 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Learning with Neuromorphic Computing: Theories, Methods, and Applications
Oct 11, 2024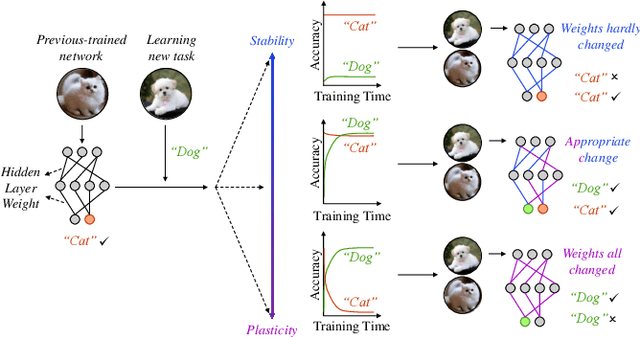
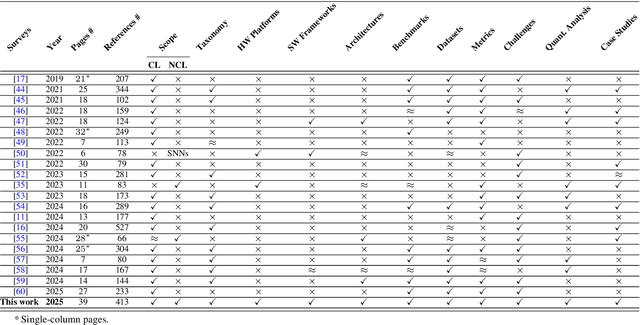

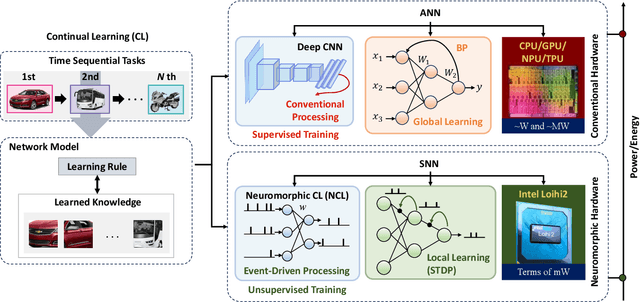
To adapt to real-world dynamics, intelligent systems need to assimilate new knowledge without catastrophic forgetting, where learning new tasks leads to a degradation in performance on old tasks. To address this, continual learning concept is proposed for enabling autonomous systems to acquire new knowledge and dynamically adapt to changing environments. Specifically, energy-efficient continual learning is needed to ensure the functionality of autonomous systems under tight compute and memory resource budgets (i.e., so-called autonomous embedded systems). Neuromorphic computing, with brain-inspired Spiking Neural Networks (SNNs), offers inherent advantages for enabling low-power/energy continual learning in autonomous embedded systems. In this paper, we comprehensively discuss the foundations and methods for enabling continual learning in neural networks, then analyze the state-of-the-art works considering SNNs. Afterward, comparative analyses of existing methods are conducted while considering crucial design factors, such as network complexity, memory, latency, and power/energy efficiency. We also explore the practical applications that can benefit from SNN-based continual learning and open challenges in real-world scenarios. In this manner, our survey provides valuable insights into the recent advancements of SNN-based continual learning for real-world application use-cases.
Scaling Model Checking for DNN Analysis via State-Space Reduction and Input Segmentation
Jul 03, 2023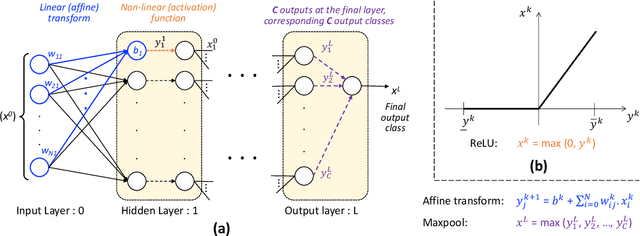
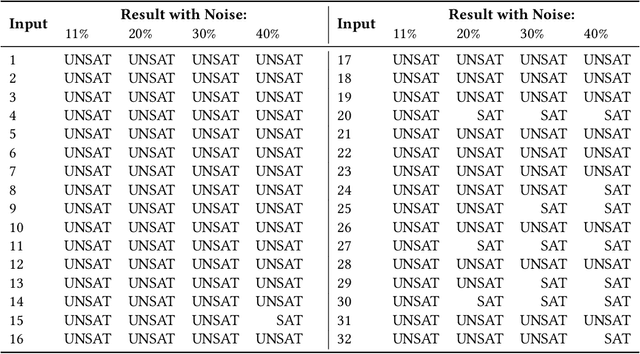
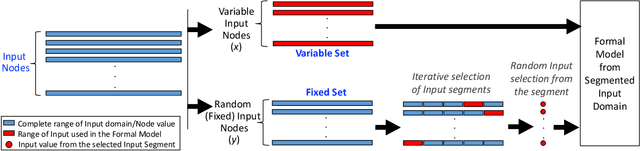
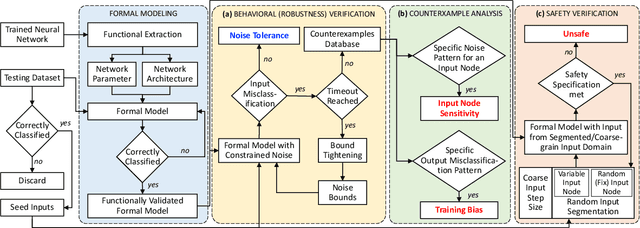
Owing to their remarkable learning capabilities and performance in real-world applications, the use of machine learning systems based on Neural Networks (NNs) has been continuously increasing. However, various case studies and empirical findings in the literature suggest that slight variations to NN inputs can lead to erroneous and undesirable NN behavior. This has led to considerable interest in their formal analysis, aiming to provide guarantees regarding a given NN's behavior. Existing frameworks provide robustness and/or safety guarantees for the trained NNs, using satisfiability solving and linear programming. We proposed FANNet, the first model checking-based framework for analyzing a broader range of NN properties. However, the state-space explosion associated with model checking entails a scalability problem, making the FANNet applicable only to small NNs. This work develops state-space reduction and input segmentation approaches, to improve the scalability and timing efficiency of formal NN analysis. Compared to the state-of-the-art FANNet, this enables our new model checking-based framework to reduce the verification's timing overhead by a factor of up to 8000, making the framework applicable to NNs even with approximately $80$ times more network parameters. This in turn allows the analysis of NN safety properties using the new framework, in addition to all the NN properties already included with FANNet. The framework is shown to be efficiently able to analyze properties of NNs trained on healthcare datasets as well as the well--acknowledged ACAS Xu NNs.
UnbiasedNets: A Dataset Diversification Framework for Robustness Bias Alleviation in Neural Networks
Mar 13, 2023Performance of trained neural network (NN) models, in terms of testing accuracy, has improved remarkably over the past several years, especially with the advent of deep learning. However, even the most accurate NNs can be biased toward a specific output classification due to the inherent bias in the available training datasets, which may propagate to the real-world implementations. This paper deals with the robustness bias, i.e., the bias exhibited by the trained NN by having a significantly large robustness to noise for a certain output class, as compared to the remaining output classes. The bias is shown to result from imbalanced datasets, i.e., the datasets where all output classes are not equally represented. Towards this, we propose the UnbiasedNets framework, which leverages K-means clustering and the NN's noise tolerance to diversify the given training dataset, even from relatively smaller datasets. This generates balanced datasets and reduces the bias within the datasets themselves. To the best of our knowledge, this is the first framework catering to the robustness bias problem in NNs. We use real-world datasets to demonstrate the efficacy of the UnbiasedNets for data diversification, in case of both binary and multi-label classifiers. The results are compared to well-known tools aimed at generating balanced datasets, and illustrate how existing works have limited success while addressing the robustness bias. In contrast, UnbiasedNets provides a notable improvement over existing works, while even reducing the robustness bias significantly in some cases, as observed by comparing the NNs trained on the diversified and original datasets.
* Springer Machine Learning 2023
BioNetExplorer: Architecture-Space Exploration of Bio-Signal Processing Deep Neural Networks for Wearables
Sep 07, 2021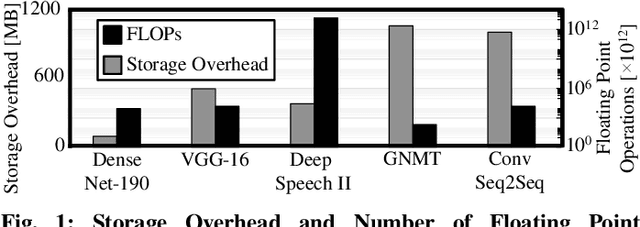
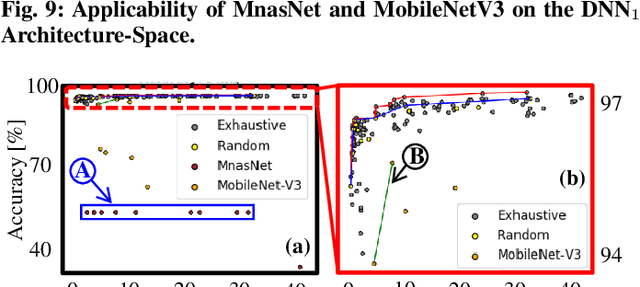
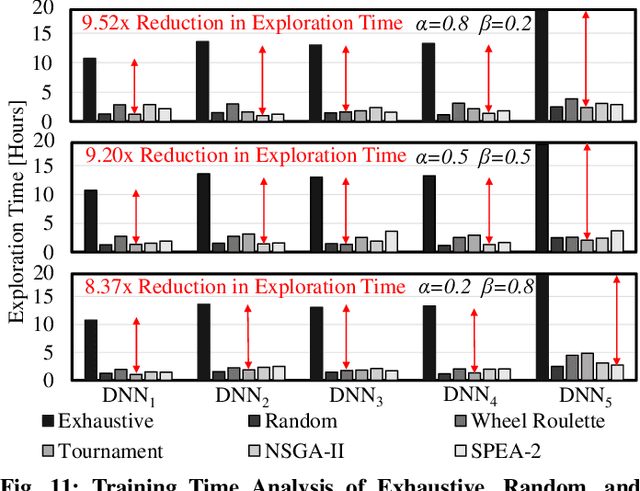
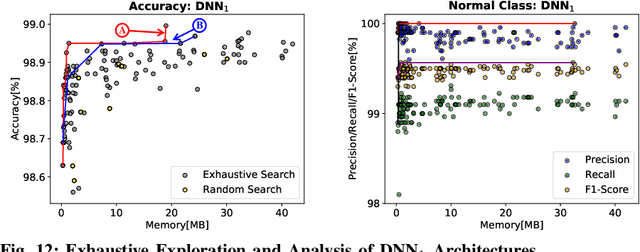
In this work, we propose the BioNetExplorer framework to systematically generate and explore multiple DNN architectures for bio-signal processing in wearables. Our framework adapts key neural architecture parameters to search for an embedded DNN with a low hardware overhead, which can be deployed in wearable edge devices to analyse the bio-signal data and to extract the relevant information, such as arrhythmia and seizure. Our framework also enables hardware-aware DNN architecture search using genetic algorithms by imposing user requirements and hardware constraints (storage, FLOPs, etc.) during the exploration stage, thereby limiting the number of networks explored. Moreover, BioNetExplorer can also be used to search for DNNs based on the user-required output classes; for instance, a user might require a specific output class due to genetic predisposition or a pre-existing heart condition. The use of genetic algorithms reduces the exploration time, on average, by 9x, compared to exhaustive exploration. We are successful in identifying Pareto-optimal designs, which can reduce the storage overhead of the DNN by ~30MB for a quality loss of less than 0.5%. To enable low-cost embedded DNNs, BioNetExplorer also employs different model compression techniques to further reduce the storage overhead of the network by up to 53x for a quality loss of <0.2%.
Continual Learning for Real-World Autonomous Systems: Algorithms, Challenges and Frameworks
May 26, 2021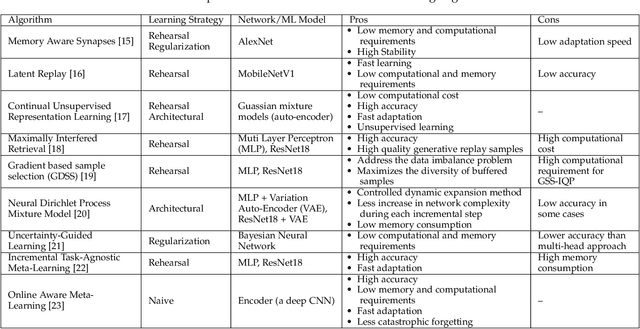
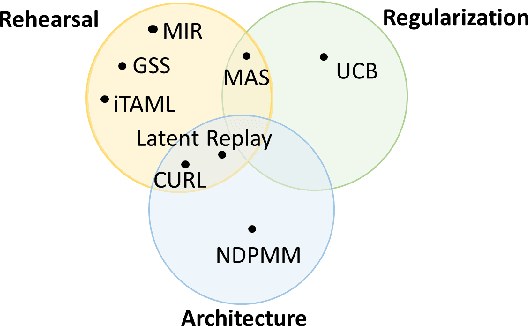


Continual learning is essential for all real-world applications, as frozen pre-trained models cannot effectively deal with non-stationary data distributions. The purpose of this study is to review the state-of-the-art methods that allow continuous learning of computational models over time. We primarily focus on the learning algorithms that perform continuous learning in an online fashion from considerably large (or infinite) sequential data and require substantially low computational and memory resources. We critically analyze the key challenges associated with continual learning for autonomous real-world systems and compare current methods in terms of computations, memory, and network/model complexity. We also briefly describe the implementations of continuous learning algorithms under three main autonomous systems, i.e., self-driving vehicles, unmanned aerial vehicles, and robotics. The learning methods of these autonomous systems and their strengths and limitations are extensively explored in this article.
MacLeR: Machine Learning-based Run-Time Hardware Trojan Detection in Resource-Constrained IoT Edge Devices
Nov 21, 2020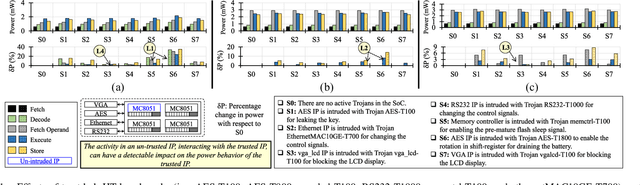
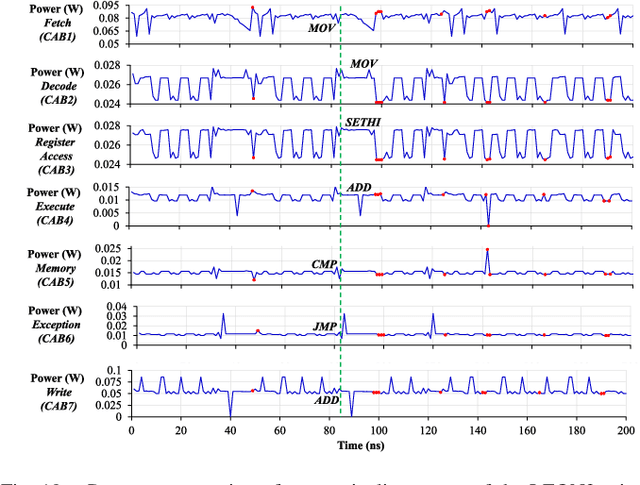
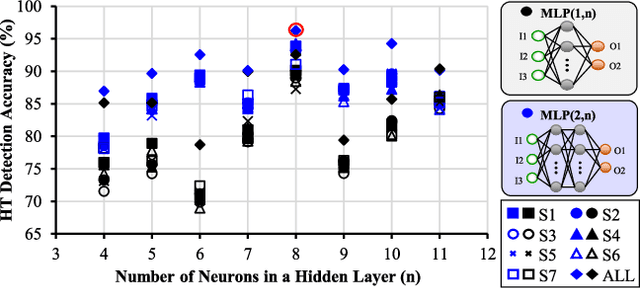
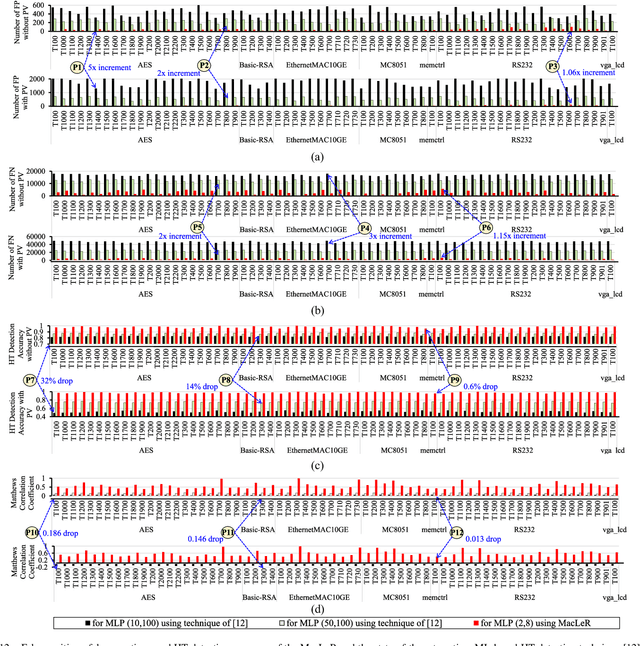
Traditional learning-based approaches for run-time Hardware Trojan detection require complex and expensive on-chip data acquisition frameworks and thus incur high area and power overhead. To address these challenges, we propose to leverage the power correlation between the executing instructions of a microprocessor to establish a machine learning-based run-time Hardware Trojan (HT) detection framework, called MacLeR. To reduce the overhead of data acquisition, we propose a single power-port current acquisition block using current sensors in time-division multiplexing, which increases accuracy while incurring reduced area overhead. We have implemented a practical solution by analyzing multiple HT benchmarks inserted in the RTL of a system-on-chip (SoC) consisting of four LEON3 processors integrated with other IPs like vga_lcd, RSA, AES, Ethernet, and memory controllers. Our experimental results show that compared to state-of-the-art HT detection techniques, MacLeR achieves 10\% better HT detection accuracy (i.e., 96.256%) while incurring a 7x reduction in area and power overhead (i.e., 0.025% of the area of the SoC and <0.07% of the power of the SoC). In addition, we also analyze the impact of process variation and aging on the extracted power profiles and the HT detection accuracy of MacLeR. Our analysis shows that variations in fine-grained power profiles due to the HTs are significantly higher compared to the variations in fine-grained power profiles caused by the process variations (PV) and aging effects. Moreover, our analysis demonstrates that, on average, the HT detection accuracy drop in MacLeR is less than 1% and 9% when considering only PV and PV with worst-case aging, respectively, which is ~10x less than in the case of the state-of-the-art ML-based HT detection technique.
m2caiSeg: Semantic Segmentation of Laparoscopic Images using Convolutional Neural Networks
Aug 23, 2020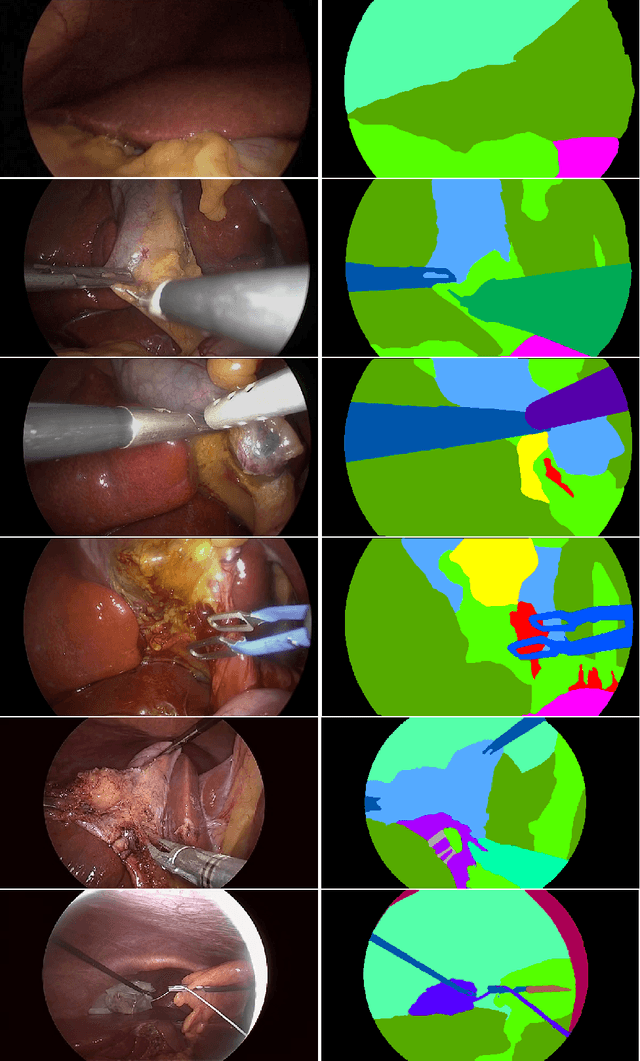
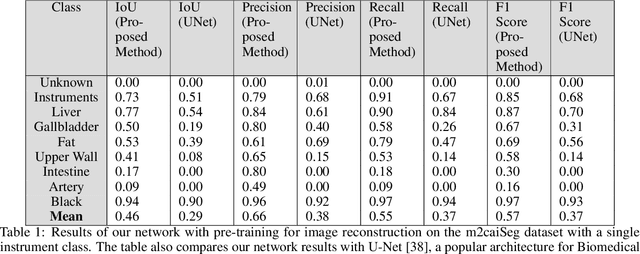
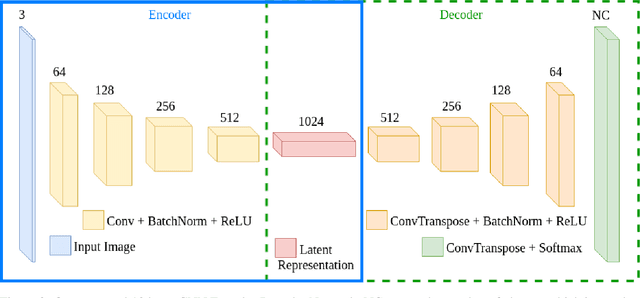
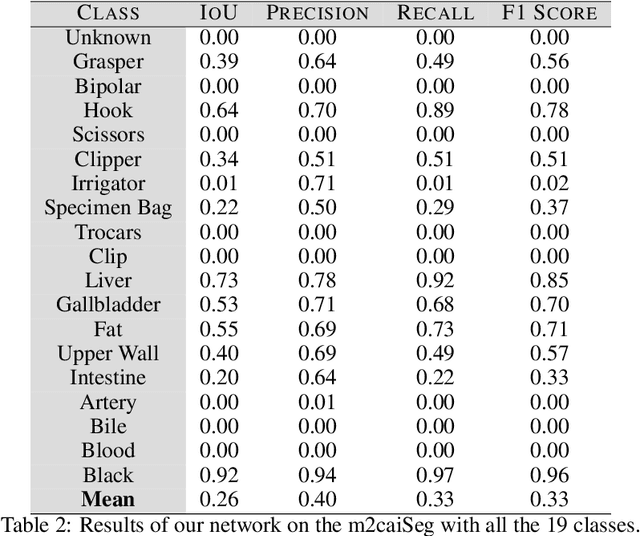
Autonomous surgical procedures, in particular minimal invasive surgeries, are the next frontier for Artificial Intelligence research. However, the existing challenges include precise identification of the human anatomy and the surgical settings, and modeling the environment for training of an autonomous agent. To address the identification of human anatomy and the surgical settings, we propose a deep learning based semantic segmentation algorithm to identify and label the tissues and organs in the endoscopic video feed of the human torso region. We present an annotated dataset, m2caiSeg, created from endoscopic video feeds of real-world surgical procedures. Overall, the data consists of 307 images, each of which is annotated for the organs and different surgical instruments present in the scene. We propose and train a deep convolutional neural network for the semantic segmentation task. To cater for the low quantity of annotated data, we use unsupervised pre-training and data augmentation. The trained model is evaluated on an independent test set of the proposed dataset. We obtained a F1 score of 0.33 while using all the labeled categories for the semantic segmentation task. Secondly, we labeled all instruments into an 'Instruments' superclass to evaluate the model's performance on discerning the various organs and obtained a F1 score of 0.57. We propose a new dataset and a deep learning method for pixel level identification of various organs and instruments in a endoscopic surgical scene. Surgical scene understanding is one of the first steps towards automating surgical procedures.
FANNet: Formal Analysis of Noise Tolerance, Training Bias and Input Sensitivity in Neural Networks
Dec 03, 2019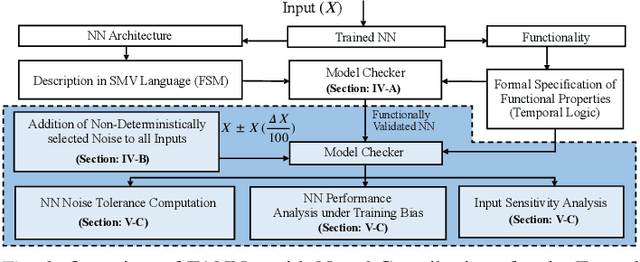
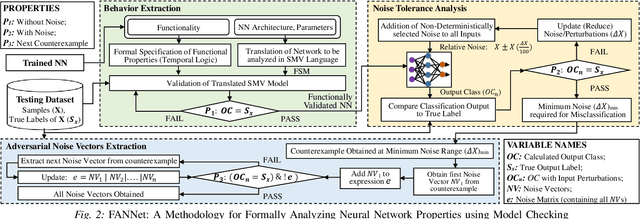
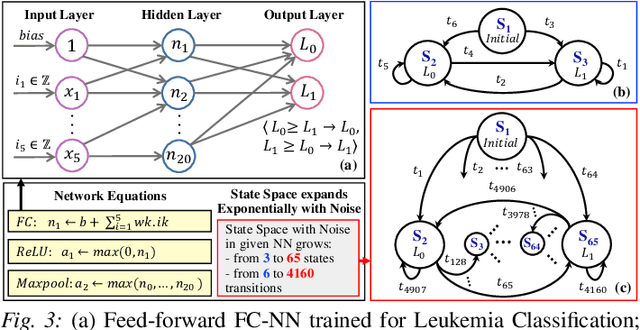
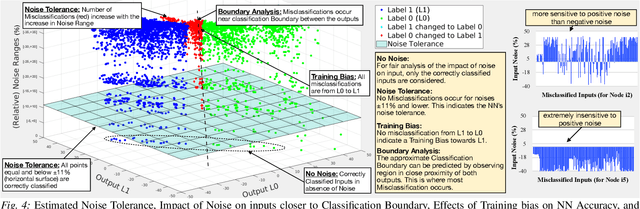
With a constant improvement in the network architectures and training methodologies, Neural Networks (NNs) are increasingly being deployed in real-world Machine Learning systems. However, despite their impressive performance on "known inputs", these NNs can fail absurdly on the "unseen inputs", especially if these real-time inputs deviate from the training dataset distributions, or contain certain types of input noise. This indicates the low noise tolerance of NNs, which is a major reason for the recent increase of adversarial attacks. This is a serious concern, particularly for safety-critical applications, where inaccurate results lead to dire consequences. We propose a novel methodology that leverages model checking for the Formal Analysis of Neural Network (FANNet) under different input noise ranges. Our methodology allows us to rigorously analyze the noise tolerance of NNs, their input node sensitivity, and the effects of training bias on their performance, e.g., in terms of classification accuracy. For evaluation, we use a feed-forward fully-connected NN architecture trained for the Leukemia classification. Our experimental results show $\pm 11\%$ noise tolerance for the given trained network, identify the most sensitive input nodes, and confirm the biasness of the available training dataset.
Formal Modeling of Robotic Cell Injection Systems in Higher-order Logic
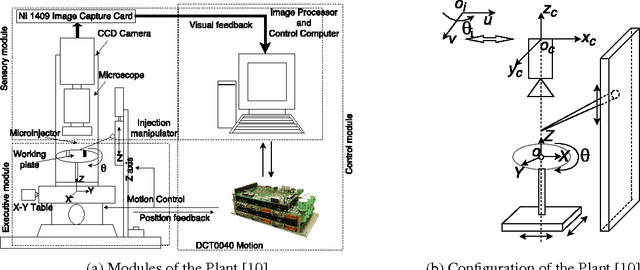
Jul 18, 2018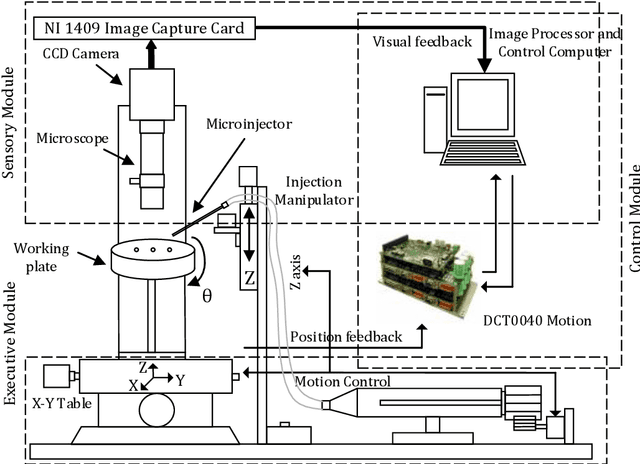
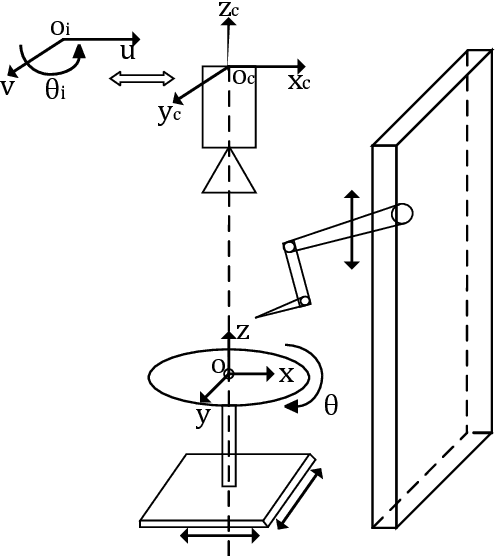
Robotic cell injection is used for automatically delivering substances into a cell and is an integral component of drug development, genetic engineering and many other areas of cell biology. Traditionally, the correctness of functionality of these systems is ascertained using paper-and-pencil proof and computer simulation methods. However, the paper based proofs can be human-error prone and the simulation provides an incomplete analysis due to its sampling based nature and the inability to capture continuous behaviors in computer based models. Model checking has been recently advocated for the analysis of cell injection systems as well. However, it involves the discretization of the differential equations that are used for modeling the dynamics of the system and thus compromises on the completeness of the analysis as well. In this paper, we propose to use higher-order-logic theorem proving for the modeling and analysis of the dynamical behaviour of the robotic cell injection systems. The high expressiveness of the underlying logic allows us to capture the continuous details of the model in their true form. Then, the model can be analyzed using deductive reasoning within the sound core of a proof assistant.
Towards Probabilistic Formal Modeling of Robotic Cell Injection Systems
Mar 20, 2017


Cell injection is a technique in the domain of biological cell micro-manipulation for the delivery of small volumes of samples into the suspended or adherent cells. It has been widely applied in various areas, such as gene injection, in-vitro fertilization (IVF), intracytoplasmic sperm injection (ISCI) and drug development. However, the existing manual and semi-automated cell injection systems require lengthy training and suffer from high probability of contamination and low success rate. In the recently introduced fully automated cell injection systems, the injection force plays a vital role in the success of the process since even a tiny excessive force can destroy the membrane or tissue of the biological cell. Traditionally, the force control algorithms are analyzed using simulation, which is inherently non-exhaustive and incomplete in terms of detecting system failures. Moreover, the uncertainties in the system are generally ignored in the analysis. To overcome these limitations, we present a formal analysis methodology based on probabilistic model checking to analyze a robotic cell injection system utilizing the impedance force control algorithm. The proposed methodology, developed using the PRISM model checker, allowed to find a discrepancy in the algorithm, which was not found by any of the previous analysis using the traditional methods.
* In Proceedings MARS 2017, arXiv:1703.05812