 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning on Hardware: A Tutorial on Neural Network Accelerators and Co-Processors
Apr 19, 2021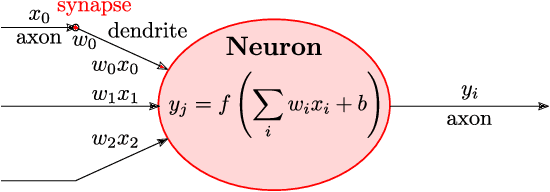
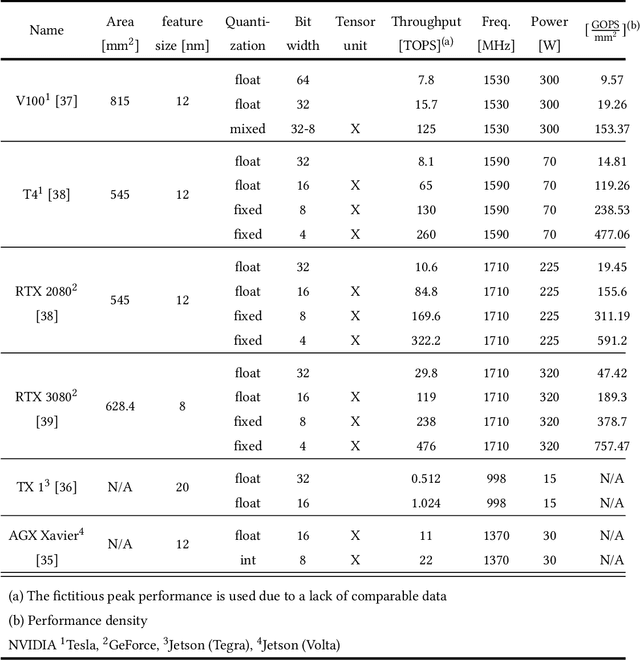
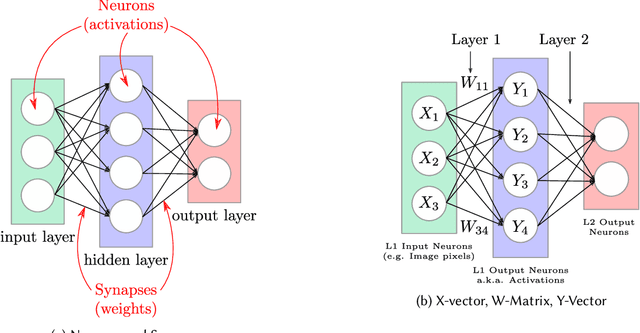
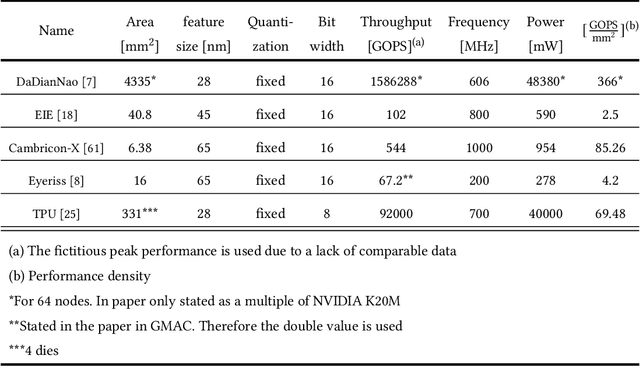
Deep neural networks (DNNs) have the advantage that they can take into account a large number of parameters, which enables them to solve complex tasks. In computer vision and speech recognition, they have a better accuracy than common algorithms, and in some tasks, they boast an even higher accuracy than human experts. With the progress of DNNs in recent years, many other fields of application such as diagnosis of diseases and autonomous driving are taking advantage of them. The trend at DNNs is clear: The network size is growing exponentially, which leads to an exponential increase in computational effort and required memory size. For this reason, optimized hardware accelerators are used to increase the performance of the inference of neuronal networks. However, there are various neural network hardware accelerator platforms, such as graphics processing units (GPUs), application specific integrated circuits (ASICs) and field programmable gate arrays (FPGAs). Each of these platforms offer certain advantages and disadvantages. Also, there are various methods for reducing the computational effort of DNNs, which are differently suitable for each hardware accelerator. In this article an overview of existing neural network hardware accelerators and acceleration methods is given. Their strengths and weaknesses are shown and a recommendation of suitable applications is given. In particular, we focus on acceleration of the inference of convolutional neural networks (CNNs) used for image recognition tasks. Given that there exist many different hardware architectures. FPGA-based implementations are well-suited to show the effect of DNN optimization methods on accuracy and throughput. For this reason, the focus of this work is more on FPGA-based implementations.