 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeANNETTE: Accurate Neural Network Execution Time Estimation with Stacked Models
May 07, 2021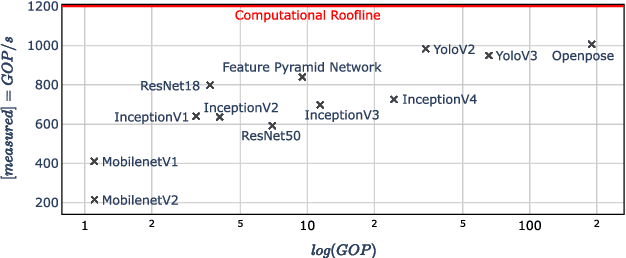
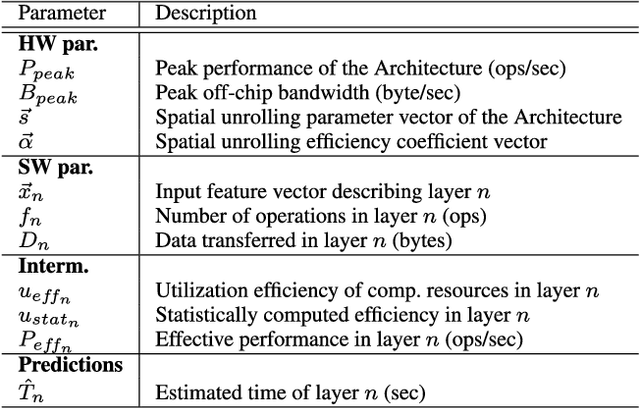
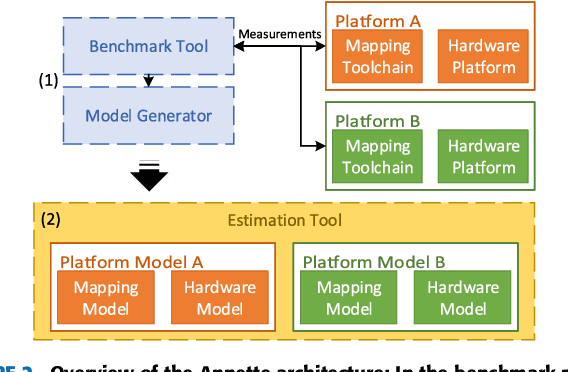

With new accelerator hardware for DNN, the computing power for AI applications has increased rapidly. However, as DNN algorithms become more complex and optimized for specific applications, latency requirements remain challenging, and it is critical to find the optimal points in the design space. To decouple the architectural search from the target hardware, we propose a time estimation framework that allows for modeling the inference latency of DNNs on hardware accelerators based on mapping and layer-wise estimation models. The proposed methodology extracts a set of models from micro-kernel and multi-layer benchmarks and generates a stacked model for mapping and network execution time estimation. We compare estimation accuracy and fidelity of the generated mixed models, statistical models with the roofline model, and a refined roofline model for evaluation. We test the mixed models on the ZCU102 SoC board with DNNDK and Intel Neural Compute Stick 2 on a set of 12 state-of-the-art neural networks. It shows an average estimation error of 3.47% for the DNNDK and 7.44% for the NCS2, outperforming the statistical and analytical layer models for almost all selected networks. For a randomly selected subset of 34 networks of the NASBench dataset, the mixed model reaches fidelity of 0.988 in Spearman's rank correlation coefficient metric. The code of ANNETTE is publicly available at https://github.com/embedded-machine-learning/annette.
Learning on Hardware: A Tutorial on Neural Network Accelerators and Co-Processors
Apr 19, 2021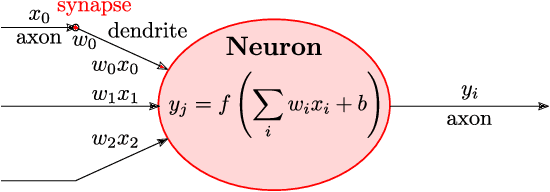
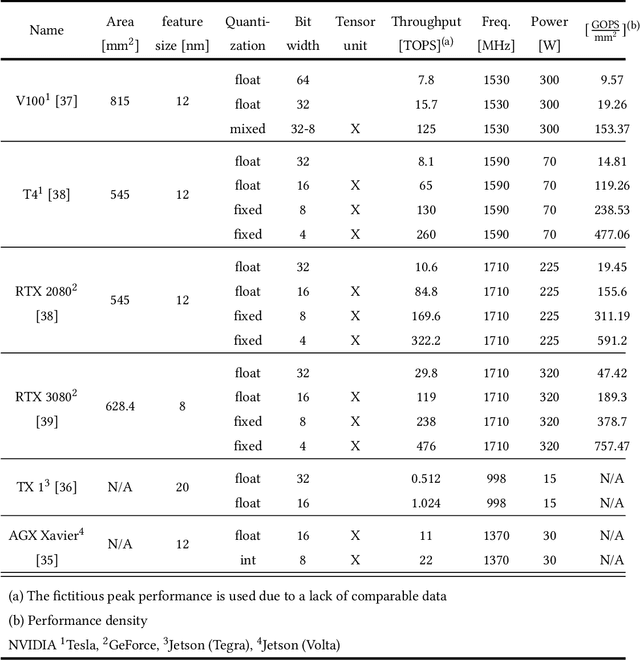
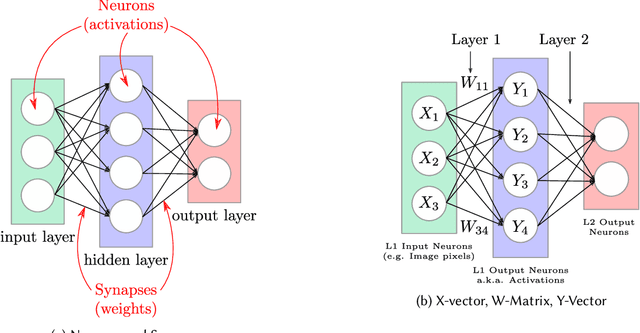
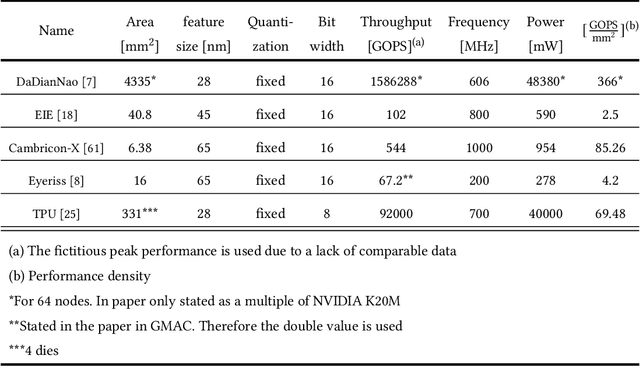
Deep neural networks (DNNs) have the advantage that they can take into account a large number of parameters, which enables them to solve complex tasks. In computer vision and speech recognition, they have a better accuracy than common algorithms, and in some tasks, they boast an even higher accuracy than human experts. With the progress of DNNs in recent years, many other fields of application such as diagnosis of diseases and autonomous driving are taking advantage of them. The trend at DNNs is clear: The network size is growing exponentially, which leads to an exponential increase in computational effort and required memory size. For this reason, optimized hardware accelerators are used to increase the performance of the inference of neuronal networks. However, there are various neural network hardware accelerator platforms, such as graphics processing units (GPUs), application specific integrated circuits (ASICs) and field programmable gate arrays (FPGAs). Each of these platforms offer certain advantages and disadvantages. Also, there are various methods for reducing the computational effort of DNNs, which are differently suitable for each hardware accelerator. In this article an overview of existing neural network hardware accelerators and acceleration methods is given. Their strengths and weaknesses are shown and a recommendation of suitable applications is given. In particular, we focus on acceleration of the inference of convolutional neural networks (CNNs) used for image recognition tasks. Given that there exist many different hardware architectures. FPGA-based implementations are well-suited to show the effect of DNN optimization methods on accuracy and throughput. For this reason, the focus of this work is more on FPGA-based implementations.