non-quantized SViT model on the ImageNet dataset. These results highlight the potential of QSViT methodology to pave the way toward the efficient SViT deployments on resource-constrained embedded AI systems.
MTSpark: Enabling Multi-Task Learning with Spiking Neural Networks for Generalist Agents
Dec 06, 2024



Currently, state-of-the-art RL methods excel in single-task settings, but they still struggle to generalize across multiple tasks due to catastrophic forgetting challenges, where previously learned tasks are forgotten as new tasks are introduced. This multi-task learning capability is significantly important for generalist agents, where adaptation features are highly required (e.g., autonomous robots). On the other hand, Spiking Neural Networks (SNNs) have emerged as alternative energy-efficient neural network algorithms due to their sparse spike-based operations. Toward this, we propose MTSpark, a novel methodology to enable multi-task RL using spiking networks. Specifically, MTSpark develops a Deep Spiking Q-Network (DSQN) with active dendrites and dueling structure by leveraging task-specific context signals. Specifically, each neuron computes task-dependent activations that dynamically modulate inputs, forming specialized sub-networks for each task. Moreover, this bioplausible network model also benefits from SNNs, enhancing energy efficiency and making the model suitable for hardware implementation. Experimental results show that, our MTSpark effectively learns multiple tasks with higher performance compared to the state-of-the-art. Specifically, MTSpark successfully achieves high score in three Atari games (i.e., Pong: -5.4, Breakout: 0.6, and Enduro: 371.2), reaching human-level performance (i.e., Pong: -3, Breakout: 31, and Enduro: 368), where state-of-the-art struggle to achieve. In addition, our MTSpark also shows better accuracy in image classification tasks than the state-of-the-art. These results highlight the potential of our MTSpark methodology to develop generalist agents that can learn multiple tasks by leveraging both RL and SNN concepts.
Continual Learning with Neuromorphic Computing: Theories, Methods, and Applications
Oct 11, 2024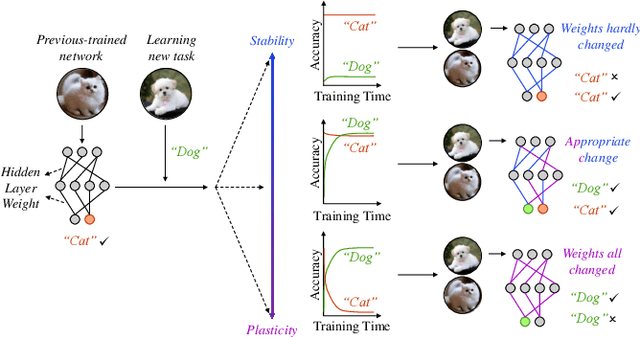

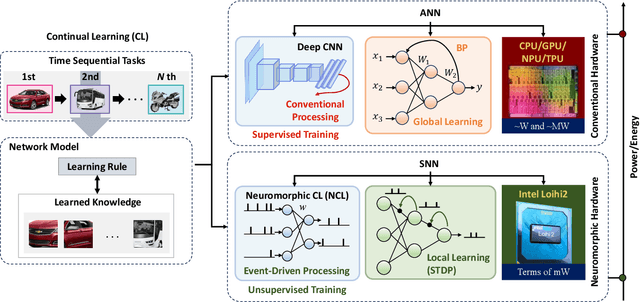
To adapt to real-world dynamics, intelligent systems need to assimilate new knowledge without catastrophic forgetting, where learning new tasks leads to a degradation in performance on old tasks. To address this, continual learning concept is proposed for enabling autonomous systems to acquire new knowledge and dynamically adapt to changing environments. Specifically, energy-efficient continual learning is needed to ensure the functionality of autonomous systems under tight compute and memory resource budgets (i.e., so-called autonomous embedded systems). Neuromorphic computing, with brain-inspired Spiking Neural Networks (SNNs), offers inherent advantages for enabling low-power/energy continual learning in autonomous embedded systems. In this paper, we comprehensively discuss the foundations and methods for enabling continual learning in neural networks, then analyze the state-of-the-art works considering SNNs. Afterward, comparative analyses of existing methods are conducted while considering crucial design factors, such as network complexity, memory, latency, and power/energy efficiency. We also explore the practical applications that can benefit from SNN-based continual learning and open challenges in real-world scenarios. In this manner, our survey provides valuable insights into the recent advancements of SNN-based continual learning for real-world application use-cases.
PENDRAM: Enabling High-Performance and Energy-Efficient Processing of Deep Neural Networks through a Generalized DRAM Data Mapping Policy
Aug 05, 2024



Convolutional Neural Networks (CNNs), a prominent type of Deep Neural Networks (DNNs), have emerged as a state-of-the-art solution for solving machine learning tasks. To improve the performance and energy efficiency of CNN inference, the employment of specialized hardware accelerators is prevalent. However, CNN accelerators still face performance- and energy-efficiency challenges due to high off-chip memory (DRAM) access latency and energy, which are especially crucial for latency- and energy-constrained embedded applications. Moreover, different DRAM architectures have different profiles of access latency and energy, thus making it challenging to optimize them for high performance and energy-efficient CNN accelerators. To address this, we present PENDRAM, a novel design space exploration methodology that enables high-performance and energy-efficient CNN acceleration through a generalized DRAM data mapping policy. Specifically, it explores the impact of different DRAM data mapping policies and DRAM architectures across different CNN partitioning and scheduling schemes on the DRAM access latency and energy, then identifies the pareto-optimal design choices. The experimental results show that our DRAM data mapping policy improves the energy-delay-product of DRAM accesses in the CNN accelerator over other mapping policies by up to 96%. In this manner, our PENDRAM methodology offers high-performance and energy-efficient CNN acceleration under any given DRAM architectures for diverse embedded AI applications.
FastSpiker: Enabling Fast Training for Spiking Neural Networks on Event-based Data through Learning Rate Enhancements for Autonomous Embedded Systems
Jul 07, 2024Autonomous embedded systems (e.g., robots) typically necessitate intelligent computation with low power/energy processing for completing their tasks. Such requirements can be fulfilled by embodied neuromorphic intelligence with spiking neural networks (SNNs) because of their high learning quality (e.g., accuracy) and sparse computation. Here, the employment of event-based data is preferred to ensure seamless connectivity between input and processing parts. However, state-of-the-art SNNs still face a long training time to achieve high accuracy, thereby incurring high energy consumption and producing a high rate of carbon emission. Toward this, we propose FastSpiker, a novel methodology that enables fast SNN training on event-based data through learning rate enhancements targeting autonomous embedded systems. In FastSpiker, we first investigate the impact of different learning rate policies and their values, then select the ones that quickly offer high accuracy. Afterward, we explore different settings for the selected learning rate policies to find the appropriate policies through a statistical-based decision. Experimental results show that our FastSpiker offers up to 10.5x faster training time and up to 88.39% lower carbon emission to achieve higher or comparable accuracy to the state-of-the-art on the event-based automotive dataset (i.e., NCARS). In this manner, our FastSpiker methodology paves the way for green and sustainable computing in realizing embodied neuromorphic intelligence for autonomous embedded systems.
HASNAS: A Hardware-Aware Spiking Neural Architecture Search Framework for Neuromorphic Compute-in-Memory Systems
Jun 30, 2024Spiking Neural Networks (SNNs) have shown capabilities for solving diverse machine learning tasks with ultra-low-power/energy computation. To further improve the performance and efficiency of SNN inference, the Compute-in-Memory (CIM) paradigm with emerging device technologies such as resistive random access memory is employed. However, most of SNN architectures are developed without considering constraints from the application and the underlying CIM hardware (e.g., memory, area, latency, and energy consumption). Moreover, most of SNN designs are derived from the Artificial Neural Networks, whose network operations are different from SNNs. These limitations hinder SNNs from reaching their full potential in accuracy and efficiency. Toward this, we propose HASNAS, a novel hardware-aware spiking neural architecture search (NAS) framework for neuromorphic CIM systems that finds an SNN that offers high accuracy under the given memory, area, latency, and energy constraints. To achieve this, HASNAS employs the following key steps: (1) optimizing SNN operations to achieve high accuracy, (2) developing an SNN architecture that facilitates an effective learning process, and (3) devising a systematic hardware-aware search algorithm to meet the constraints. The experimental results show that our HASNAS quickly finds an SNN that maintains high accuracy compared to the state-of-the-art by up to 11x speed-up, and meets the given constraints: 4x10^6 parameters of memory, 100mm^2 of area, 400ms of latency, and 120uJ energy consumption for CIFAR10 and CIFAR100; while the state-of-the-art fails to meet the constraints. In this manner, our HASNAS can enable efficient design automation for providing high-performance and energy-efficient neuromorphic CIM systems for diverse applications.
SNN4Agents: A Framework for Developing Energy-Efficient Embodied Spiking Neural Networks for Autonomous Agents
Apr 14, 2024Recent trends have shown that autonomous agents, such as Autonomous Ground Vehicles (AGVs), Unmanned Aerial Vehicles (UAVs), and mobile robots, effectively improve human productivity in solving diverse tasks. However, since these agents are typically powered by portable batteries, they require extremely low power/energy consumption to operate in a long lifespan. To solve this challenge, neuromorphic computing has emerged as a promising solution, where bio-inspired Spiking Neural Networks (SNNs) use spikes from event-based cameras or data conversion pre-processing to perform sparse computations efficiently. However, the studies of SNN deployments for autonomous agents are still at an early stage. Hence, the optimization stages for enabling efficient embodied SNN deployments for autonomous agents have not been defined systematically. Toward this, we propose a novel framework called SNN4Agents that consists of a set of optimization techniques for designing energy-efficient embodied SNNs targeting autonomous agent applications. Our SNN4Agents employs weight quantization, timestep reduction, and attention window reduction to jointly improve the energy efficiency, reduce the memory footprint, optimize the processing latency, while maintaining high accuracy. In the evaluation, we investigate use cases of event-based car recognition, and explore the trade-offs among accuracy, latency, memory, and energy consumption. The experimental results show that our proposed framework can maintain high accuracy (i.e., 84.12% accuracy) with 68.75% memory saving, 3.58x speed-up, and 4.03x energy efficiency improvement as compared to the state-of-the-art work for NCARS dataset, thereby enabling energy-efficient embodied SNN deployments for autonomous agents.