 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeANNETTE: Accurate Neural Network Execution Time Estimation with Stacked Models
May 07, 2021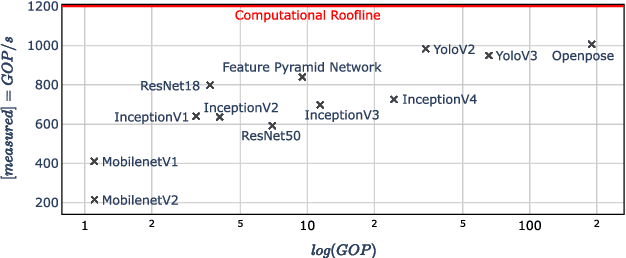
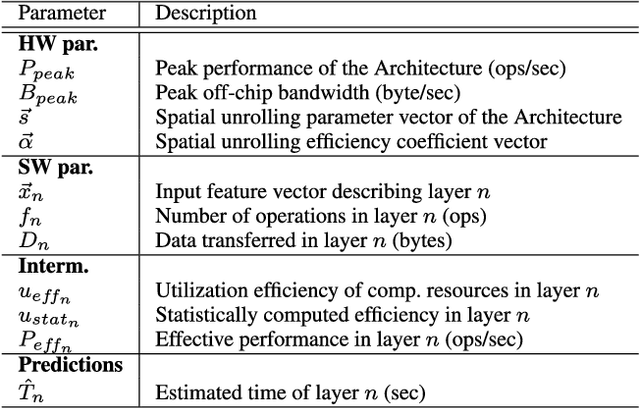
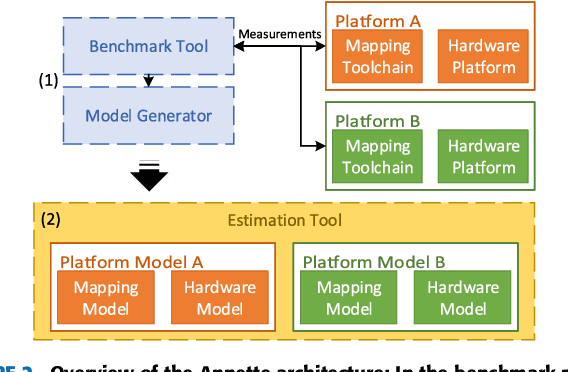

With new accelerator hardware for DNN, the computing power for AI applications has increased rapidly. However, as DNN algorithms become more complex and optimized for specific applications, latency requirements remain challenging, and it is critical to find the optimal points in the design space. To decouple the architectural search from the target hardware, we propose a time estimation framework that allows for modeling the inference latency of DNNs on hardware accelerators based on mapping and layer-wise estimation models. The proposed methodology extracts a set of models from micro-kernel and multi-layer benchmarks and generates a stacked model for mapping and network execution time estimation. We compare estimation accuracy and fidelity of the generated mixed models, statistical models with the roofline model, and a refined roofline model for evaluation. We test the mixed models on the ZCU102 SoC board with DNNDK and Intel Neural Compute Stick 2 on a set of 12 state-of-the-art neural networks. It shows an average estimation error of 3.47% for the DNNDK and 7.44% for the NCS2, outperforming the statistical and analytical layer models for almost all selected networks. For a randomly selected subset of 34 networks of the NASBench dataset, the mixed model reaches fidelity of 0.988 in Spearman's rank correlation coefficient metric. The code of ANNETTE is publicly available at https://github.com/embedded-machine-learning/annette.
MLComp: A Methodology for Machine Learning-based Performance Estimation and Adaptive Selection of Pareto-Optimal Compiler Optimization Sequences
Dec 11, 2020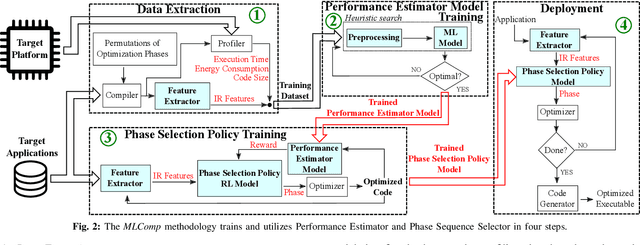
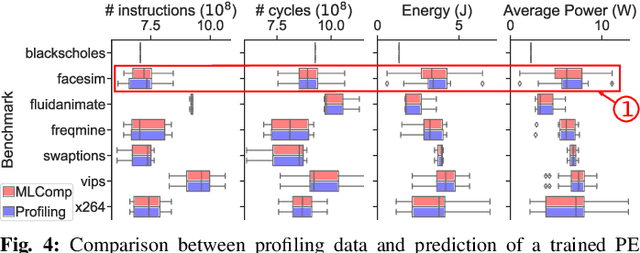
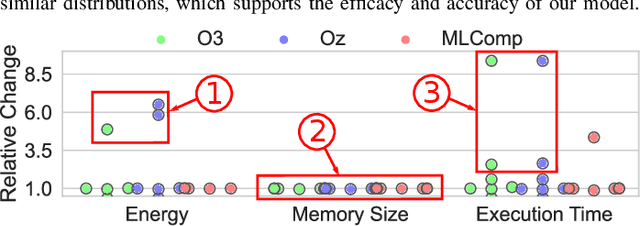
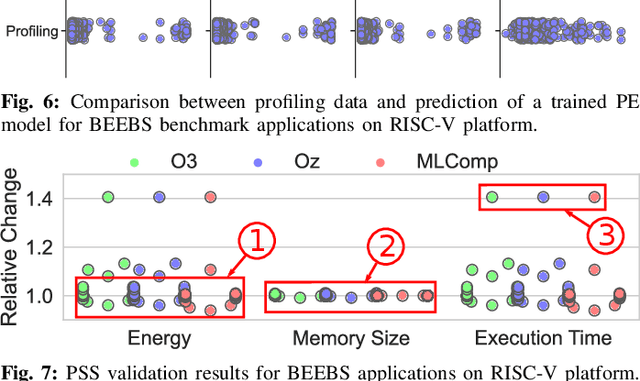
Embedded systems have proliferated in various consumer and industrial applications with the evolution of Cyber-Physical Systems and the Internet of Things. These systems are subjected to stringent constraints so that embedded software must be optimized for multiple objectives simultaneously, namely reduced energy consumption, execution time, and code size. Compilers offer optimization phases to improve these metrics. However, proper selection and ordering of them depends on multiple factors and typically requires expert knowledge. State-of-the-art optimizers facilitate different platforms and applications case by case, and they are limited by optimizing one metric at a time, as well as requiring a time-consuming adaptation for different targets through dynamic profiling. To address these problems, we propose the novel MLComp methodology, in which optimization phases are sequenced by a Reinforcement Learning-based policy. Training of the policy is supported by Machine Learning-based analytical models for quick performance estimation, thereby drastically reducing the time spent for dynamic profiling. In our framework, different Machine Learning models are automatically tested to choose the best-fitting one. The trained Performance Estimator model is leveraged to efficiently devise Reinforcement Learning-based multi-objective policies for creating quasi-optimal phase sequences. Compared to state-of-the-art estimation models, our Performance Estimator model achieves lower relative error (<2%) with up to 50x faster training time over multiple platforms and application domains. Our Phase Selection Policy improves execution time and energy consumption of a given code by up to 12% and 6%, respectively. The Performance Estimator and the Phase Selection Policy can be trained efficiently for any target platform and application domain.