 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBioNetExplorer: Architecture-Space Exploration of Bio-Signal Processing Deep Neural Networks for Wearables
Sep 07, 2021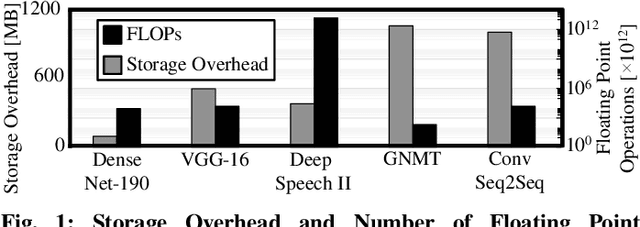
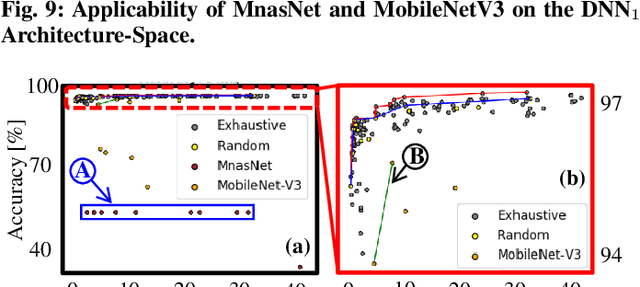
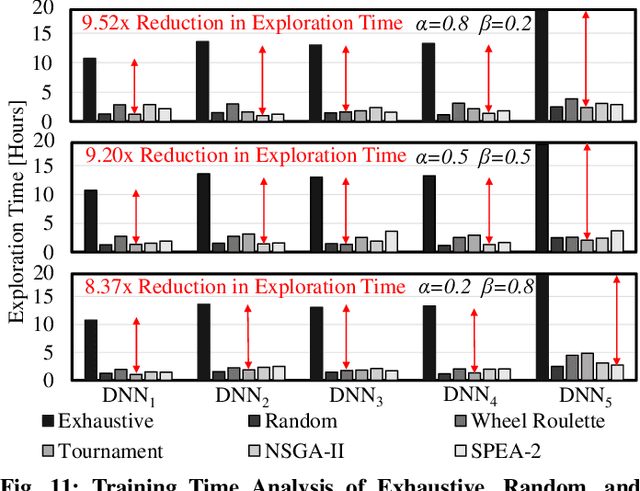
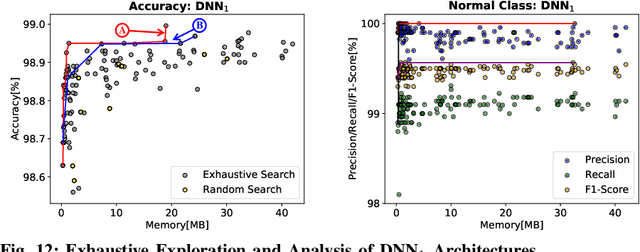
In this work, we propose the BioNetExplorer framework to systematically generate and explore multiple DNN architectures for bio-signal processing in wearables. Our framework adapts key neural architecture parameters to search for an embedded DNN with a low hardware overhead, which can be deployed in wearable edge devices to analyse the bio-signal data and to extract the relevant information, such as arrhythmia and seizure. Our framework also enables hardware-aware DNN architecture search using genetic algorithms by imposing user requirements and hardware constraints (storage, FLOPs, etc.) during the exploration stage, thereby limiting the number of networks explored. Moreover, BioNetExplorer can also be used to search for DNNs based on the user-required output classes; for instance, a user might require a specific output class due to genetic predisposition or a pre-existing heart condition. The use of genetic algorithms reduces the exploration time, on average, by 9x, compared to exhaustive exploration. We are successful in identifying Pareto-optimal designs, which can reduce the storage overhead of the DNN by ~30MB for a quality loss of less than 0.5%. To enable low-cost embedded DNNs, BioNetExplorer also employs different model compression techniques to further reduce the storage overhead of the network by up to 53x for a quality loss of <0.2%.
MLComp: A Methodology for Machine Learning-based Performance Estimation and Adaptive Selection of Pareto-Optimal Compiler Optimization Sequences
Dec 11, 2020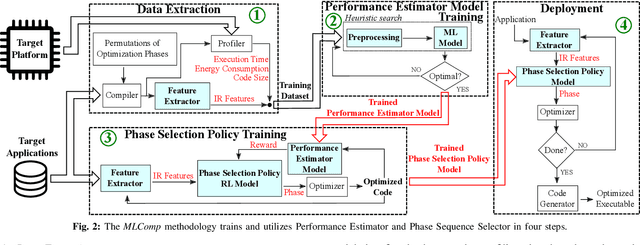
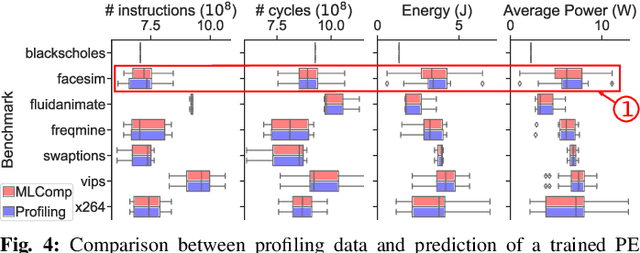
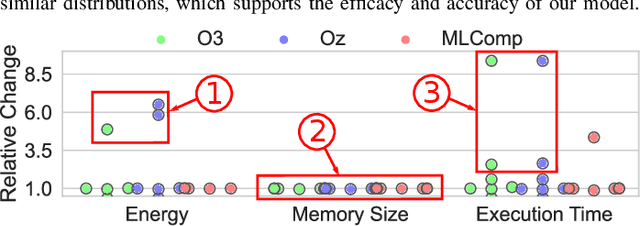
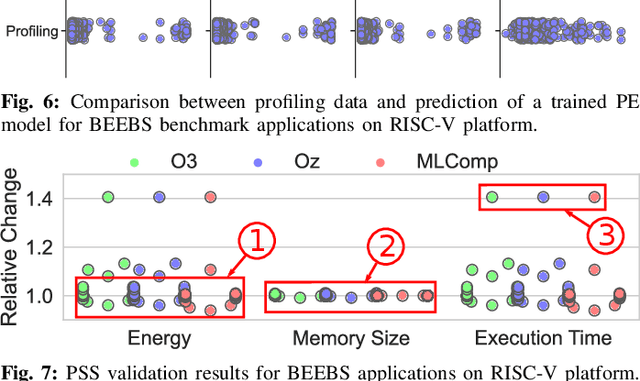
Embedded systems have proliferated in various consumer and industrial applications with the evolution of Cyber-Physical Systems and the Internet of Things. These systems are subjected to stringent constraints so that embedded software must be optimized for multiple objectives simultaneously, namely reduced energy consumption, execution time, and code size. Compilers offer optimization phases to improve these metrics. However, proper selection and ordering of them depends on multiple factors and typically requires expert knowledge. State-of-the-art optimizers facilitate different platforms and applications case by case, and they are limited by optimizing one metric at a time, as well as requiring a time-consuming adaptation for different targets through dynamic profiling. To address these problems, we propose the novel MLComp methodology, in which optimization phases are sequenced by a Reinforcement Learning-based policy. Training of the policy is supported by Machine Learning-based analytical models for quick performance estimation, thereby drastically reducing the time spent for dynamic profiling. In our framework, different Machine Learning models are automatically tested to choose the best-fitting one. The trained Performance Estimator model is leveraged to efficiently devise Reinforcement Learning-based multi-objective policies for creating quasi-optimal phase sequences. Compared to state-of-the-art estimation models, our Performance Estimator model achieves lower relative error (<2%) with up to 50x faster training time over multiple platforms and application domains. Our Phase Selection Policy improves execution time and energy consumption of a given code by up to 12% and 6%, respectively. The Performance Estimator and the Phase Selection Policy can be trained efficiently for any target platform and application domain.
RED-Attack: Resource Efficient Decision based Attack for Machine Learning
Jan 30, 2019

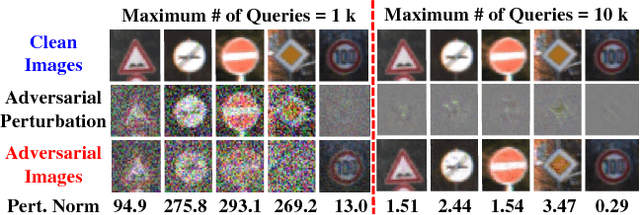
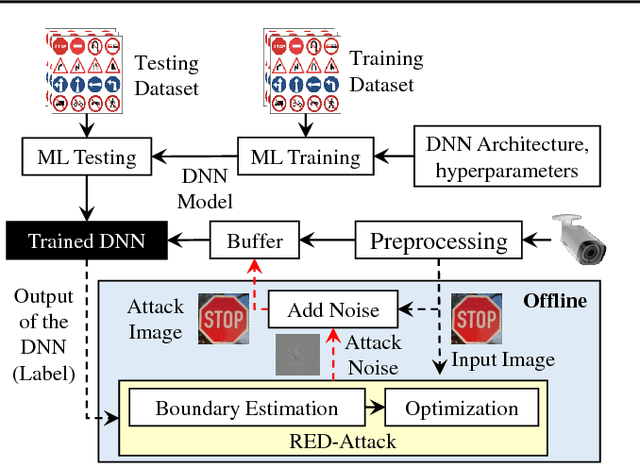
Due to data dependency and model leakage properties, Deep Neural Networks (DNNs) exhibit several security vulnerabilities. Several security attacks exploited them but most of them require the output probability vector. These attacks can be mitigated by concealing the output probability vector. To address this limitation, decision-based attacks have been proposed which can estimate the model but they require several thousand queries to generate a single untargeted attack image. However, in real-time attacks, resources and attack time are very crucial parameters. Therefore, in resource-constrained systems, e.g., autonomous vehicles where an untargeted attack can have a catastrophic effect, these attacks may not work efficiently. To address this limitation, we propose a resource efficient decision-based methodology which generates the imperceptible attack, i.e., the RED-Attack, for a given black-box model. The proposed methodology follows two main steps to generate the imperceptible attack, i.e., classification boundary estimation and adversarial noise optimization. Firstly, we propose a half-interval search-based algorithm for estimating a sample on the classification boundary using a target image and a randomly selected image from another class. Secondly, we propose an optimization algorithm which first, introduces a small perturbation in some randomly selected pixels of the estimated sample. Then to ensure imperceptibility, it optimizes the distance between the perturbed and target samples. For illustration, we evaluate it for CFAR-10 and German Traffic Sign Recognition (GTSR) using state-of-the-art networks.
Security for Machine Learning-based Systems: Attacks and Challenges during Training and Inference
Nov 05, 2018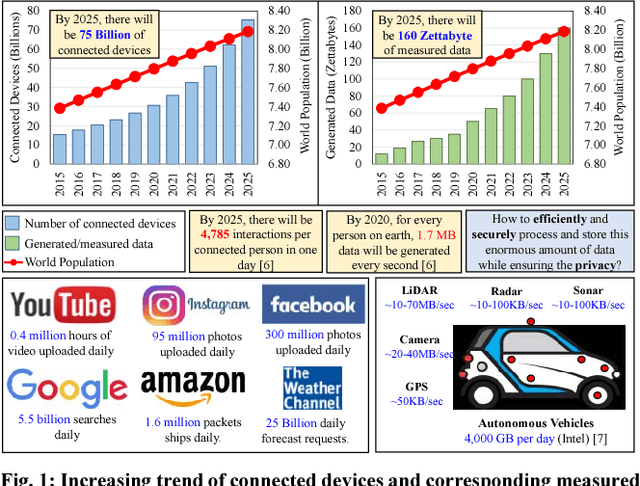
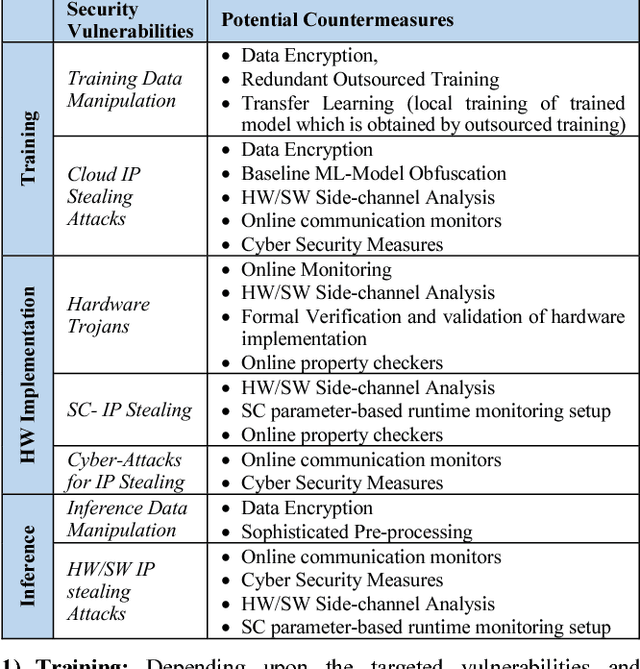
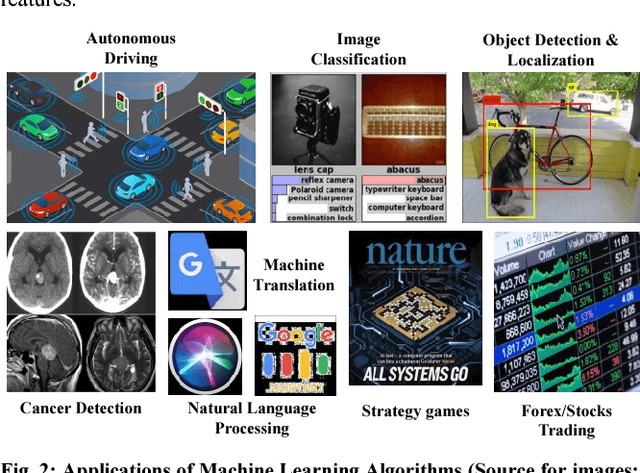
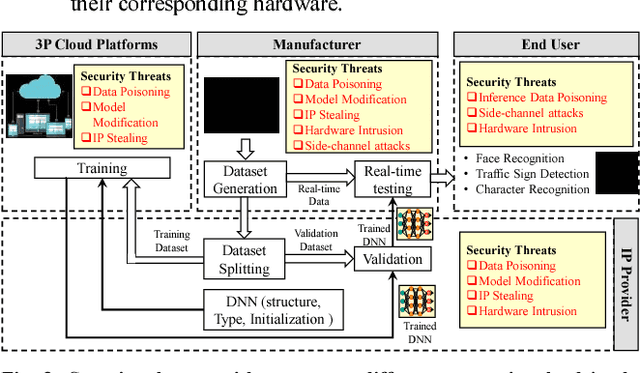
The exponential increase in dependencies between the cyber and physical world leads to an enormous amount of data which must be efficiently processed and stored. Therefore, computing paradigms are evolving towards machine learning (ML)-based systems because of their ability to efficiently and accurately process the enormous amount of data. Although ML-based solutions address the efficient computing requirements of big data, they introduce (new) security vulnerabilities into the systems, which cannot be addressed by traditional monitoring-based security measures. Therefore, this paper first presents a brief overview of various security threats in machine learning, their respective threat models and associated research challenges to develop robust security measures. To illustrate the security vulnerabilities of ML during training, inferencing and hardware implementation, we demonstrate some key security threats on ML using LeNet and VGGNet for MNIST and German Traffic Sign Recognition Benchmarks (GTSRB), respectively. Moreover, based on the security analysis of ML-training, we also propose an attack that has a very less impact on the inference accuracy. Towards the end, we highlight the associated research challenges in developing security measures and provide a brief overview of the techniques used to mitigate such security threats.
FAdeML: Understanding the Impact of Pre-Processing Noise Filtering on Adversarial Machine Learning
Nov 04, 2018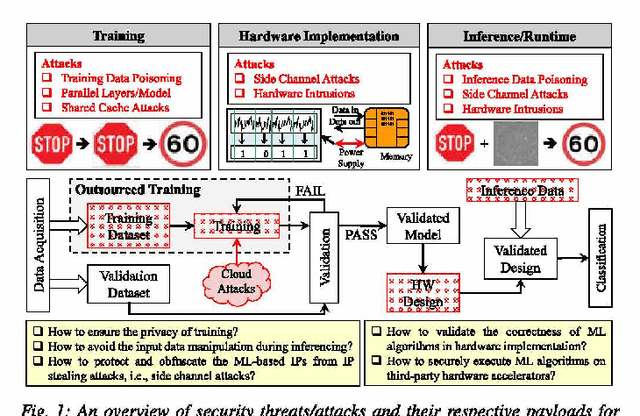
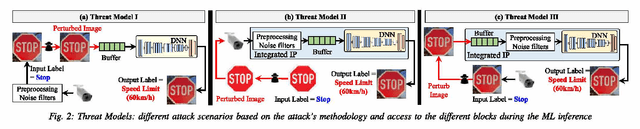
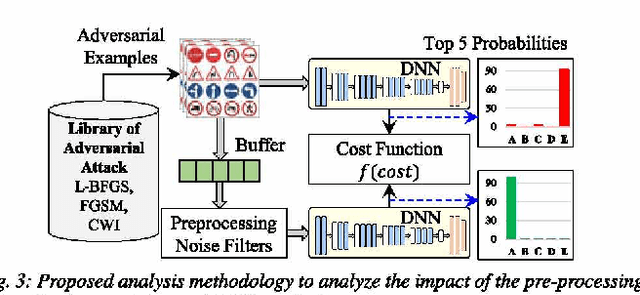
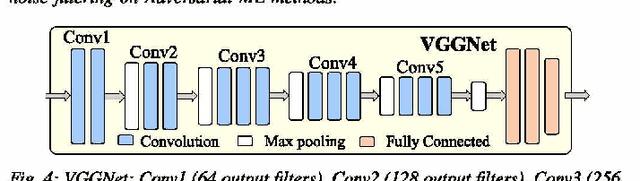
Deep neural networks (DNN)-based machine learning (ML) algorithms have recently emerged as the leading ML paradigm particularly for the task of classification due to their superior capability of learning efficiently from large datasets. The discovery of a number of well-known attacks such as dataset poisoning, adversarial examples, and network manipulation (through the addition of malicious nodes) has, however, put the spotlight squarely on the lack of security in DNN-based ML systems. In particular, malicious actors can use these well-known attacks to cause random/targeted misclassification, or cause a change in the prediction confidence, by only slightly but systematically manipulating the environmental parameters, inference data, or the data acquisition block. Most of the prior adversarial attacks have, however, not accounted for the pre-processing noise filters commonly integrated with the ML-inference module. Our contribution in this work is to show that this is a major omission since these noise filters can render ineffective the majority of the existing attacks, which rely essentially on introducing adversarial noise. Apart from this, we also extend the state of the art by proposing a novel pre-processing noise Filter-aware Adversarial ML attack called FAdeML. To demonstrate the effectiveness of the proposed methodology, we generate an adversarial attack image by exploiting the "VGGNet" DNN trained for the "German Traffic Sign Recognition Benchmarks (GTSRB" dataset, which despite having no visual noise, can cause a classifier to misclassify even in the presence of pre-processing noise filters.
SSCNets: A Selective Sobel Convolution-based Technique to Enhance the Robustness of Deep Neural Networks against Security Attacks
Nov 04, 2018

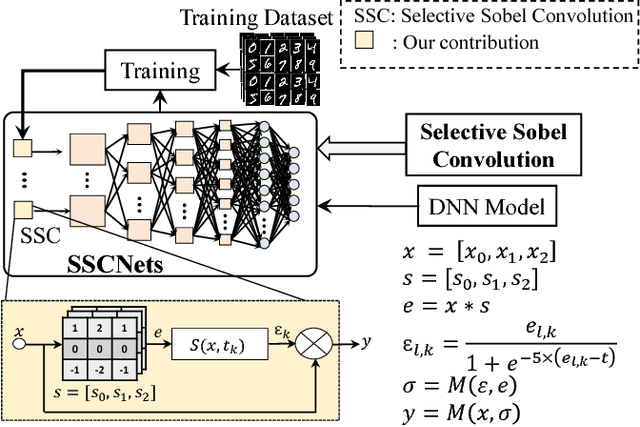
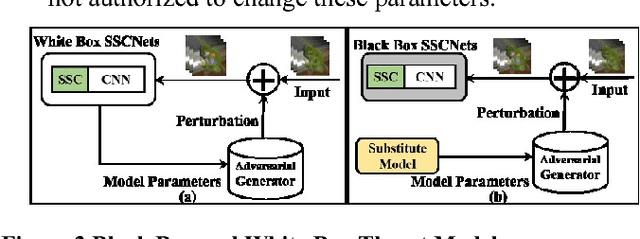
Recent studies have shown that slight perturbations in the input data can significantly affect the robustness of Deep Neural Networks (DNNs), leading to misclassification and confidence reduction. In this paper, we introduce a novel technique based on the Selective Sobel Convolution (SSC) operation in the training loop, that increases the robustness of a given DNN by allowing it to learn important edges in the input in a controlled fashion. This is achieved by introducing a trainable parameter, which acts as a threshold for eliminating the weaker edges. We validate our technique against the attacks of Cleverhans library on Convolutional DNNs against adversarial attacks. Our experimental results on the MNIST and CIFAR10 datasets illustrate that this controlled learning considerably increases the accuracy of the DNNs by 1.53% even when subjected to adversarial attacks.
QuSecNets: Quantization-based Defense Mechanism for Securing Deep Neural Network against Adversarial Attacks
Nov 04, 2018

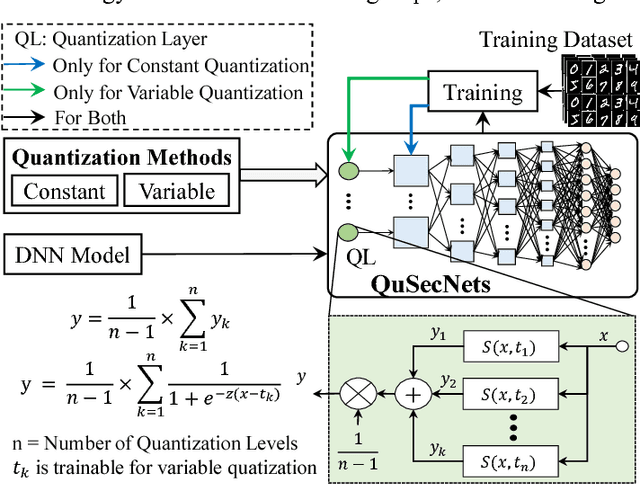

Deep Neural Networks (DNNs) have recently been shown vulnerable to adversarial attacks in which the input examples are perturbed to fool these DNNs towards confidence reduction and (targeted or random) misclassification. In this paper, we demonstrate that how an efficient quantization technique can be leveraged to increase the robustness of a given DNN against adversarial attacks. We present two quantization-based defense mechanisms, namely Constant Quantization (CQ) and Variable Quantization (VQ), applied at the input to increase the robustness of DNNs. In CQ, the intensity of the input pixel is quantized according to the number of quantization levels. While in VQ, the quantization levels are recursively updated during the training phase, thereby providing a stronger defense mechanism. We apply our techniques on the Convolutional Neural Networks (CNNs, a particular type of DNN which is heavily used in vision-based applications) against adversarial attacks from the open-source Cleverhans library. Our experimental results show 1%-5% increase in the adversarial accuracy for MNIST and 0%-2.4% increase in the adversarial accuracy for CIFAR10.
ISA4ML: Training Data-Unaware Imperceptible Security Attacks on Machine Learning Modules of Autonomous Vehicles
Nov 02, 2018
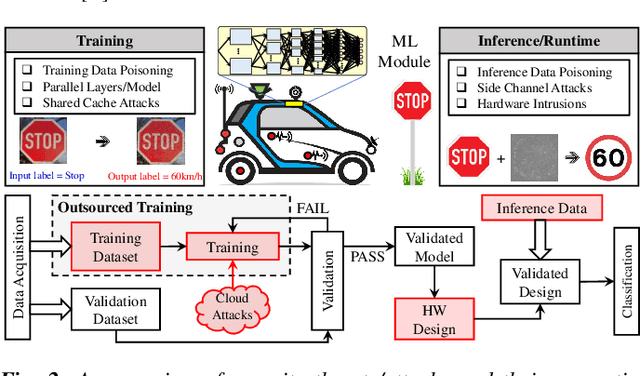


Due to big data analysis ability, machine learning (ML) algorithms are becoming popular for several applications in autonomous vehicles. However, ML algorithms possessinherent security vulnerabilities which increase the demand for robust ML algorithms. Recently, various groups have demonstrated how vulnerabilities in ML can be exploited to perform several security attacks for confidence reduction and random/targeted misclassification, by using the data manipulation techniques. These traditional data manipulation techniques, especially during the training stage, introduce the random visual noise. However, such visual noise can be detected during the attack or testing through noise detection/filtering or human-in-the-loop. In this paper, we propose a novel methodology to automatically generate an "imperceptible attack" by exploiting the back-propagation property of trained deep neural networks (DNNs). Unlike state-of-the-art inference attacks, our methodology does not require any knowledge of the training data set during the attack image generation. To illustrate the effectiveness of the proposed methodology, we present a case study for traffic sign detection in an autonomous driving use case. We deploy the state-of-the-art VGGNet DNN trained for German Traffic Sign Recognition Benchmarks (GTSRB) datasets. Our experimental results show that the generated attacks are imperceptible in both subjective tests (i.e., visual perception) and objective tests (i.e., without any noticeable change in the correlation and structural similarity index) but still performs successful misclassification attacks.
MPNA: A Massively-Parallel Neural Array Accelerator with Dataflow Optimization for Convolutional Neural Networks
Oct 30, 2018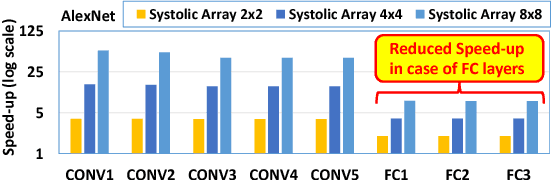


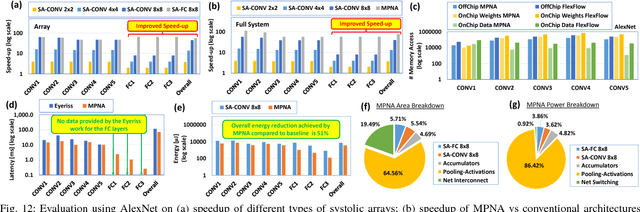
The state-of-the-art accelerators for Convolutional Neural Networks (CNNs) typically focus on accelerating only the convolutional layers, but do not prioritize the fully-connected layers much. Hence, they lack a synergistic optimization of the hardware architecture and diverse dataflows for the complete CNN design, which can provide a higher potential for performance/energy efficiency. Towards this, we propose a novel Massively-Parallel Neural Array (MPNA) accelerator that integrates two heterogeneous systolic arrays and respective highly-optimized dataflow patterns to jointly accelerate both the convolutional (CONV) and the fully-connected (FC) layers. Besides fully-exploiting the available off-chip memory bandwidth, these optimized dataflows enable high data-reuse of all the data types (i.e., weights, input and output activations), and thereby enable our MPNA to achieve high energy savings. We synthesized our MPNA architecture using the ASIC design flow for a 28nm technology, and performed functional and timing validation using multiple real-world complex CNNs. MPNA achieves 149.7GOPS/W at 280MHz and consumes 239mW. Experimental results show that our MPNA architecture provides 1.7x overall performance improvement compared to state-of-the-art accelerator, and 51% energy saving compared to the baseline architecture.